索引结构
本文介绍目前两种流行的索引结构,作为 DDIA 第三章前半部分的总结。
1. B-Tree 索引
1.1. 简介
B-tree 是目前最广泛使用的一种索引结构(B+ tree 是 B-tree 的一种优化版)。
可以说,B-tree 是广义上的二分搜索树,只不过每个节点(node)可以有 B 个子节点。
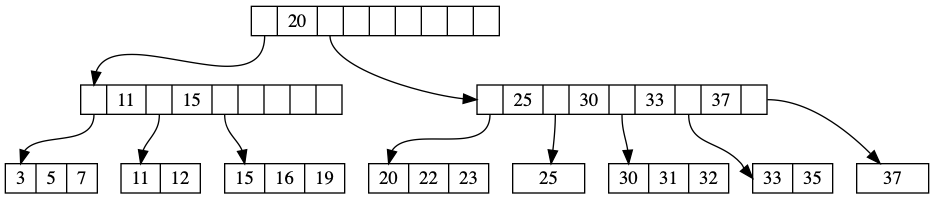
N 个数据通过 B-tree 组织,可以达到 O(logN) 复杂度的 query 速度。
1.2. 存储细节
B-tree 将数据分成固定大小的页,页是内部读写的最小单元。这种设计接近底层硬件,因为磁盘也是按照固定大小的块排列。
通常来说,存储引擎会使用 B-tree 组织数据进行存储(使用主键进行排序),即叶子节点的数据会按照顺序存储在磁盘上(叶子节点使用双向链表连接),这称为聚集索引(Clustered Index)。
如果要更新 B-tree 现有的值,则首先搜索包含该键的叶子页,并将页刷到磁盘。
如果需要插入新键,则需要找到该范围的页,将值写入页中。如果该页没有足够空间来容纳新键,则将其分裂成两个页,并且更新父页,若父页也满,则触发另一个分裂,以此类推。
可以看到,如果每次插入新键都可能触发页分裂的话,则写入效率会非常低,因此通常来说,聚集索引会使用 AutoIncrement 的 ID 作为默认主键。
1.3. 奔溃恢复
由于 B-tree 的每次写入都涉及页的更新操作,并且有时候可能涉及多个页的写操作。如果完成部分写,然后数据库奔溃,则会破坏索引(例如某个页成了孤儿页,没有被引用)。
为了使得数据库能够从奔溃中恢复,通常会实现一个预写日志(write-ahead log, WAL),每次修改 B-tree 之前,需要先更新 WAL,再修改 B-tree 的数据。
当数据库奔溃后恢复时,使用 WAL 将数据库恢复到最近一致的状态。
1.4. 并发控制
原地更新页的另外一个问题是,并发控制问题,通常会使用锁存器(key 级别的锁)来实现。
1.5. 性能优化
- 一些数据库(如 LMDB)不实用覆盖页和维护 WAL,而是使用写时复制方案。在新位置写入修改的页,创建新版本的父页,指向该新位置。这种方法也有利于并发控制。
- 键压缩,即保存键的缩略信息,而不是完整的键,以节省页空间,特别是中间层节点,只需要提供 range 信息。
- 页的布局。理论上,页可以放在磁盘上任意位置,但是这样的话范围查询则需要涉及大量的随机I/O,是非常耗时的操作。因此,许多实现将子叶顺序存储,不过,当 B-tree 变大时,维护这个顺序会很困难。
2. LSM-Tree 索引
2.1. 简介
日志结构合并树(Log-Strutured Merge Tree, LSM-Tree)也是利用键(key)进行排序存储的一种数据结构。
数据存储在一系列的段文件中,称为排序字符串表(Sorted String Table, SSTable)。每个段文件表对应有一个内存哈希索引(可以是稀疏的),其中存储的值为 sstable 里面的文件偏移。
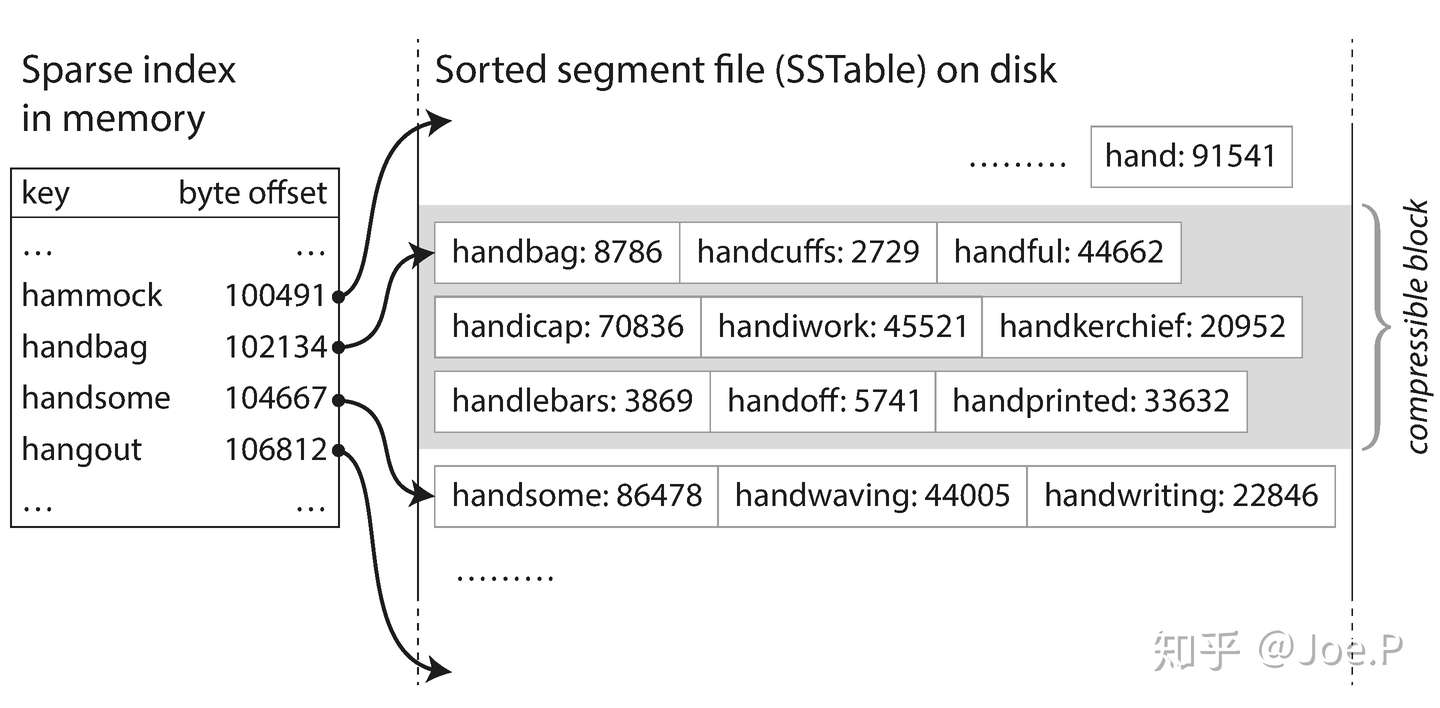
每次查询数据的时候,会从最新的 sstable 开始查找,直到找到所需的 key。
2.2. 原理
- 当写入的时候,先往内存的平衡树数据结构写入
- 当上述内存表大小达到某个阈值的时候,则作为 SSTable 文件写入磁盘。新的 SSTable 成为数据库的最新部分。写入 SSTable 的时候,新的写入则添加到新的内存表实例中。
- 处理读请求时,首先尝试在最新的内存表中查找键,其次是最新的磁盘 SSTable,再次是次新的磁盘 SSTable,以此类推。
- 后台进程周期性地执行合并与压缩过程,以合并多个段文件,并丢弃无效的值(被修改或被删除)。
当然,就像 B-tree 一样,所有存储引擎都需要解决奔溃恢复的问题,LSM-Tree 也可以使用 WAL 日志,每次写入内存表之前,先写入 WAL,。
2.3. 性能优化
- 当查找某个不存在的键的时候,LSM-Tree 可能会很慢,因为需要从最新的 SSTable 回溯到最老的 SSTable。为此,可以使用布隆过滤器来解决。
- 压缩。压缩是 LSM-Tree 的核心问题。压缩算法包含大小分级(Size-tiered compaction strategy, STCS) 以及分层压缩(Level-based compaction strategy, LBCS)。
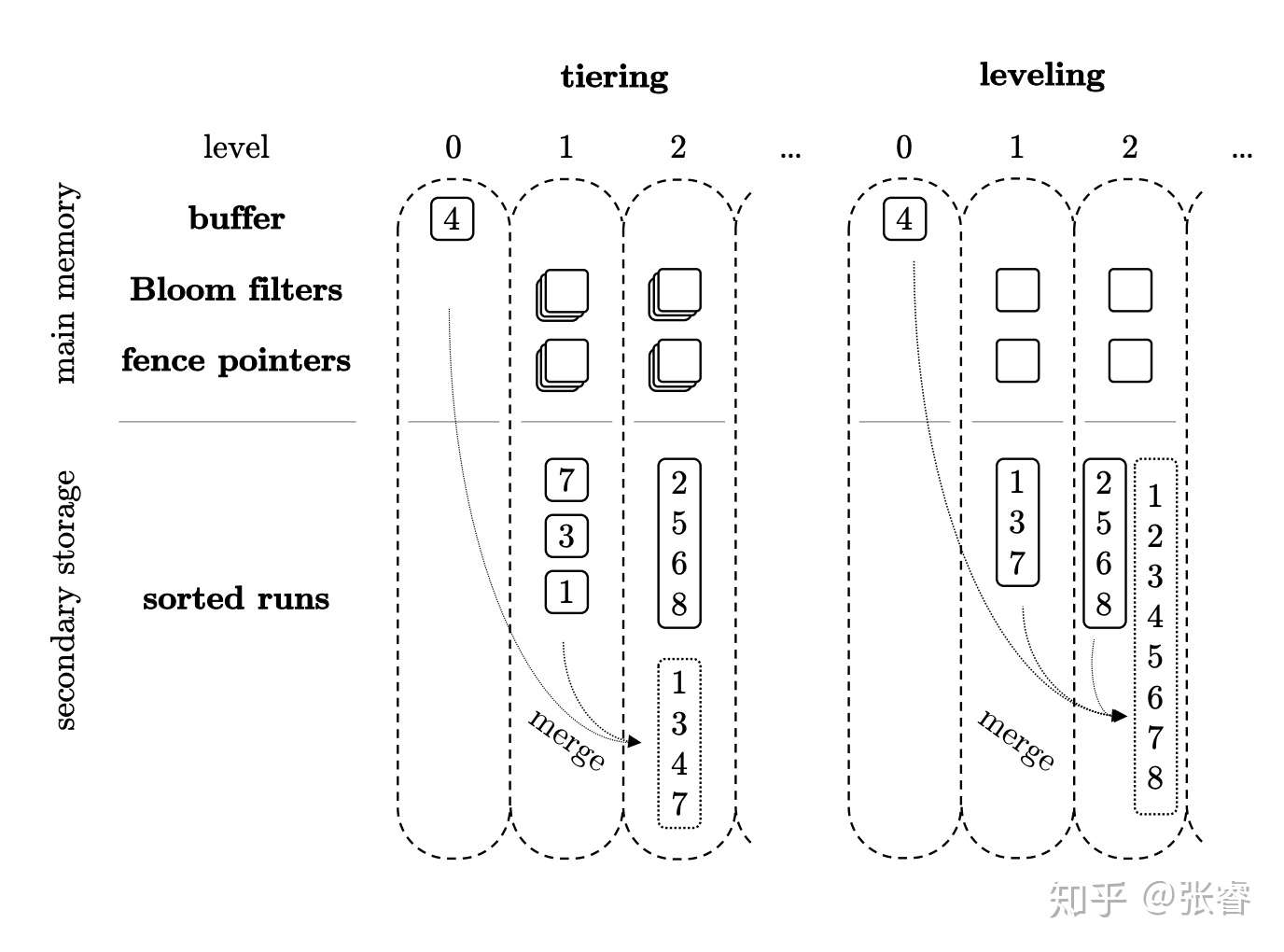
大小分级与分层压缩的对比可见上图。
大小分级中,每个 SSTable 虽然都是 sorted 的,但是当 level0 与 level1 合并 flush 到 level2 中的时候,[1,3,4,7], [2,5,6,8] 并不能组成一个 Run,因为无法直接使用二分搜索。例如,我需要查找 5,那么这两个 SSTable 都在查询范围内。
而分层压缩则保证了这点,新的层中可能包含交叉的键,但是老的层都是不交叉的键。每次新层文件大小达到阈值的时候,会与较老的层中有交集的文件作合并操作,保证每一层都可以直接使用二分搜索进行查询。
3. 对比
3.1. LSM-Tree 的优点
- 写入快。B 树索引必须至少两次写入每一段数据:一次写入预先写入日志,一次写入树页面本身(也许再次分页)。即使在该页面中只有几个字节发生了变化,也需要一次编写整个页面的开销。有些存储引擎甚至会覆盖同一个页面两次,以免在电源故障的情况下导致页面部分更新。
- 碎片少。LSM 树可以被压缩得更好,因此经常比 B 树在磁盘上产生更小的文件。 B 树存储引擎会由于页分裂而留下一些未使用的磁盘空间:当页分裂或某行不能放入现有页面时,页面中的某些空间无法被利用。由于 LSM 树不是面向页面的,并且定期重写 SSTables 以去除碎片,所以它们具有较低的存储开销,特别是当使用分层压缩时。
3.2. LSM-Tree 的缺点
- 压缩阻塞。因为磁盘的带宽是固定的,因此 LSM-Tree 在压缩过程有时会干扰正在进行的读写操作。
- 压缩速率。当写入吞吐量很大的时候,很可能来不及压缩 SSTable 导致段文件增大到磁盘空间不足。因此需要额外的监控发现这些情况,以及配置合适的压缩间隔。
- 事务。B-tree 中,事务的隔离可以直接通过键范围的锁来实现。而 LSM-Tree 可能需要通过文件范围的锁来解决。
Reference
- leveldb 的实现:https://github.com/google/leveldb/blob/master/doc/impl.md
- 数据结构性能对比:https://tikv.org/deep-dive/key-value-engine/b-tree-vs-lsm/
- leveldb 架构:https://zhuanlan.zhihu.com/p/38810568
- DDIA 笔记:https://juejin.im/post/6844904113122050055