第五章 优化程序性能
0. 优化之路咋走?
首先需要知道优化之路可以怎么走,下面摘自 CMU 的公开课 slides。主要有两方面因素:
代码风格:良好的数据结构与算法思想,循环、变量等人为因素; 编译器与操作系统:了解编译器优化,从汇编、profile 等角度分析性能瓶颈,了解操作系统层面因素;

1. 量化程序性能
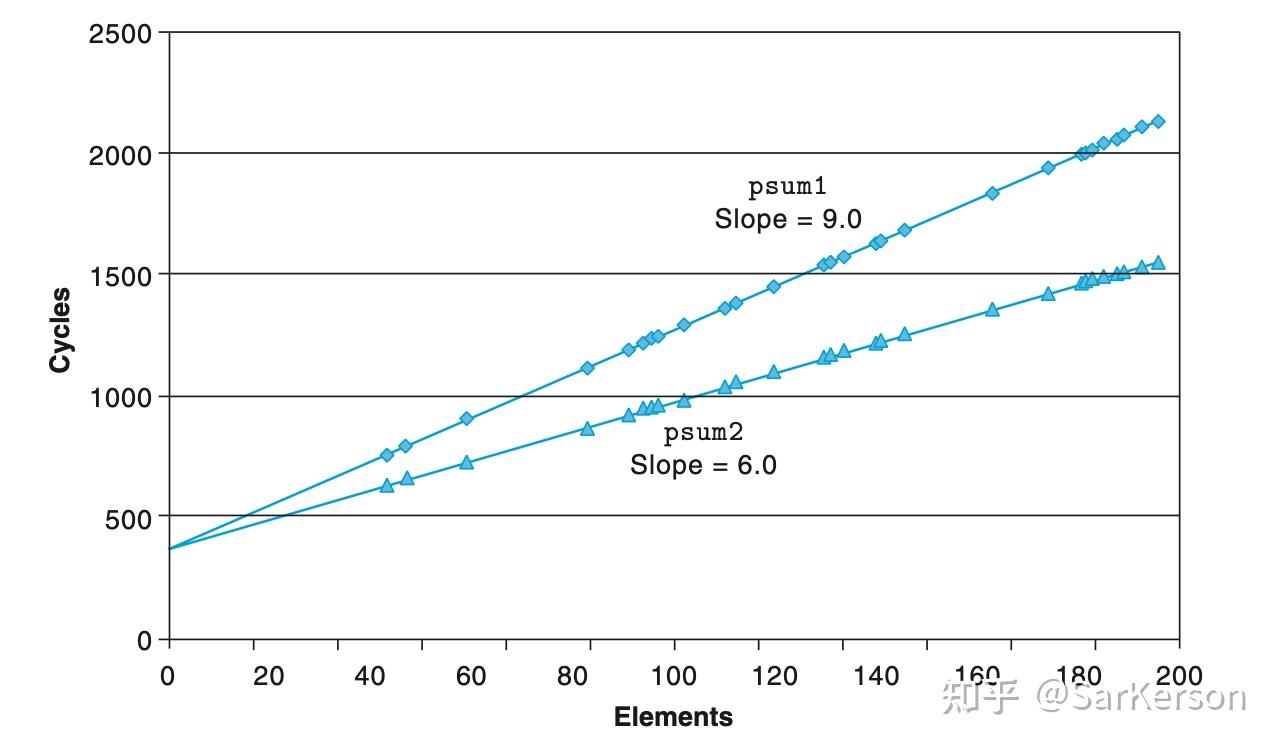
使用 CPE(Cycles Per Element)来量化程序性能。其表示每个循环执行了多少个时钟周期(可以预估执行了多少个指令)。
对于一个“4GHz”的处理器而言,时钟运行的频率是每秒 4x10^9 个周期,即一个时钟周期 = 0.25ns。
例如,将程序的循环的 CPE 从 9 优化到 6,表示我们将程序中的每个循环,从消耗 9 个时钟周期,优化到 6 个时钟周期,节省了 3 个时钟周期。

CPE 其实就是右图中的斜率,我们的优化目标是尽可能让直线躺平。
为什么要用 CPE?
其实就是比较直观,而且容易跟运算单元的速度进行关联,可以很方便地估计出优化的幅度。
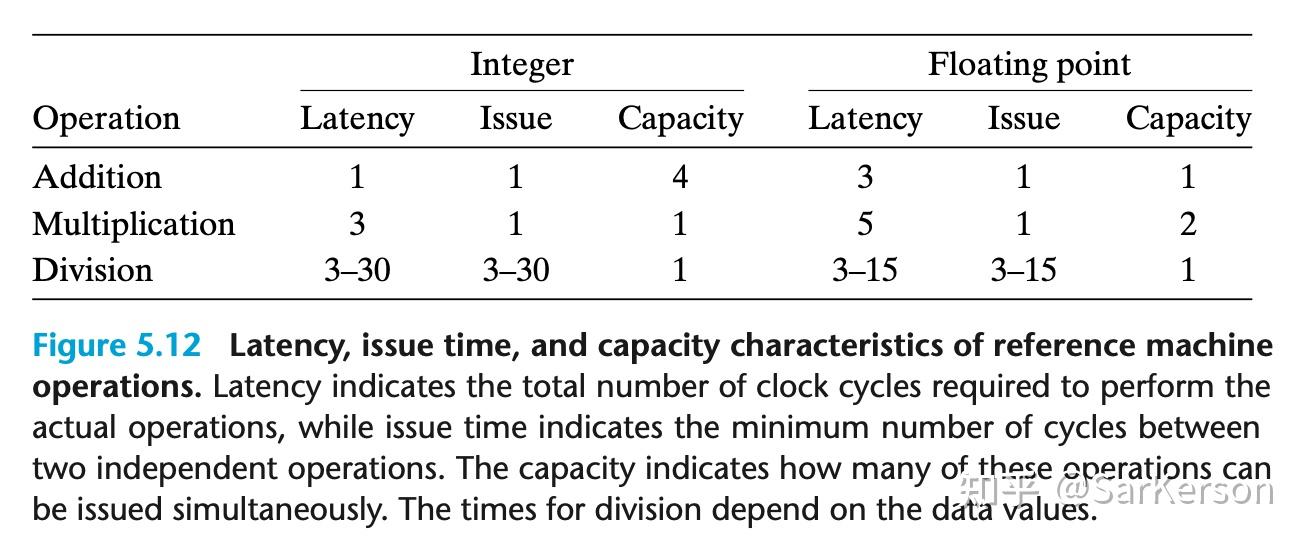
下面是常见操作的CPE:
下面是对 capacity、latency、issue 的图形化描述:
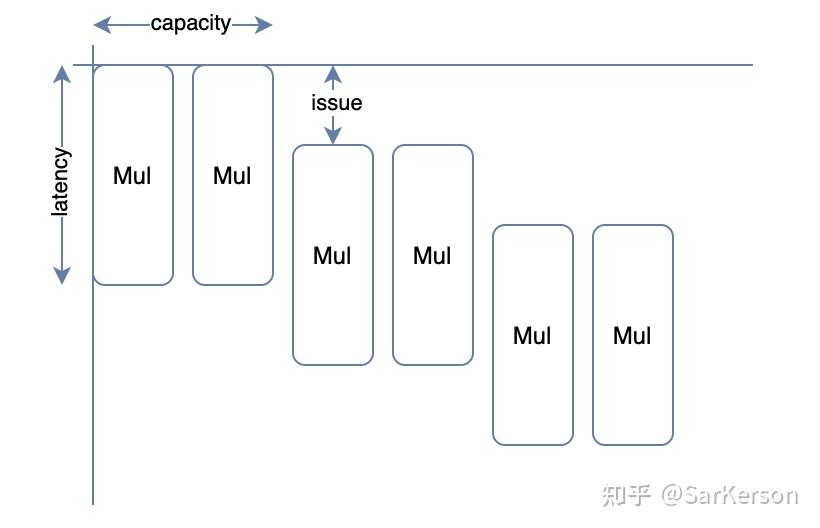
- capacity:描述处理器单位时间能过处理的指令数量
- latency:描述单位指令执行时间
- issue:描述相同指令之间的执行间隔(可以翻译为发射时间)
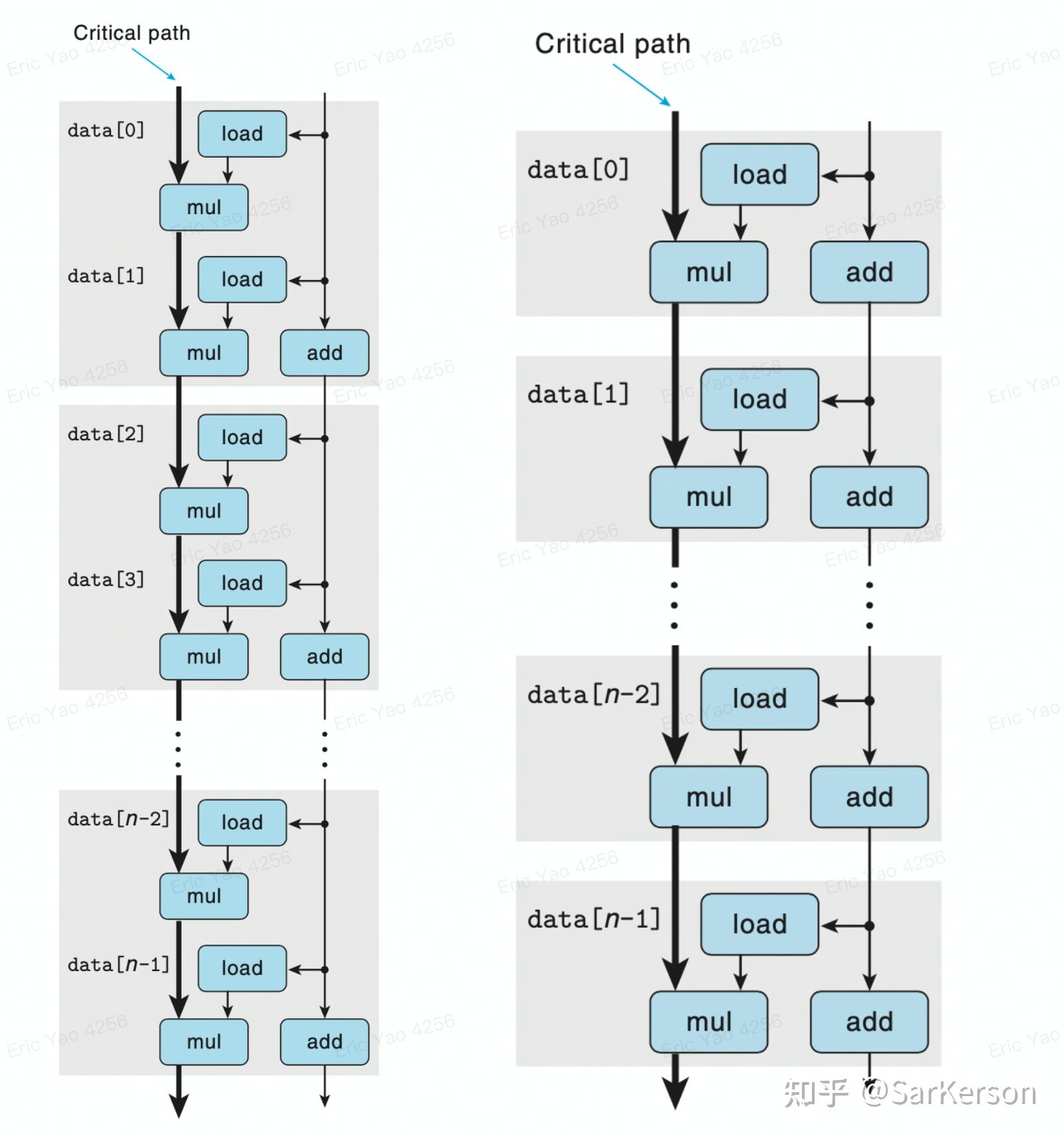
通过各个模块的 CPE,快速估算出优化的幅度:
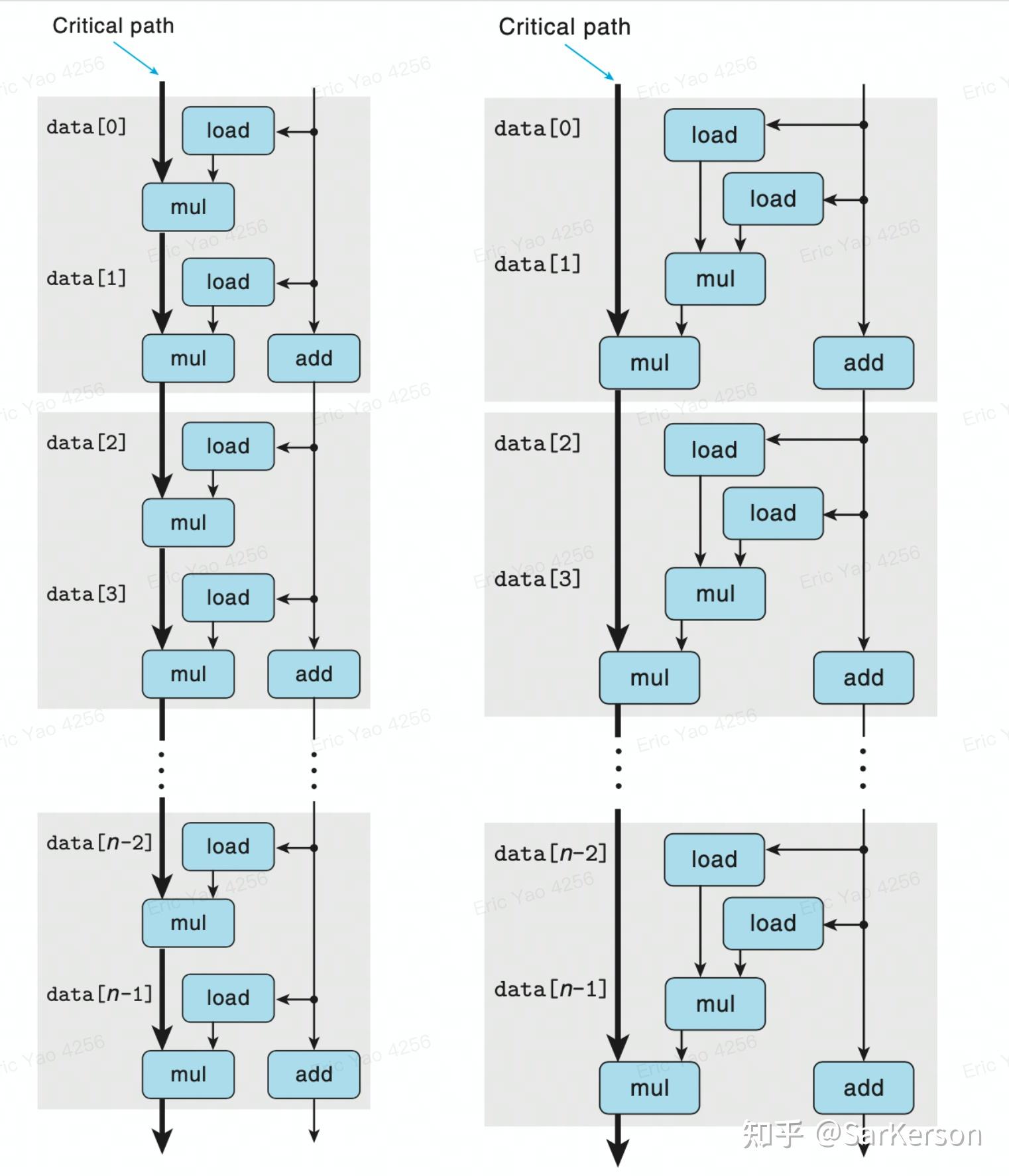
对于某台机器 load=2, mul=3, add=1
- 左图:关键路径消耗 (load+mul)n=(2+3)n=5n 个时钟周期
- 右图:关键路径消耗 (load+mul+mul)n/2=(2+3+3)n/2=4n 个时钟周期,速度提高 20%
当然,这个 CPE 在实际工作中计算出来是比较麻烦的,但是对于了解常见汇编指令的速度还是有一定帮助。
2. 编译器优化的能力和局限性
编译器能做啥?
这里介绍几个编译器能做的优化。
优化计算表达式:将复杂表达式转换为简单表达式,例如用位操作来代替乘法;
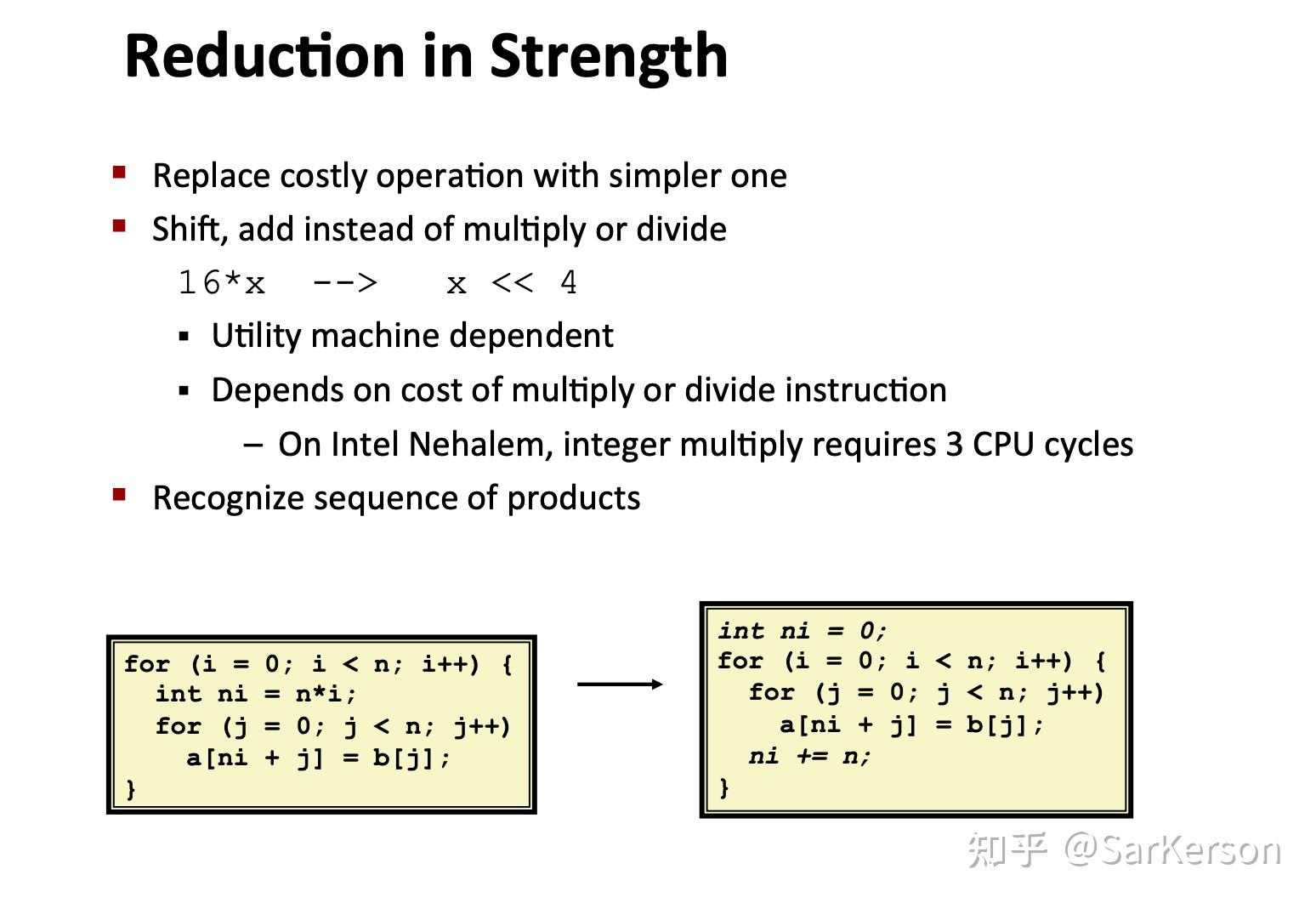
使用公共变量:使用临时变量等方式来避免重复几计算;

编译器挫在哪?
挫一:处理函数调用

为什么编译器不能够发现,并将 strlen 提取到循环外?

- 函数可能有副作用,例如修改某个全局变量
- 函数不一定是幂等的,例如依赖某个全局变量
编译器倾向于把函数调用当作黑盒,因为无法知道其副作用,所以不会对此进行优化。 —— 鲁迅
挫二:内存别名引用


编译器不能优化这点吗?
看上去编译器似乎能够优化这点,但是编译器会假设两个指针地址可能相同,因此必须非常谨慎,躺平不动。

程序员要养成使用局部变量的习惯,显式地告诉编译器,这里没有内存别名。 —— 鲁迅
3. 现代微处理器
到目前为止,我们提及到的优化技巧,都不依赖于目标机器的任何特性。我们目前的优化,只是简单的降低了过程调用的开销、避开了编译器的挫。如果要进一步进行优化,必须考虑利用现代微处理器的优化,也就是处理器用来执行指令的底层系统设计。
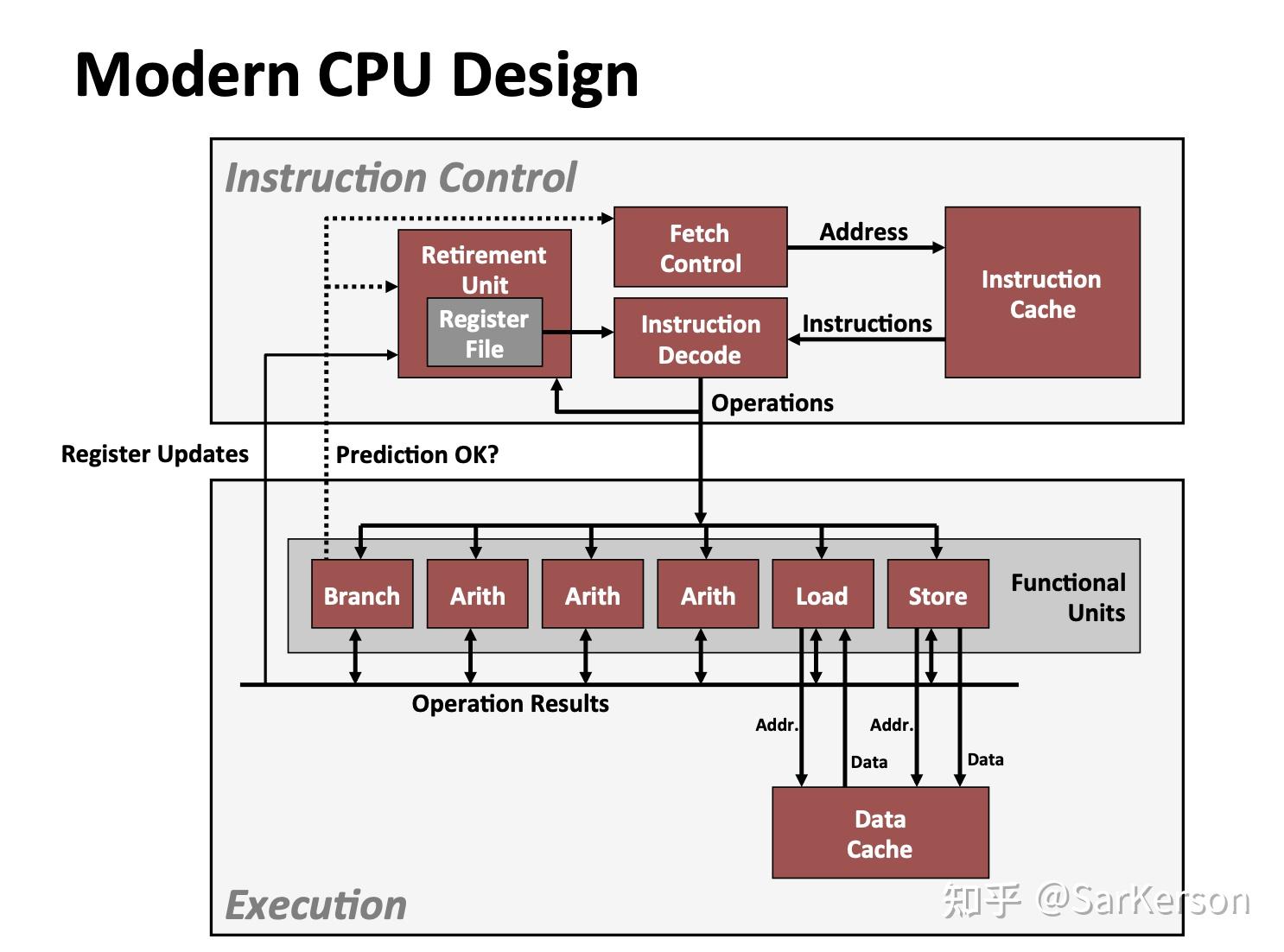
这样的处理器,在工业界称为超标量(Superscalar),即每个时钟周期可以执行多个指令,且是乱序执行。整个处理器分为两大部分,指令控制单元(ICU)和执行单元(EU)。
- 指令控制单元:从高速缓存中取指、译码,生成一组 low level 的基本操作;
- 执行单元:执行上述基本操作;包括多个功能单元,比如 arith(算术运算)、load(内存读)、store(内存写)等等,分别负责各自独立的计算和存取内存操作。
当程序遇到分支的时候,程序可能有两个前进的方向。现代处理器使用了分支预测技术(Branch Prediction),会猜测是否选择分支,且会预测分支跳转的目标地址。然后使用投机执行(Speculative Execution)技术对目标分支跳转到的指令进行取指和译码(甚至在分支预测之前就开始投机执行)。如果之后确定分支预测错误,则会将寄存器状态重置为分支点的状态,并开始取出和执行另一个分支上的指令。所以可以看到,分支预测错误会导致很大的性能开销。
4. 让处理器助你一臂之力吧!
循环展开

优化前后的关键路径对比,可以看到每 2 个 Element,节省了一个 load 操作,速度提高 20%:
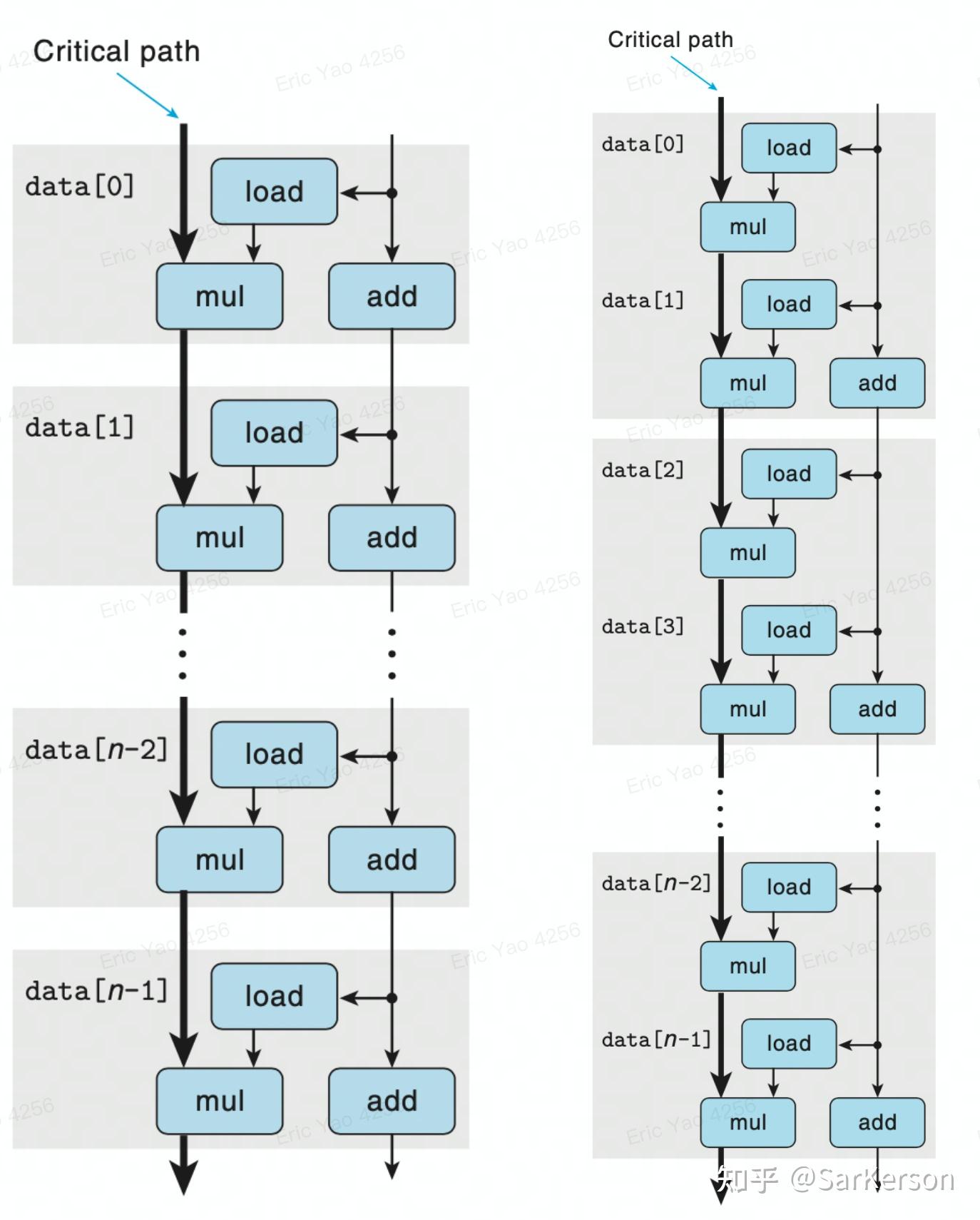
提高并行性
分治法

优化前后的关键路径对比,可以看到每个 2 个 Element,节省了 mul 操作,速度提高 1x 多:
- 左边关键路径:load+2*mul=8
- 右边关键路径:load+mul=5
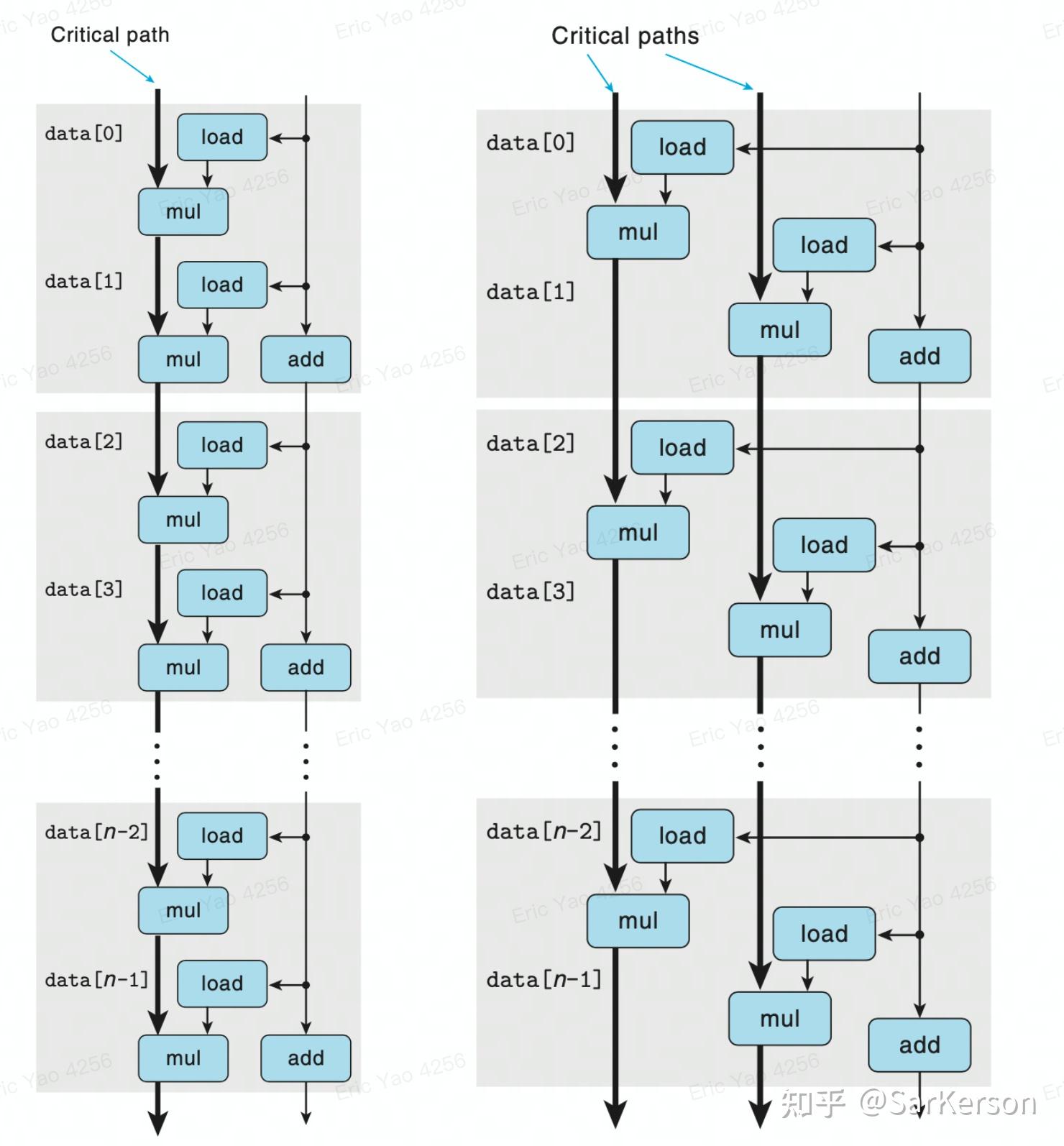
重新结合运算

优化前后的关键路径对比,可以看到每个 4 个 Element,节省了 2mul+2load 操作,速度提高 2x 多:
- 左边关键路径:(load+2mul)2=16
- 右边关键路径:2*mul=6
小结
本质:解除数据依赖
- 分治法:利用每个子问题的并行执行提高速度
- 重新结合变换:解除多项式操作中,项之间的关键依赖
分支
书写容易预测的代码
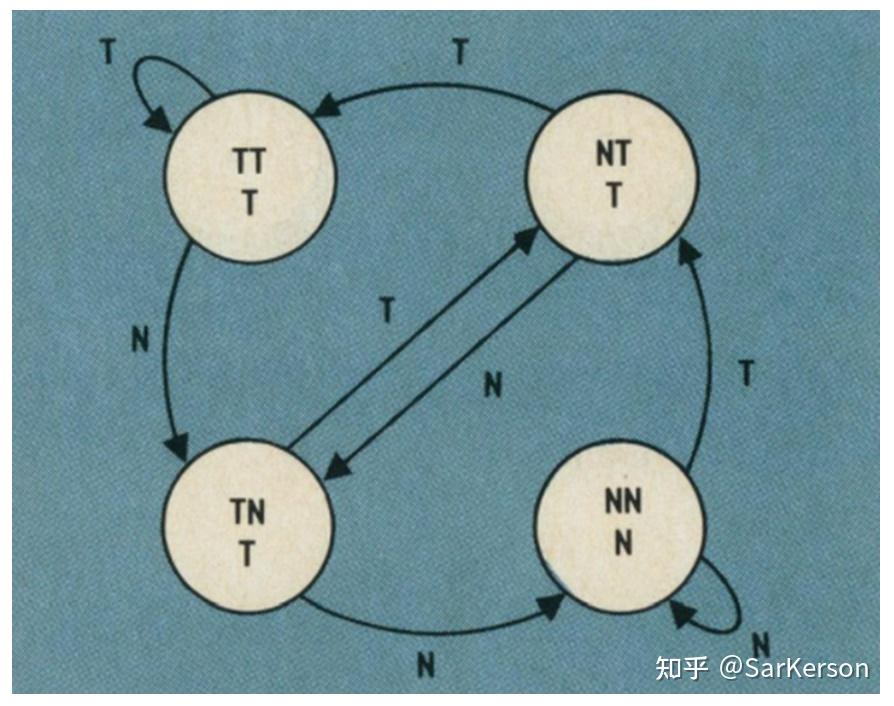
Why is processing a sorted array faster than processing an unsorted array? - Stack Overflow
现代处理器可以很好预测分支指令的有规律模式。
if (data[c] >= 128)
sum += data[c];
T = branch taken
N = branch not taken
data[] = 0, 1, 2, 3, 4, ... 126, 127, 128, 129, 130, ... 250, 251, 252, ...
branch = N N N N N ... N N T T T ... T T T ...
= NNNNNNNNNNNN ... NNNNNNNTTTTTTTTT ... TTTTTTTTTT (easy to predict)
data[] = 226, 185, 125, 158, 198, 144, 217, 79, 202, 118, 14, 150, 177, 182, ...
branch = T, T, N, T, T, T, T, N, T, N, N, T, T, T ...
= TTNTTTTNTNNTTT ... (completely random - impossible to predict)
书写适合条件传送的代码

- 条件跳转

- 条件传送

为什么条件传送更快?
先计算,再选择结果。且这些计算没有数据依赖,可以充分利用处理器的指令流水。
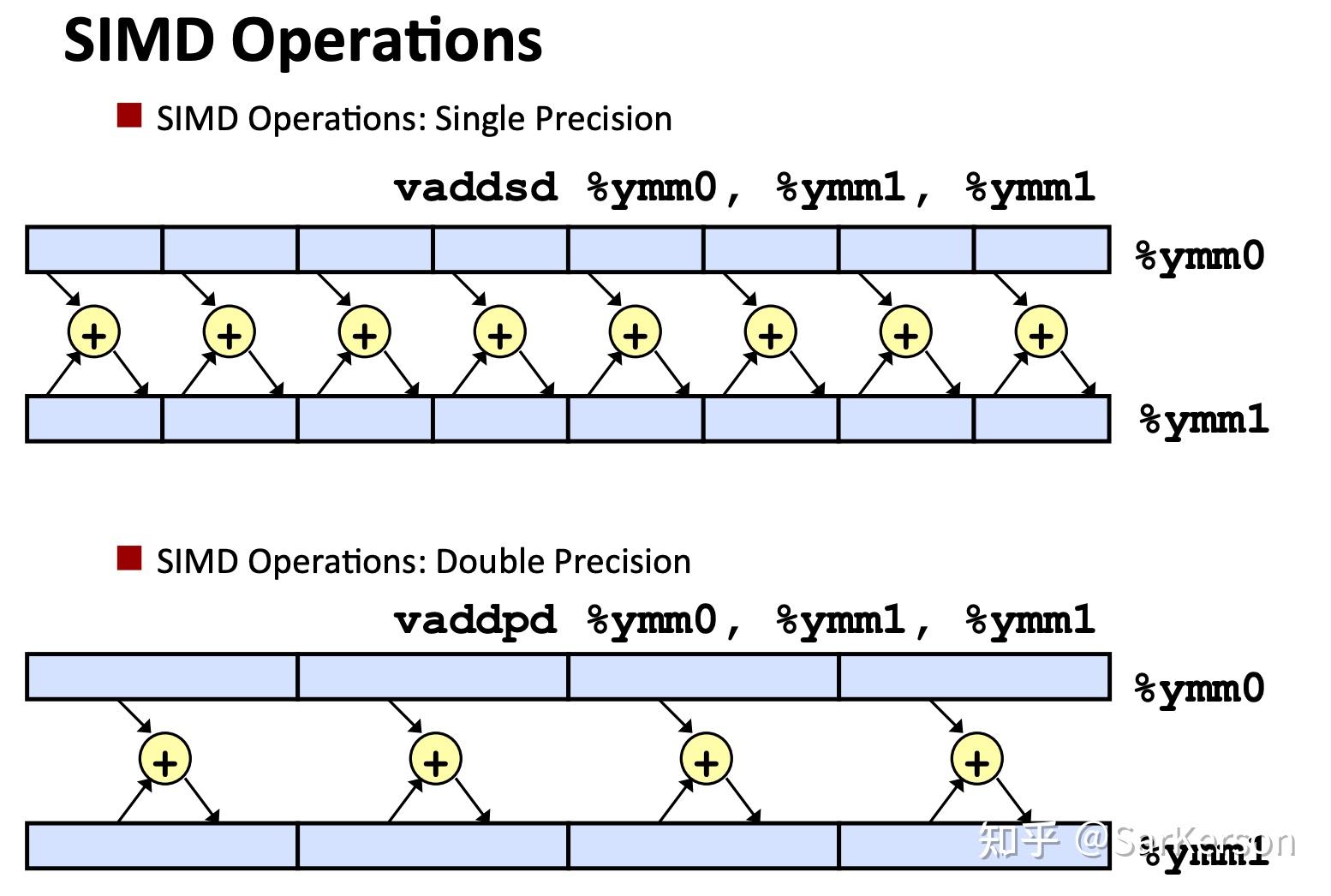
SIMD
SIMD(Single Instruction Multiple Data)即单指令流多数据流,是一种采用一个控制器来控制多个执行器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。简单来说就是一个指令能够同时处理多个数据。
Achieving Greater Parallelism with SIMD Instructions
5. 小结
- 良好的编码习惯
- 数据结构与算法
- 消除编译器优化障碍
- 过程调用
- 内存别名引用
- 优化循环
- 帮助机器更好地优化
- 利用指令并行
- 避免不可预测的分支
- 提高指令缓存命中率
本文所讲的这些优化方法,在大部分编译器中都已经实现了。但是它们有可能不会实行这些优化,或需要我们手动设置更高级别的优化选项才行。所以,作为一个程序员,我们应该做的是尽量引导编译器执行这些优化,或者说排除阻碍编译器优化的障碍。这样可以使我们的代码在保持简洁的情况下获得更高的性能。迫不得已时,我们才去手动做这些优化。
另外,循环展开、多路并行并不是越多越好。因为寄存器的个数是有限的,x86-64 最多只能有 12 个寄存器用于累加,如果局部变量的个数多于 12 个,就会被放进存储器,反倒严重拉低程序性能。
6. 身边活生生的例子
数据依赖
组内有同学反馈,跑 pprof 的时候,发现一个简单的函数调用占用了 20% 左右的 CPU 时间,这个函数只是取了一个对象里面的列表元素做简单计算。只不过对象潜套了多个指针,于是怀疑是指针嵌套的问题。
我把对应的代码抽出来,对比了直接引用(左)与指针嵌套引用(右)的汇编代码区别:
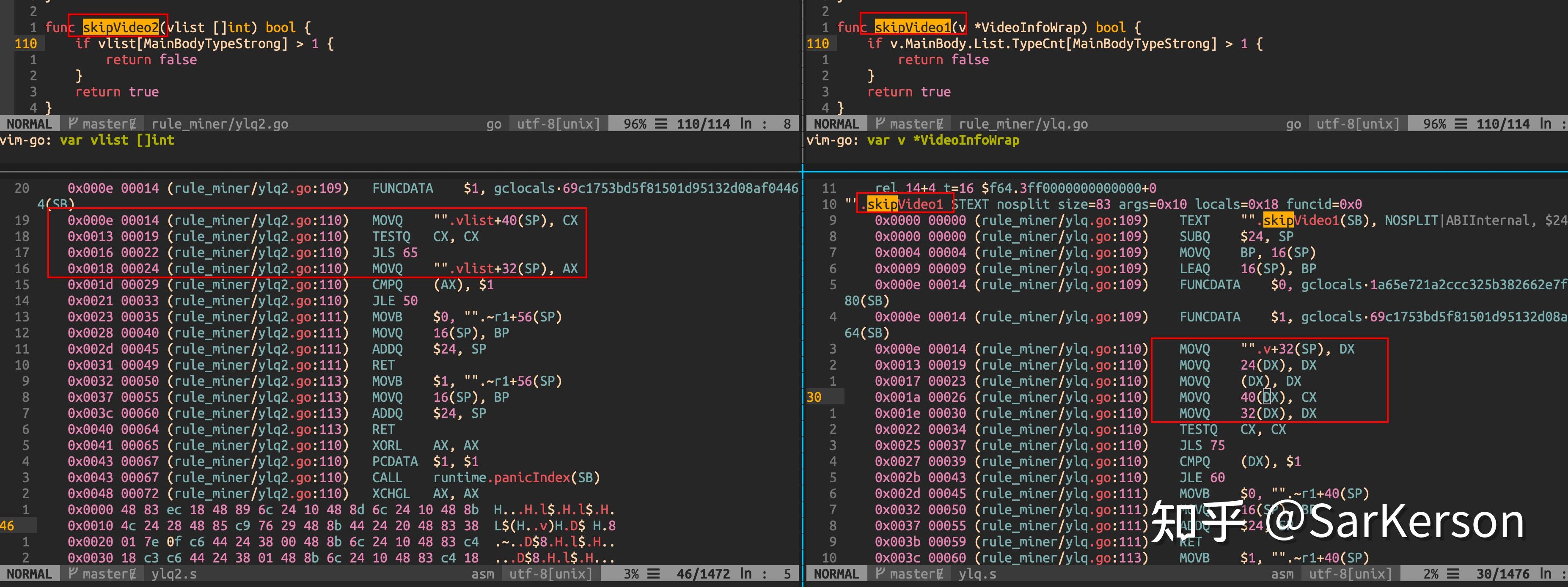
可以发现,右侧代码中,红圈中的 5 行指令都是在 DX 寄存器中进行操作,形成了数据依赖,无法充分利用指令流水。
指令缓存
摘自内部 infra 组同学的一篇文章,描述的是 RPC 框架一个小改动带来的性能问题。
事故现场:Mergely - Diff online, merge documents
可以看到,相比旧版本的生成代码,该 commit 在返回错误的时候会额外包装一下:
if err := ...; err != nil {
return thrift.PrependError(fmt.Sprintf("%T read field x 'xxx' error: ", p), err)
}
而旧版本的生成代码是直接返回的错误:
if err := ...; err != nil {
return err
}
虽然这些只是在发生错误的时候才会调用到,在正常流程中不会用到,但是生成的汇编代码中这段逻辑占了相当大的比例:
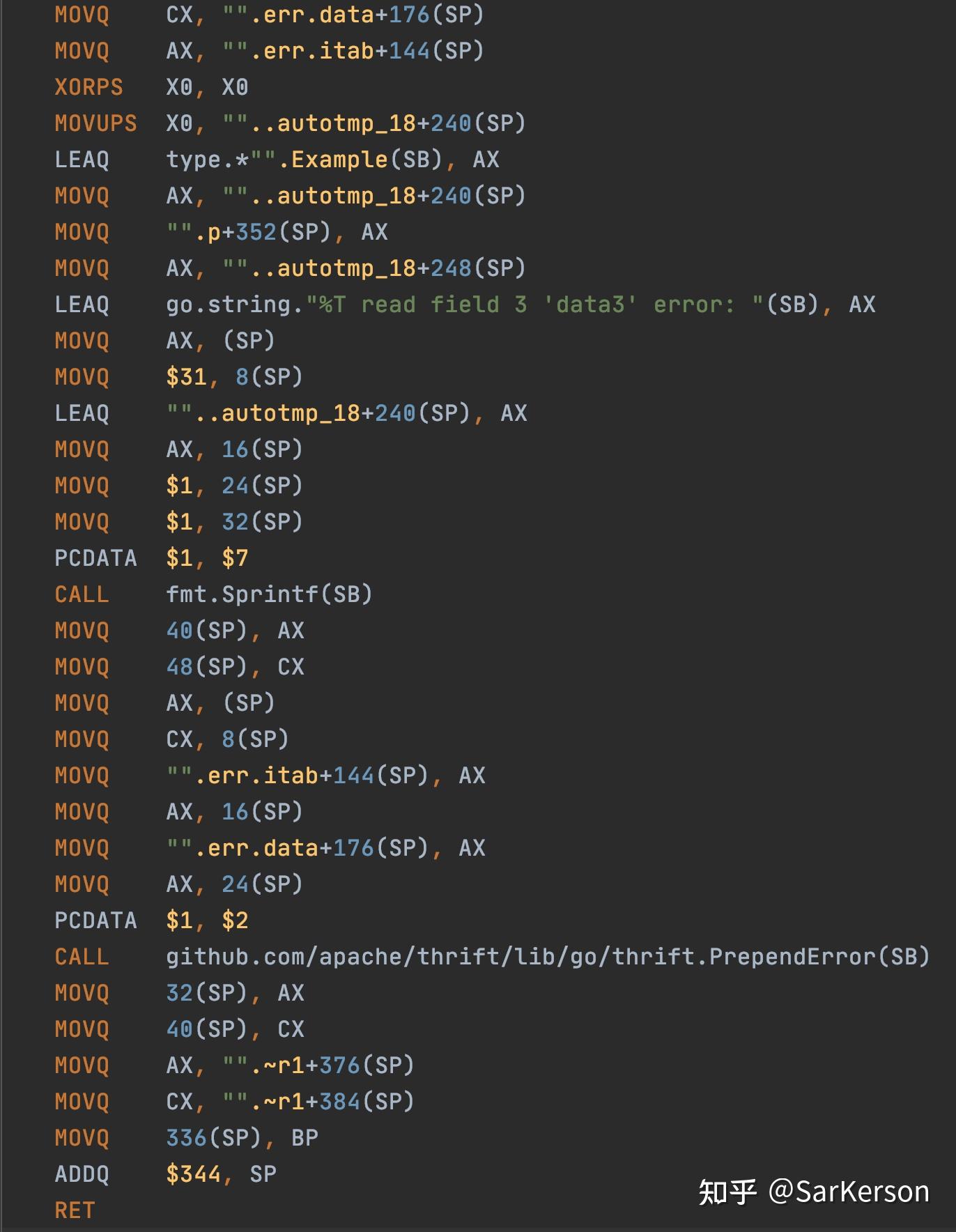
而 Go 的编译器并没有帮我们重排这些指令,导致在真正运行的时候,L1 cache miss 大大提高,极大地降低了性能。
拓展阅读
以下是 golang 一些性能分析的拓展阅读,有兴趣可以看。
Reference
- CMU 课件 10-optimization
-
CMU 电子书、课程等资料地址 wangmu89/Book-CSAPP: 深入理解计算机系统
- https://github.com/wangmu89/Book-CSAPP)