从 Redlock 到共识算法
TL;DR; 本文从介绍 Redlock 开始,引出 DDIA 作者 Martin 对 Redlock 的批判、Relock 作者 antirez 的反驳,从中总结出实现一个分布式锁的核心难题。该难题可以归结为分布式一致性问题,并总结了解决分布式一致性问题的模型与算法。
Redlock
2016 年 2 月,为了规范各家对基于Redis的分布式锁的实现,Redis的作者提出了一个更安全的实现,叫做 Redlock。
背景:解决基于单 Redis 节点的单点故障问题;以及哨兵模式下基于异步的主从复制(replication)可能带来的数据不一致问题。
因此 antirez 提出了新的分布式锁的算法 Redlock,它基于 N 个完全独立的 Redis 节点(通常情况下N可以设置成5)。

获取锁
运行Redlock算法的客户端依次执行下面各个步骤,来完成获取锁的操作:
- 获取当前时间(毫秒数)。
- 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串
my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。 - 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
- 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
释放锁
上面描述的只是获取锁的过程,而释放锁的过程比较简单:客户端向所有Redis节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。
为什么?
设想这样一种情况,客户端发给某个Redis节点的获取锁的请求成功到达了该Redis节点,这个节点也成功执行了SET操作,但是它返回给客户端的响应包却丢失了。这在客户端看来,获取锁的请求由于超时而失败了,但在Redis这边看来,加锁已经成功了。因此,释放锁的时候,客户端也应该对当时获取锁失败的那些Redis节点同样发起请求。实际上,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。
Failover
由于N个Redis节点中的大多数能正常工作就能保证Redlock正常工作,因此理论上它的可用性更高。我们前面讨论的单Redis节点的分布式锁在failover的时候锁失效的问题,在Redlock中不存在了,但如果有节点发生崩溃重启,还是会对锁的安全性有影响的。具体的影响程度跟 Redis 对数据的持久化程度有关。
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
- 客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。
- 节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
- 节点C重启后,客户端2锁住了C, D, E,获取锁成功。
这样,客户端1和客户端2同时获得了锁(针对同一资源)。
在默认情况下,Redis 的 AOF 持久化方式是每秒写一次磁盘(即执行fsync),因此最坏情况下可能丢失1秒的数据。为了尽可能不丢数据,Redis允许设置成每次修改数据都进行fsync,但这会降低性能。当然,即使执行了fsync也仍然有可能丢失数据(这取决于系统而不是Redis的实现)。所以,上面分析的由于节点重启引发的锁失效问题,总是有可能出现的。为了应对这一问题,antirez又提出了延迟重启(delayed restarts)的概念。也就是说,一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,这段时间应该大于锁的有效时间(lock validity time)。这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
Redlock 的各种讨论
要知道,亲手实现过Redis Cluster这样一个复杂系统的antirez,足以算得上分布式领域的一名专家了。但对于由分布式锁引发的一系列问题的分析中,不同的专家却能得出迥异的结论,从中我们可以窥见分布式系统相关的问题具有何等的复杂性。
实际上,在分布式系统的设计中经常发生的事情是:许多想法初看起来毫无破绽,而一旦详加考量,却发现不是那么天衣无缝。
Martin 的批判
缺乏 Fencing 机制
首先,在没有提供一种 fencing 机制的条件下,锁不具备安全性。
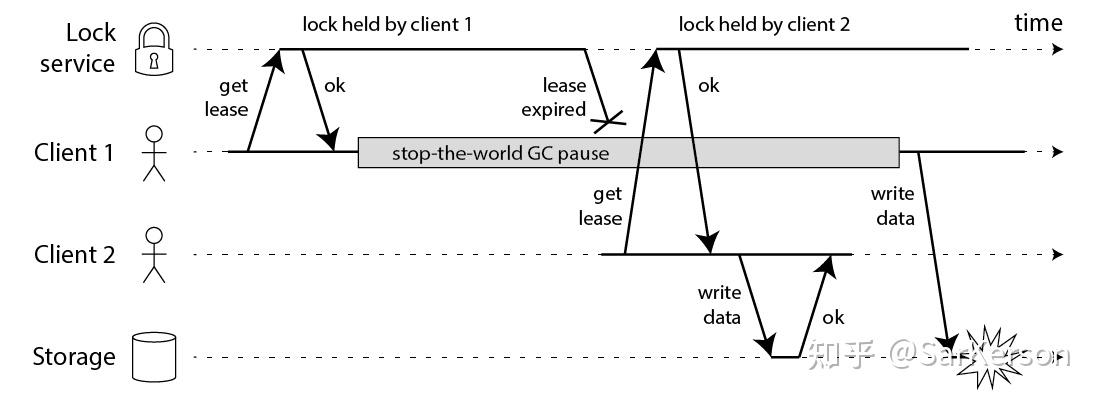
假设使锁服务本身是没有问题的,而仅仅是客户端有长时间的 pause 或网络延迟,仍然会造成两个客户端同时访问共享资源的冲突情况发生。
那怎么解决这个问题呢?Martin给出了一种方法,称为 fencing token。fencing token 是一个单调递增的数字,当客户端成功获取锁的时候它随同锁一起返回给客户端。而客户端访问共享资源的时候带着这个 fencing token,这样提供共享资源的服务就能根据它进行检查,拒绝掉延迟到来的访问请求(避免了冲突)。如下图:
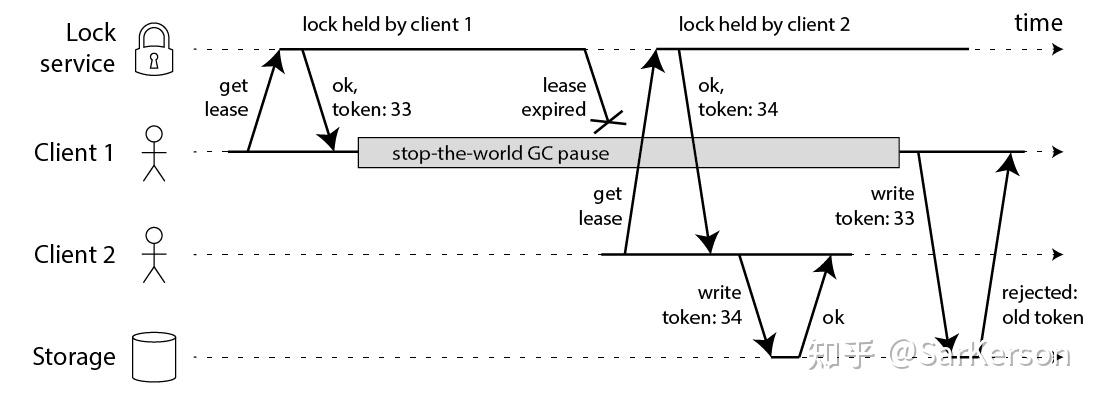
在上图中,客户端1先获取到的锁,因此有一个较小的 fencing token,等于33,而客户端2后获取到的锁,有一个较大的 fencing token,等于34。客户端1从GC pause中恢复过来之后,依然是向存储服务发送访问请求,但是带了 fencing token = 33。存储服务发现它之前已经处理过34的请求,所以会拒绝掉这次33的请求。这样就避免了冲突。
过多的计时假设
另外,由于Redlock本质上是建立在一个同步模型之上,而且对系统的记时假设(timing assumption)有很强的要求,因此本身的安全性是不够的。
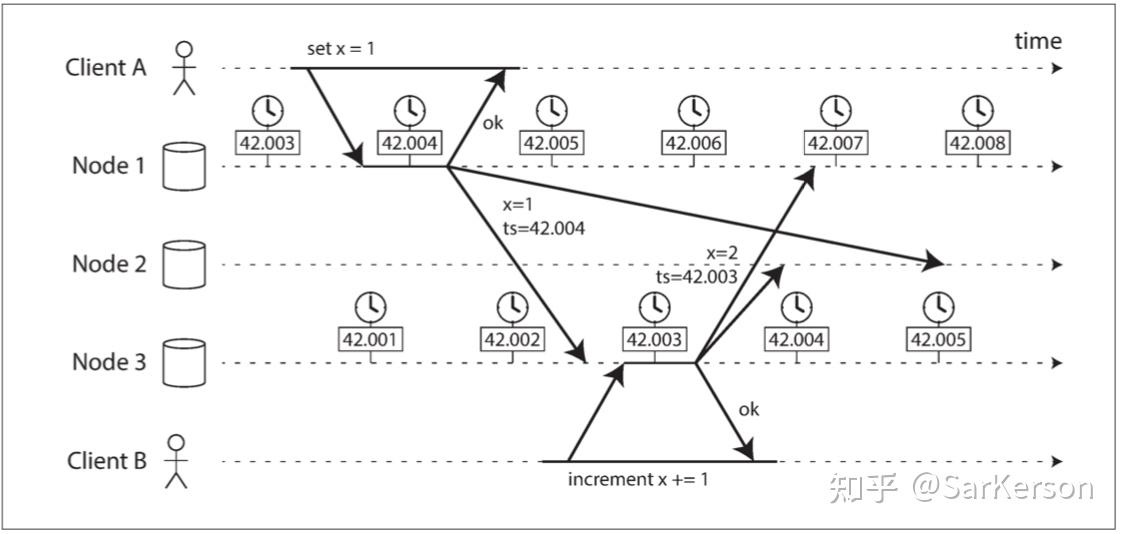
Martin在文中构造了一些事件序列,能够让Redlock失效(两个客户端同时持有锁)。为了说明Redlock对系统记时(timing)的过分依赖,他首先给出了下面的一个例子(还是假设有5个Redis节点A, B, C, D, E):
- 客户端1从Redis节点A, B, C成功获取了锁(多数节点)。由于网络问题,与D和E通信失败。
- 节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
- 客户端2从Redis节点C, D, E成功获取了同一个资源的锁(多数节点)。
- 客户端1和客户端2现在都认为自己持有了锁。
上面这种情况之所以有可能发生,本质上是因为Redlock的安全性(safety property)对系统的时钟有比较强的依赖,一旦系统的时钟变得不准确,算法的安全性也就保证不了了。Martin在这里其实是要指出分布式算法研究中的一些基础性问题,或者说一些常识问题,即好的分布式算法应该基于异步模型(asynchronous model),算法的安全性不应该依赖于任何记时假设(timing assumption)。
在异步模型中,进程可能pause任意长的时间,消息可能在网络中延迟任意长的时间,甚至丢失,系统时钟也可能以任意方式出错。一个好的分布式算法,这些因素不应该影响它的安全性(safety property),只可能影响到它的活性(liveness property),也就是说,即使在非常极端的情况下(比如系统时钟严重错误),算法顶多是不能在有限的时间内给出结果而已,而不应该给出错误的结果。这样的算法在现实中是存在的,像比较著名的 Paxos,或 Raft。但显然按这个标准的话,Redlock 的安全性级别是达不到的。
antirez 的反驳
Fencing Token 无需单调
antirez 对于 Martin 的这种论证方式提出了质疑:并发下的顺序没有意义。即使退一步讲,Redlock虽然提供不了 Martin 所讲的递增的 fencing token,但利用Redlock产生的随机数可以达到同样的效果。这个随机字符串虽然不是递增的,但却是唯一的,可以称之为 unique token。
时钟无需过分精确
Martin 认为 Redlock 会失效的情况主要有三种
- 时钟漂移
- 长时间的 GC pause
- 长时间的 网络延迟
时钟漂移
Martin 在提到时钟跳跃的时候,举了两个可能造成时钟跳跃的具体例子:
- 系统管理员手动修改了时钟。
- 从 NTP 服务收到了一个大的时钟更新事件。
antirez反驳说:
- 手动修改时钟这种人为原因,不要那么做就是了。否则的话,如果有人手动修改Raft协议的持久化日志,那么就算是Raft协议它也没法正常工作了。
- 使用一个不会进行“跳跃”式调整系统时钟的 ntpd 程序(可能是通过恰当的配置),对于时钟的修改通过多次微小的调整来完成。
而Redlock对时钟的要求,并不需要完全精确,它只需要时钟差不多精确就可以了。比如,要记时5秒,但可能实际记了4.5秒,然后又记了5.5秒,有一定的误差。不过只要误差不超过一定范围,这对Redlock不会产生影响。antirez认为,像这样对时钟精度并不是很高的要求,在实际环境中是完全合理的。
GC Pause
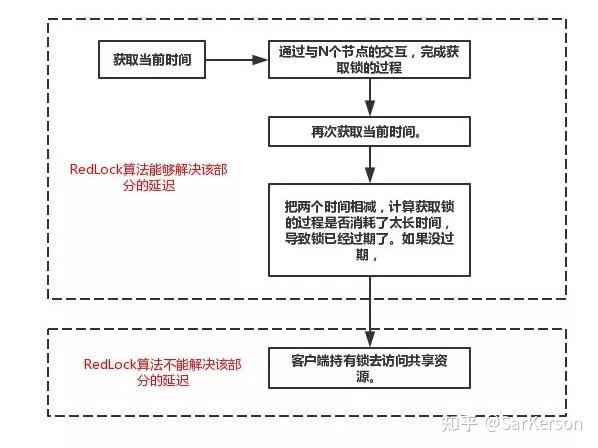
- 获取当前时间。
- 完成获取锁的整个过程(与N个Redis节点交互)。
- 再次获取当前时间。
- 把两个时间相减,计算获取锁的过程是否消耗了太长时间,导致锁已经过期了。如果没过期,
- 客户端持有锁去访问共享资源。
在Martin举的例子中,GC pause或网络延迟,实际发生在上述第1步和第3步之间。而不管在第1步和第3步之间由于什么原因(进程停顿或网络延迟等)导致了大的延迟出现,在第4步都能被检查出来,不会让客户端拿到一个它认为有效而实际却已经过期的锁。当然,这个检查依赖系统时钟没有大的跳跃。这也就是为什么 antirez 在前面要对时钟条件进行辩护的原因。
第四步之后,仍然可能存在延迟呢?
antirez 申明称,这个问题对于所有的分布式锁的实现是普遍存在的。(这 Redlock 确实解决不了,因为需要递增 fencing 机制解决)
Redlock 的问题与小结
Martin 认为 Redlock 实在不是一个好的选择,对于需求性能的分布式锁应用它太重了且成本高;对于需求正确性的应用来说它不够安全。
因为它对高危的时钟或者说其他上述列举的情况进行了不可靠的假设,如果你的应用只需要高性能的分布式锁不要求多高的正确性,那么单节点 Redis 够了;如果你的应用想要保住正确性,那么不建议 Redlock,建议使用一个合适的一致性协调系统,例如 Zookeeper,且保证存在 fencing token。
仅有在你假设了一个同步系统模型的基础上,Redlock 才能正常工作,也就是系统能满足以下属性:
- 网络延时边界,即假设数据包一定能在某个最大延时之内到达
- 进程停顿边界,即进程停顿一定在某个最大时间之内
- 时钟错误边界,即不会从一个坏的 NTP 服务器处取得时间
在Martin 的这篇文章中,还有一个很有见地的观点,就是对锁的用途的区分。他把锁的用途分为两种:
- 为了效率(efficiency),协调各个客户端避免做重复的工作。即使锁偶尔失效了,只是可能把某些操作多做一遍而已,不会产生其它的不良后果。比如重复发送了一封同样的email。
- 为了正确性(correctness)。在任何情况下都不允许锁失效的情况发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏,或者其它严重的问题。
最后,Martin得出了如下的结论:
- 如果是为了效率(efficiency)而使用分布式锁,允许锁的偶尔失效,那么使用单Redis节点的锁方案就足够了,简单而且效率高。Redlock则是个过重的实现(heavyweight)。
- 如果是为了正确性(correctness)在很严肃的场合使用分布式锁,那么不要使用Redlock。它不是建立在异步模型上的一个足够强的算法,它对于系统模型的假设中包含很多危险的成分(对于timing)。而且,它没有一个机制能够提供fencing token。那应该使用什么技术呢?Martin认为,应该考虑类似Zookeeper的方案,或者支持事务的数据库。
宁愿正确地挂掉,也不错误地运行。
分布式模型
现实中的挑战
前面我们介绍了 Redlock 算法及各大咖的讨论,引出 Redlock 的问题,这些问题也是现实中实现分布式系统会经常遇到的挑战,这里简单对这些挑战做下小结。
不可靠的网络
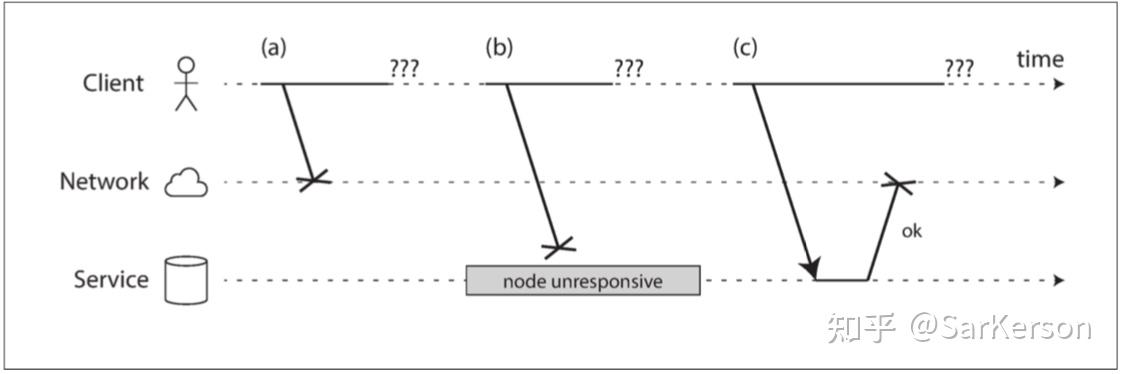
如果发送请求并没有得到响应,则无法区分(a)请求是否丢失,(b)远程节点是否关闭,或(c)响应是否丢失。
不可靠的时钟
计算机中的石英钟不够精确:它会漂移(drifts)(运行速度快于或慢于预期)。时钟漂移取决于机器的温度。 Google 假设其服务器时钟漂移为200 ppm(百万分之一),相当于每30秒与服务器重新同步一次的时钟漂移为6毫秒,或者每天重新同步的时钟漂移为17秒。即使一切工作正常,此漂移也会限制程序可以达到的最佳准确度。
一个多主复制的场景,客户端B的写入比客户端A的写入要晚,但是B的写入具有较早的时间戳。因此解决冲突的时候把 B 的请求丢了(如果使用 Last Write Wins 的话)。
逻辑时钟(logic clock)是基于递增计数器而不是振荡石英晶体,对于排序事件来说是更安全的选择。
Google TrueTime API ,Google 在 spanner 中使用的全局时间戳,它明确地报告了本地时钟的置信区间。当你询问当前时间时,你会得到两个值:[最早,最晚],这是最早可能的时间戳和最晚可能的时间戳。在不确定性估计的基础上,时钟知道当前的实际时间落在该区间内。可以根据这个区间做一些骚操作,比如两个事务之间等待置信区间长度,保证两个事务的置信区间不重叠,由此保证事务的顺序。
进程暂停
- 许多编程语言运行时(如Java虚拟机)都有一个垃圾收集器(GC),偶尔需要停止所有正在运行的线程。这些“停止世界(stop-the-world)”GC暂停有时会持续几分钟【64】!甚至像HotSpot JVM的CMS这样的所谓的“并行”垃圾收集器也不能完全与应用程序代码并行运行,它需要不时地停止世界【65】。尽管通常可以通过改变分配模式或调整GC设置来减少暂停【66】,但是如果我们想要提供健壮的保证,就必须假设最坏的情况发生。
- 在虚拟化环境中,可以挂起(suspend)虚拟机(暂停执行所有进程并将内存内容保存到磁盘)并恢复(恢复内存内容并继续执行)。这个暂停可以在进程执行的任何时候发生,并且可以持续任意长的时间。这个功能有时用于虚拟机从一个主机到另一个主机的实时迁移,而不需要重新启动,在这种情况下,暂停的长度取决于进程写入内存的速率【67】。
- 在最终用户的设备(如笔记本电脑)上,执行也可能被暂停并随意恢复,例如当用户关闭笔记本电脑的盖子时。
- 当操作系统上下文切换到另一个线程时,或者当管理程序切换到另一个虚拟机时(在虚拟机中运行时),当前正在运行的线程可以在代码中的任意点处暂停。在虚拟机的情况下,在其他虚拟机中花费的CPU时间被称为窃取时间(steal time)。如果机器处于沉重的负载下(即,如果等待运行的线程很长),暂停的线程再次运行可能需要一些时间。
- 如果应用程序执行同步磁盘访问,则线程可能暂停,等待缓慢的磁盘I/O操作完成【68】。在许多语言中,即使代码没有包含文件访问,磁盘访问也可能出乎意料地发生——例如,Java类加载器在第一次使用时惰性加载类文件,这可能在程序执行过程中随时发生。 I/O暂停和GC暂停甚至可能合谋组合它们的延迟【69】。如果磁盘实际上是一个网络文件系统或网络块设备(如亚马逊的EBS),I/O延迟进一步受到网络延迟变化的影响【29】。
- 如果操作系统配置为允许交换到磁盘(分页),则简单的内存访问可能导致页面错误(page fault),要求将磁盘中的页面装入内存。当这个缓慢的I/O操作发生时,线程暂停。如果内存压力很高,则可能需要将不同的页面换出到磁盘。在极端情况下,操作系统可能花费大部分时间将页面交换到内存中,而实际上完成的工作很少(这被称为抖动(thrashing))。为了避免这个问题,通常在服务器机器上禁用页面调度(如果你宁愿干掉一个进程来释放内存,也不愿意冒抖动风险)。
- 可以通过发送SIGSTOP信号来暂停Unix进程,例如通过在shell中按下Ctrl-Z。 这个信号立即阻止进程继续执行更多的CPU周期,直到SIGCONT恢复为止,此时它将继续运行。 即使你的环境通常不使用SIGSTOP,也可能由运维工程师意外发送。
所有这些事件都可以随时抢占(preempt)正在运行的线程,并在稍后的时间恢复运行,而线程甚至不会注意到这一点。这个问题类似于在单个机器上使多线程代码线程安全:你不能对时机做任何假设,因为随时可能发生上下文切换,或者出现并行运行。
分布式系统中的节点,必须假定其执行可能在任意时刻暂停相当长的时间,即使是在一个函数的中间。在暂停期间,世界的其它部分在继续运转,甚至可能因为该节点没有响应,而宣告暂停节点的死亡。最终暂停的节点可能会继续运行,在再次检查自己的时钟之前,甚至可能不会意识到自己进入了睡眠。
拜占庭故障
拜占庭将军问题是 Leslie Lamport 在 The Byzantine Generals Problem 论文中提出的分布式领域的容错问题,它是分布式领域中最复杂、最严格的容错模型。
在该模型下,系统不会对集群中的节点做任何的限制,它们可以向其他节点发送随机数据、错误数据,也可以选择不响应其他节点的请求,这些无法预测的行为使得容错这一问题变得更加复杂。
计时模型
同步模型
同步模型(synchronous model)假设网络延迟,进程暂停和和时钟误差都是有界限的。这并不意味着完全同步的时钟或零网络延迟;这只意味着你知道网络延迟,暂停和时钟漂移将永远不会超过某个固定的上限。同步模型并不是大多数实际系统的现实模型,因为(如本章所讨论的)无限延迟和暂停确实会发生。
半同步模型
部分同步(partial synchronous)意味着一个系统在大多数情况下像一个同步系统一样运行,但有时候会超出网络延迟,进程暂停和时钟漂移的界限。这是很多系统的现实模型:大多数情况下,网络和进程表现良好,否则我们永远无法完成任何事情,但是我们必须承认,在任何时刻假设都存在偶然被破坏的事实。发生这种情况时,网络延迟,暂停和时钟错误可能会变得相当大。
异步模型
在这个模型中,一个算法不允许对时机做任何假设(所以它不能使用超时)—— 事实上它甚至没有时钟。一些算法被设计为可用于异步模型,但非常受限。
节点故障模型
崩溃-终止模型
在崩溃停止(crash-stop)模型中,算法可能会假设一个节点只能以一种方式失效,即通过崩溃。这意味着节点可能在任意时刻突然停止响应,此后该节点永远消失——它永远不会回来。
崩溃-恢复模型
我们假设节点可能会在任何时候崩溃,但也许会在未知的时间之后再次开始响应。在崩溃-恢复(crash-recovery)模型中,假设节点具有稳定的存储(即,非易失性磁盘存储)且会在崩溃中保留,而内存中的状态会丢失。
拜占庭故障模型
节点可以做(绝对意义上的)任何事情,包括调戏和欺骗其他节点,如上一节所述。
对于真实的系统,最普遍的模型组合是,半同步计时模型+崩溃-恢复模型。
分布式共识算法
问题有了,为了解决问题而抽象出来的模型也有了,接下来就是实实在在的算法和实现了。
可线性化
可线性化是最强的一致性模型。后面会讲到的共识算法,都会无限逼近这个模型。其背后的基本思想很简单:使系统看起来好像只有一个数据副本。
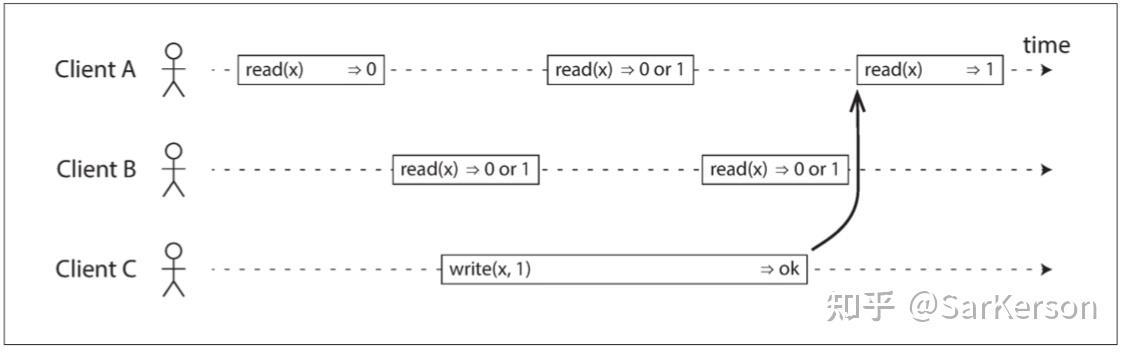
- 一个非可线性化的例子:如果读取请求与写入请求并发,则可能会返回旧值或新值:
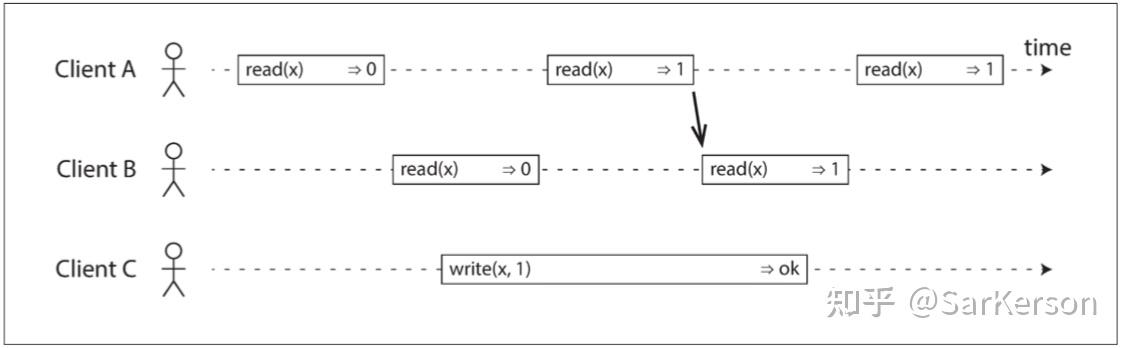
- 为了使系统线性一致,我们需要添加另一个约束:任何一个读取返回新值后,所有后续读取(在相同或其他客户端上)也必须返回新值。
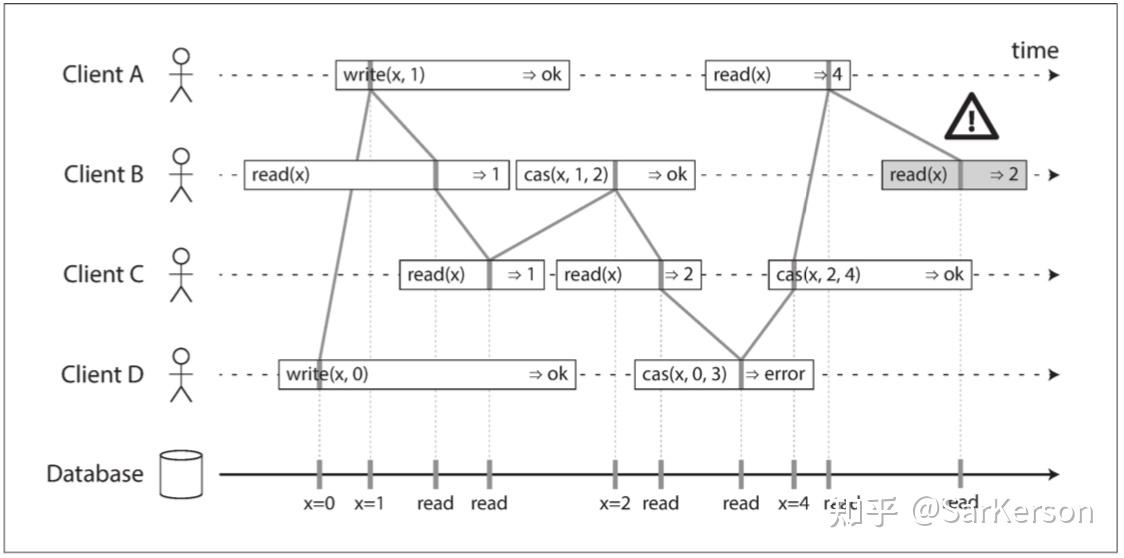
每个操作都在我们认为执行操作的时候用竖线标出(在每个操作的条柱之内)。这些标记按顺序连在一起,其结果必须是一个有效的寄存器读写序列(每次读取都必须返回最近一次写入设置的值),操作标记的连线总是按时间(从左到右)向前移动,而不是向后移动。这就要求可线性化确保一个条件恒成立:一旦新值被写入或者读取,所有后续的读看到都是最新的值。
实现可线性化
我们已经见到了几个线性一致性有用的例子,让我们思考一下,如何实现一个提供线性一致语义的系统。
由于线性一致性本质上意味着“表现得好像只有一个数据副本,而且所有的操作都是原子的”,所以最简单的答案就是,真的只用一个数据副本。但是这种方法无法容错:如果持有该副本的节点失效,数据将会丢失,或者至少无法访问,直到节点重新启动。
使系统容错最常用的方法是使用复制。
主从复制(可能线性一致)
在具有单主复制功能的系统中(参见“领导者与追随者”),主库具有用于写入的数据的主副本,而追随者在其他节点上保留数据的备份副本。如果从主库或同步更新的从库读取数据,它们可能是线性一致性的。然而,并不是每个单主数据库都是实际线性一致性的,无论是通过设计(例如,因为使用快照隔离)还是并发错误。
从主库读取依赖一个假设,你确定主节点是谁。正如在“真理在多数人手中”中所讨论的那样,一个节点很可能会认为它是领导者,而事实上并非如此——如果具有错觉的领导者继续为请求提供服务,可能违反线性一致性。而且,如果使用异步复制,故障切换时甚至可能会丢失已提交的写入(参阅“处理节点宕机”),这同时违反了持久性和线性一致性。
共识算法(线性一致)
一些在本章后面讨论的共识算法,与主从复制类似。然而,共识协议包含防止脑裂和陈旧副本的措施。由于这些细节,共识算法可以安全地实现线性一致性存储。例如,Zookeeper 和 etcd 就是这样工作的。
多主复制(非线性一致)
具有多主程序复制的系统通常不是线性一致的,因为它们同时在多个节点上处理写入,并将其异步复制到其他节点。因此,它们可能会产生冲突的写入,需要解析(参阅“处理写入冲突”)。这种冲突是因为缺少单一数据副本人为产生的。
无主复制(也许不是线性一致的)
直觉上 Quorum 是线性一致的,但是实际上存在非线性一致的执行,尽管使用了严格的 Quorum:
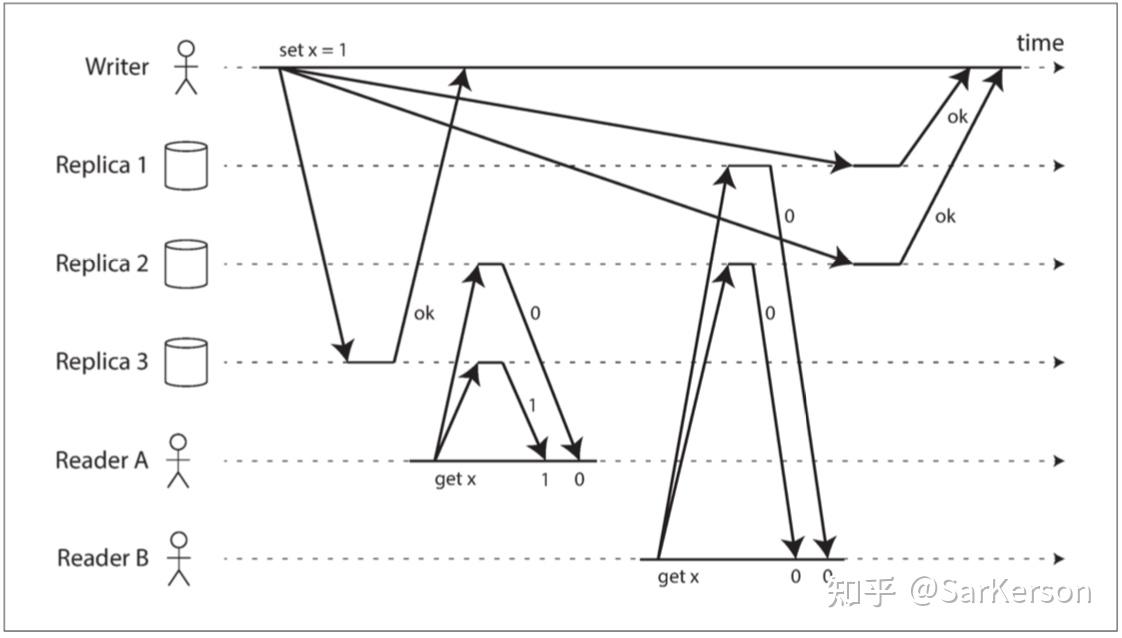
有趣的是,通过牺牲性能,可以使 Dynamo 风格的 Quorum 读写线性化:读取者必须在将结果返回给应用之前,同步执行读修复(参阅“读时修复与反熵过程”) ,并且写入者必须在发送写入之前,读取 Quorum 数量节点的最新状态。然而,由于性能损失,Riak不执行同步读修复。 Cassandra 在进行 Quorum 读取时,确实在等待读修复完成;但是由于使用了最后写入为准的冲突解决方案,当同一个键有多个并发写入时,将不能保证线性一致性。
全序关系广播
全序关系广播与共识关系密切。
单主复制通过选择一个节点作为主库来确定操作的全序,并在主库的单个CPU核上对所有操作进行排序。接下来的挑战是,如果吞吐量超出单个主库的处理能力,这种情况下如何扩展系统;以及,如果主库失效(“处理节点宕机”),如何处理故障切换。在分布式系统文献中,这个问题被称为全序广播(total order broadcast)或原子广播(atomic broadcast)。
全序广播通常被描述为在节点间交换消息的协议。 非正式地讲,它要满足两个安全属性:
- 可靠交付(reliable delivery) 没有消息丢失:如果消息被传递到一个节点,它将被传递到所有节点。
- 全序交付(totally ordered delivery) 消息以相同的顺序传递给每个节点。
正确的全序广播算法必须始终保证可靠性和有序性,即使节点或网络出现故障。当然在网络中断的时候,消息是传不出去的,但是算法可以不断重试,以便在网络最终修复时,消息能及时通过并送达(当然它们必须仍然按照正确的顺序传递)。
共识算法
非容错共识算法
2PC
两阶段提交(Two Phase Commit, 2PC)是一种在多节点之间实现事务原子提交的共识算法,用来保证所有节点要么全部提交,要么全部终止。(是后面提及到的几个容错共识算法的原型)
算法流程
- 2PC 触发时机:协调者向所有数据库发送 write 请求并收到成功之后,准备提交事务
- 2PC 处理流程:2PC 将事务的提交过程分成了准备和提交两个阶段进行处理
- 阶段一 prepare:
- 协调者向所有参与者发送一个准备请求,并打上全局事务ID的标记。如果任意一个请求失败或超时,则协调者向所有参与者发送针对该事务ID的中止请求;
- 参与者收到准备请求时,需要确保在任意情况下都的确可以提交事务(通过写入 undolog、redolog);
- 参与者向协调者反馈响应;
- 阶段二 commit:
- 当协调者收到所有准备请求的答复时,会就提交或中止事务作出明确的决定(只有在所有参与者投赞成票的情况下才会提交)。协调者必须把这个决定写到磁盘上的事务日志中,如果它随后就崩溃,恢复后也能知道自己所做的决定。这被称为提交点(commit point);
- 一旦协调者的决定落盘,提交或放弃请求会发送给所有参与者。如果这个请求失败或超时,协调者必须永远保持重试,直到成功为止。
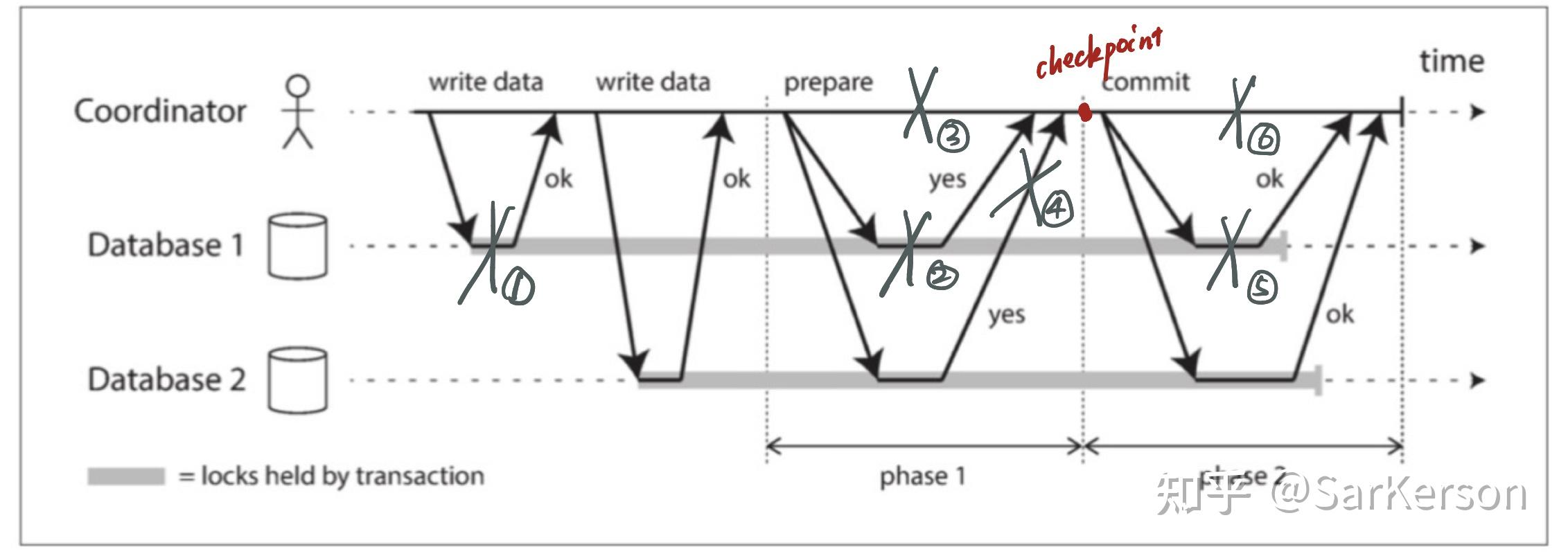
因此,该协议包含两个关键的“不归路”点:
- 当参与者投票“yes”时,它承诺它稍后肯定能够提交(尽管协调者可能仍然选择放弃);
- 一旦协调者做出决定,这一决定是不可撤销的;
故障分析
- 任何一个写失败,协调者都不会提交事务,因此安全;
- 任何一个参与者 prepare 失败,协调者不会提交事务,因此安全;
- 协调者在 prepare 中失败,返回给用户错误,且事务没有真正提交,因此安全;
- 参与者 prepare 回包丢失,协调者不会提交事务,因此安全;
- 参与者在 commit 阶段挂了,协调者会无限重试保证事务提交;
- 协调者挂了,可以完成 2PC 的唯一方法是等待协调者恢复。这就是为什么协调者必须在向参与者发送提交或中止请求之前,将其提交或中止决定写入磁盘上的事务日志:协调者恢复后,通过读取其事务日志来确定所有存疑事务的状态。任何在协调者日志中没有提交记录的事务都会终止。
3PC
3PC 假定一个有界的网络延迟并且节点能够在规定时间内响应,所以 3PC 通过连接是否超时来判断节点是否故障:如果参与者等待第二阶段指令超时,则自动 abort 抛弃事务,若等待第三阶段指令超时,则自动 commit 提交事务。相较于两阶段提交,三阶段提交协议最大的优点是降低了参与者的阻塞范围,并且能够在出现单点故障后继续保持一致。
容错共识算法
本节的所有算法都可以归纳为类 Paxos 算法, 并且他们的实现流程与 2PC 非常类似。
最大的区别在于,
- 2PC 的主节点是由外部指定的,而类 Paxos 算法可以在主节点崩溃失效后重新选举出新的主节点并进入一致状态。
- 容错共识算法只要收到多数节点的投票结果即可通过决议,而 2PC 则要每个参与者都必须做出 Yes 响应才能通过。
这些差异是确保共识算法的正确性和容错性的关键。
Paxos
Overview
个人觉得最好的学习路线:Paxos lecture(Recommended) + Paxos Wikipedia + Paper(optional)(有严格先后顺序)
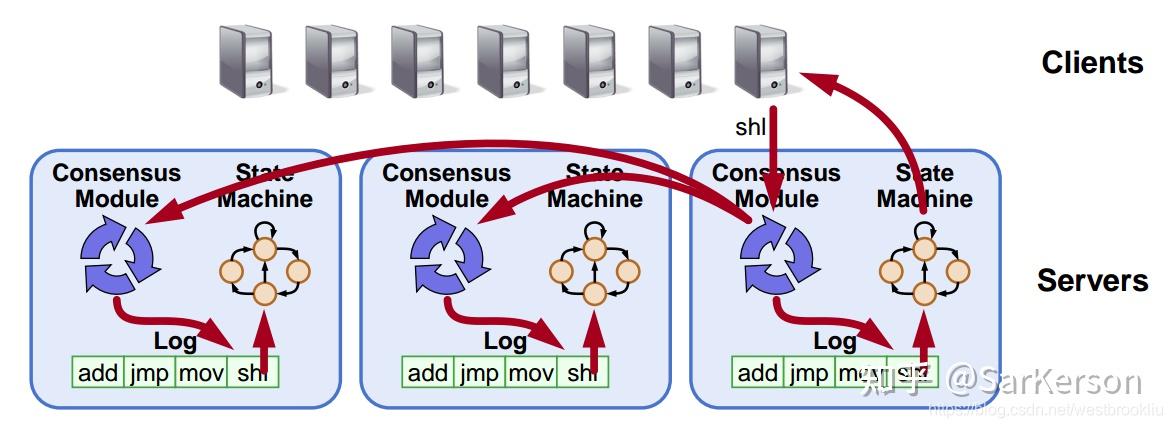
Paxos 的目标:Leader 想把自己的日志,一行不漏同步到其他所有 Follower。
在多个节点中,对日志的一致性达成共识。一旦日志相同,则能保证每个节点的状态机相同(按照相同的顺序,执行相同的命令)
状态机
- 安全性:所有节点的日志的顺序必须相同
- 活性:最终,所有节点拥有相同且完整的日志,执行了相同的日志序列,拥有相同的状态
概念
-
an paxos instance:一轮法案,一个任期(一个任期范围内,有且只有一个被选定的提案值)
-
a round:一个新的 proposal 的提出过程(包含两阶段),每轮法案可能包含多个 proposal(or say, round)
-
proposal number:提案编号(日志的 offset),通常是 n;每一个新的提案编号,都会严格大于旧提案编号
-
proposal value:提案的内容(日志的内容),通常是 v;
-
Basic Paxos:
对某行日志达成共识的过程
- 一个或多个 server 提出议案(propose value)
- 系统有且选择一个议案(single value chosen)
- 系统不曾选择第二个议案
-
Multi-Paxos
- 由多轮 Basic Paxos instance,达成一个一致的日志序列的过程
Basic Paxos
Each “instance” (or “execution”) of the basic Paxos protocol decides on a single output value. The protocol proceeds over several rounds.
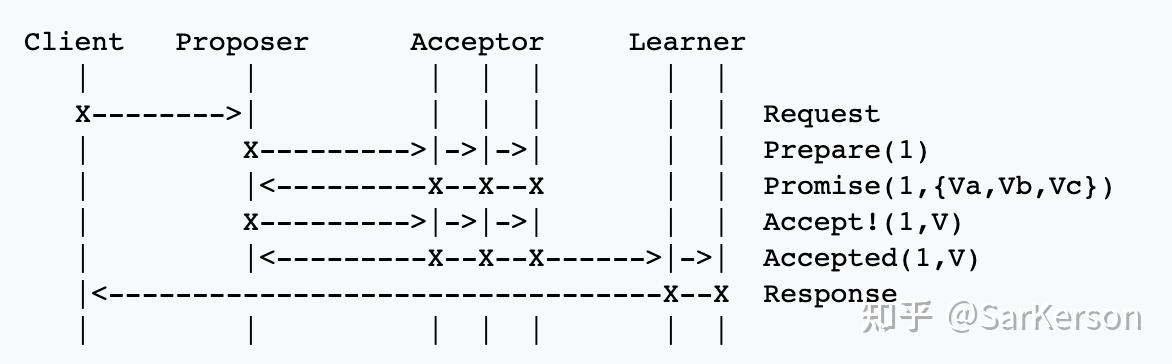

Multi Paxos
In Paxos, clients send commands to a leader. During normal operation, the leader receives a client’s command, assigns it a new command number i, and then begins the ith instance of the consensus algorithm by sending messages to a set of acceptor processes.
引入多个 Paxos instance 之后,需要解决的问题
- 性能优化:多主导致延迟收敛、多轮 Paxos instance 的冗余 prepare RPCs
- 如何选择一个 proposal 编号(日志 offset)
- 如何保证日志的完整性
- 如何与客户端的交互
Raft & Zab
篇幅关系,可以参阅其他博文,相比于 paxos,raft 可以找到更多更好的教程。
拜占庭故障容错算法
当一个系统在部分节点发生故障、不遵守协议、甚至恶意攻击、扰乱网络时仍然能继续正确工作,称之为拜占庭容错(Byzantine fault-tolerant)的,在特定场景下,这种担忧在是有意义的:
- 在航空航天环境中,计算机内存或CPU寄存器中的数据可能被辐射破坏,导致其以任意不可预知的方式响应其他节点。由于系统故障将非常昂贵(例如,飞机撞毁和炸死船上所有人员,或火箭与国际空间站相撞),飞行控制系统必须容忍拜占庭故障。
- 在多个参与组织的系统中,一些参与者可能会试图欺骗或欺骗他人。在这种情况下,节点仅仅信任另一个节点的消息是不安全的,因为它们可能是出于恶意的目的而被发送的。例如,像比特币和其他区块链一样的对等网络可以被认为是让互不信任的各方同意交易是否发生的一种方式,而不依赖于中央当局。
工程化实现与应用
Zookeeper
Ref ZooKeeper 与 Zab 协议 · Analyze - beihai blog (wingsxdu.com)
Zab 协议的全称是 ZooKeeper 原子广播协议(ZooKeeper Atomic Broadcast Protocol),实际上实现了前面提及的全序关系广播。
节点状态
ZooKeeper 中所有的写请求必须由一个全局唯一的 Leader 服务器来协调处理。
ZooKeeper 客户端会随机连接(长连接,并通过心跳维护 session)到 ZooKeeper 集群中的一个节点,如果是读请求,就直接从当前节点中读取数据;如果是写请求,那么该节点就会向 Leader 转发请求,Leader 接收到读写事务后,会将事务转换为一个事务提案(Proposal),并向集群广播该提案,只要超过半数节点写入数据成功,Leader 会再次向集群广播 Commit 消息,将该提案提交。
ZooKeeper 集群节点可能处于下面四种状态之一,分别是:
- LOOKING:进入 Leader 选举状态;
- LEADING:某个节点成为 Leader 并负责协调事务 ;
- FOLLOWING:当前节点是 Follower,服从 Leader 节点的命令并参与共识;
- OBSERVING:Observer 节点是只读节点,用于增加集群的只读事务性能,不参与共识与选举。
Zab 协议使用ZXID 来表示全局事务编号,ZXID 是一个 64 位数字,其中低 32 位是一个单调递增的计数器,针对客户端每一个事务请求,计数器都加 1;高 32 位则表示当前 Leader 的 Epoch,每当选举出一个新的主服务器,就会从集群日志中取出最大的 ZXID,从中读取出 Epoch 值,然后加 1,以此作为新的 Epoch,同时将低 32 位从 0 开始计数。
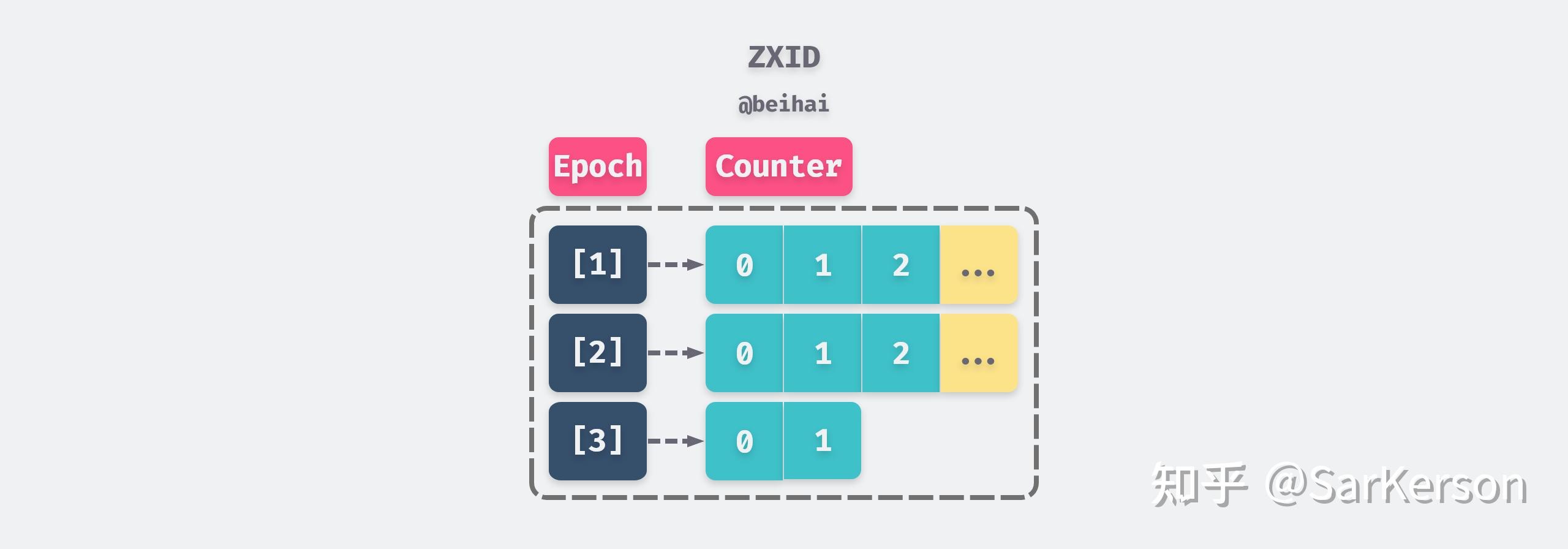
全序广播
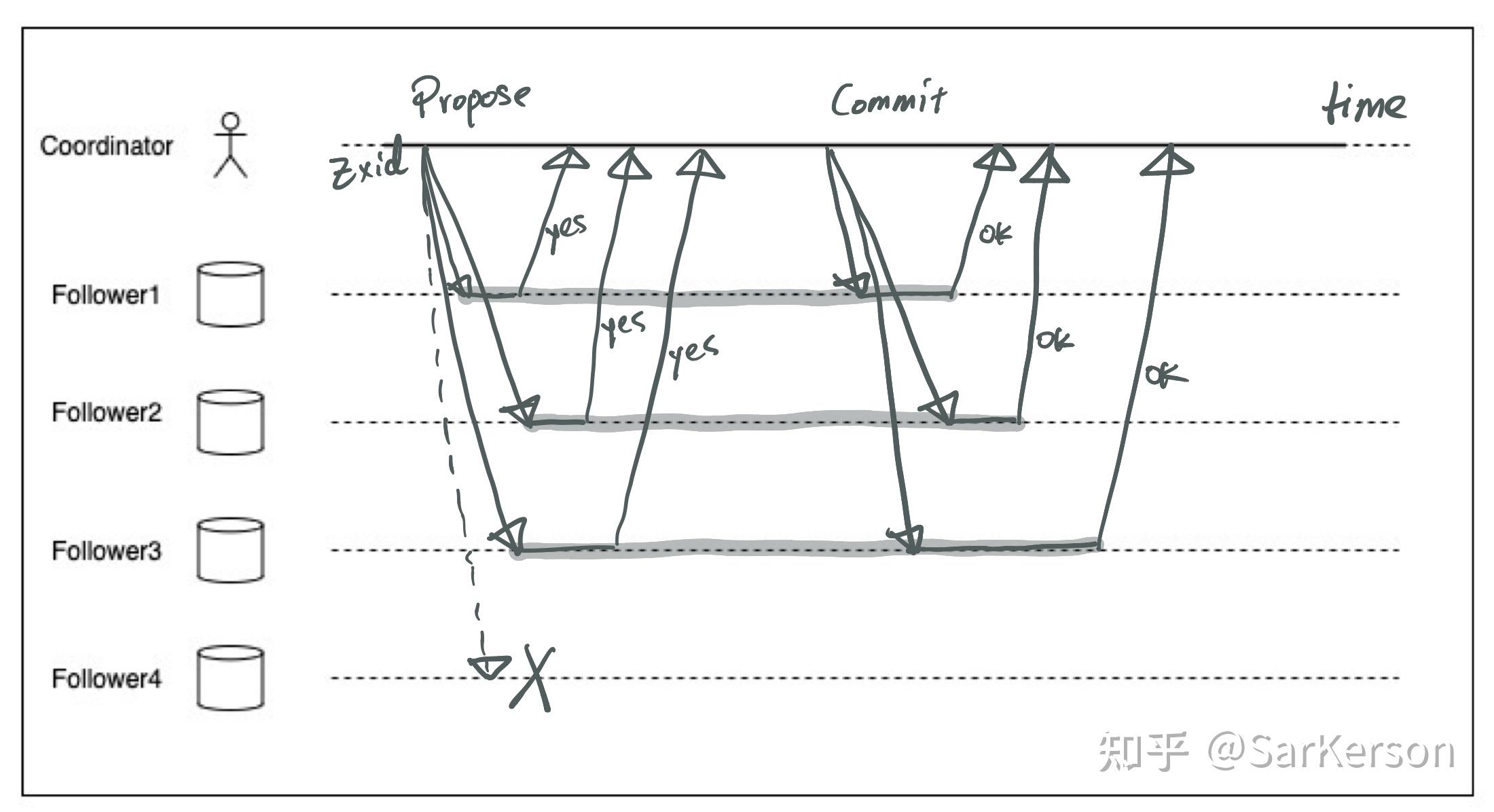
ZooKeeper 的消息广播过程类似于两阶段提交,针对客户端的读写事务请求,Leader 会生成对应的事务提案,并为其分配 ZXID,随后将这条提案广播给集群中的其它节点。Follower 节点接收到该事务提案后,会先将其以事务日志的形式写入本地磁盘中,写入成功后会给 Leader 反馈一条 Ack 响应。当 Leader 收到超过半数 Follower 节点的 Ack 响应后,会返回客户端成功,并向集群发送 Commit 消息,将该事务提交。Follower 服务器接收到 Commit 消息后,会完成事务的提交,将数据应用到数据副本中。
在消息广播过程中,Leader 服务器会为每个 Follower 维护一个消息队列,然后将需要广播的提案依次放入队列中,并根据「先入先出」的规则逐一发送消息。因为只要超过半数节点响应就可以认为写操作成功,所以少数的慢节点不会影响整个集群的性能。
各个阶段的写失败可以参阅上文的两阶段提交,其实是一样的。
崩溃恢复
Zab 集群使用Epoch(纪元)来表示当前集群所处的周期,每个 Leader 都有自己的任期值,所以每次 Leader 变更之后,都会在前一个Epoch的基础上加 1。Follower 只听从当前纪元 Leader 的命令,旧 Leader 崩溃恢复后,发现集群中存在更大的纪元,会切换为 FOLLOWING 状态。
触发时机:
- 当 Leader 节点出现崩溃中止,Follower 无法连接到 Leader 时,Follower 会切换为 LOOKING 状态,发起新一轮的选举;
- 如果 Leader 节点无法与过半的服务器正常通信,Leader 节点也会主动切换为 LOOKING 状态,将领导权让位于网络环境较好的节点。
Zab 协议需要在崩溃恢复的过程中保证下面两个特性:
- Zab 协议需要确保已经在 Leader 服务器上提交(Commit)的事务最终被所有服务器提交;
- Zab 协议需要确保丢弃那些只在 Leader 上提出但没有被提交的事务。
一致性分析
- 可线性化写:
Zookeeper 仅将写操作交给 Leader 串行执行,也就保证了写操作线性。
-
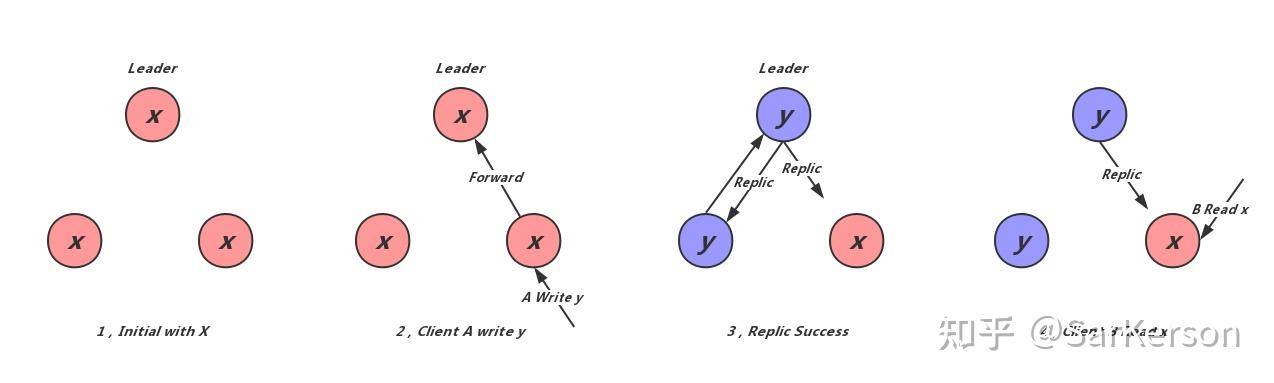
顺序一致性读
(没有满足可线性化的条件)
- 同一个 client 看到的是与 leader 相同的变更序列
- 不同 client 看到的值变更(时间)有可能不同
-
可线性化读:可以利用写操作的可线性化特性,在读取之前执行一个写操作。原理是,Zookeeper 给每个写入后的状态一个唯一自增的 Zxid,并通过写请求的 resp 告知客户端,客户端之后的读请求都会携带这个 Zxid,直连的 Server 通过比较 Zxid 判断自己是否滞后,如果是则让读操作等待。
Chubby
Ref [Chubby的锁服务 CatKang的博客](http://catkang.github.io/2017/09/29/chubby.html),thegooglechubbylockservice.pdf (uic.edu) Chubby provide coarse-grained locking as well as reliable storage for a loosely-coupled distributed system.(读多写少)
主节点选举
Chubby 实际上实现了 Multi-Paxos,其概要实现如下:
- 多个副本组成一个集群,副本通过一致性协议选出一个Master,集群在一个确定的租约时间内保证这个Master的领导地位;
- Master周期性的向所有副本刷新延长自己的租约时间;
- 每个副本通过一致性协议维护一份数据的备份,而只有 Master 可以发起读写操作;
- Master挂掉或脱离集群后,其他副本发起选主,得到一个新的Master;
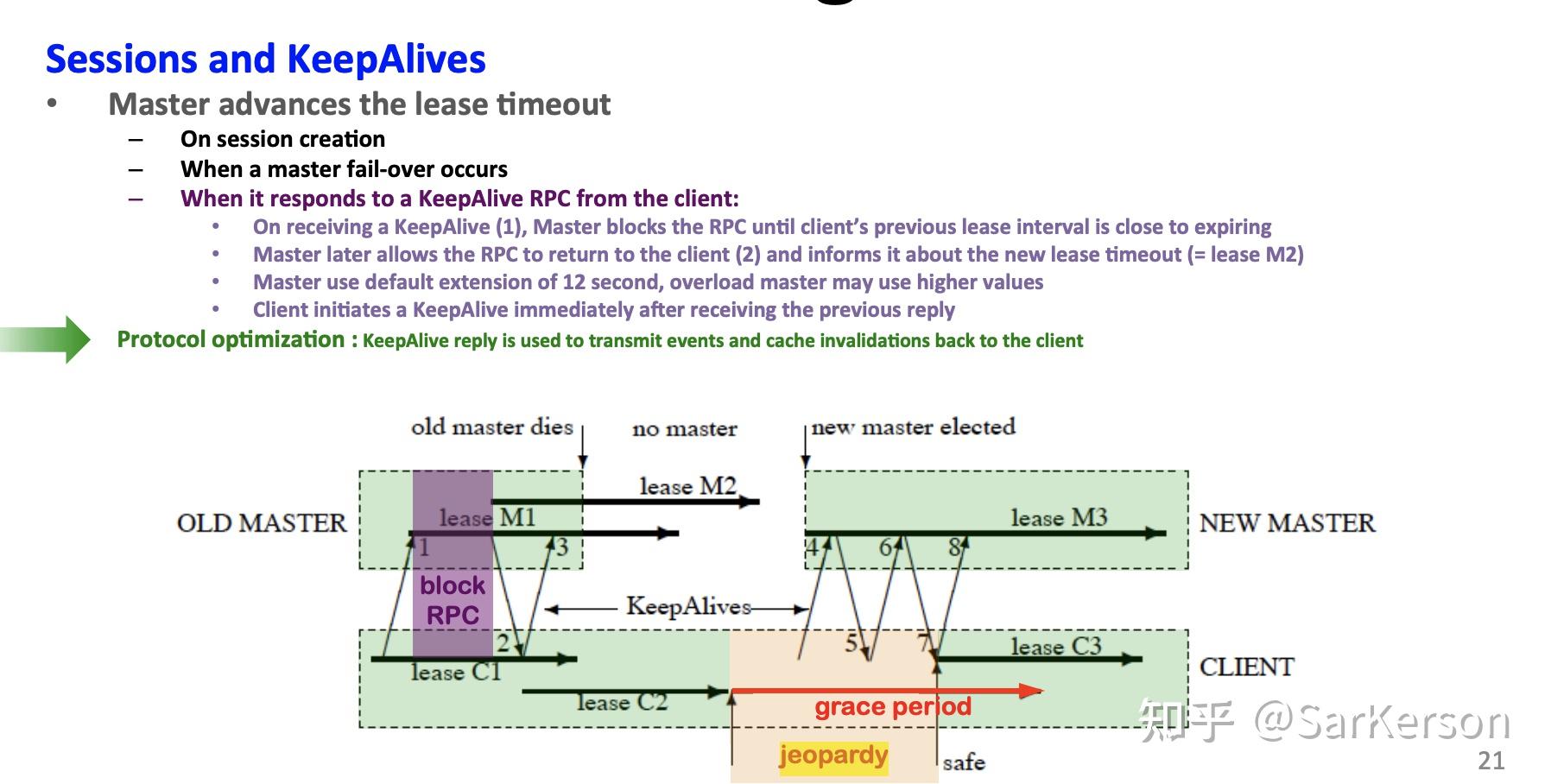
Session And KeepAlives
心跳时机:
- Master 和 Client 之间通过 KeepAlive 进行通信,初始化时 Client 发起 KeepAlive,会被 Master 阻塞在本地,直到Session租约临近过期,此时Master会延长租约时间,并返回阻塞的KeepAlive通知Client;
- 除此之外,Master 还可能在 Cache 失效或 Event 发生时返回 KeepAlive;
Cache
从这里开始要提到的 Chubby 的机制是对 Client 透明的了。Chubby 对自己的定位是需要支持大量的Client,并且读请求远大于写请求的场景,因此引入一个对读请求友好的 Client 端 Cache,来减少大量读请求对 Chubby Master 的压力便十分自然,客户端可以完全不感知这个 Cache 的存在。
Cache 对读请求的极度友好体现在它牺牲写性能实现了一个一致语义的Cache:
- Cache 可以缓存几乎所有的信息,包括数据,数据元信息,Handle 信息及 Lock;
- Master 收到写请求时,会先阻塞写请求,通过返回所有客户端的 KeepAlive 来通知客户端 Invalidate 自己的 Cache;
- Client 直接将自己的 Cache 清空并标记为 Invalid,并发送 KeepAlive 向 Master 确认;
- Master 收到所有 Client 确认或等到超时后再执行写请求。(如果超时的话,会导致两个 client 同时持有锁吗?——租约)
Fail-over
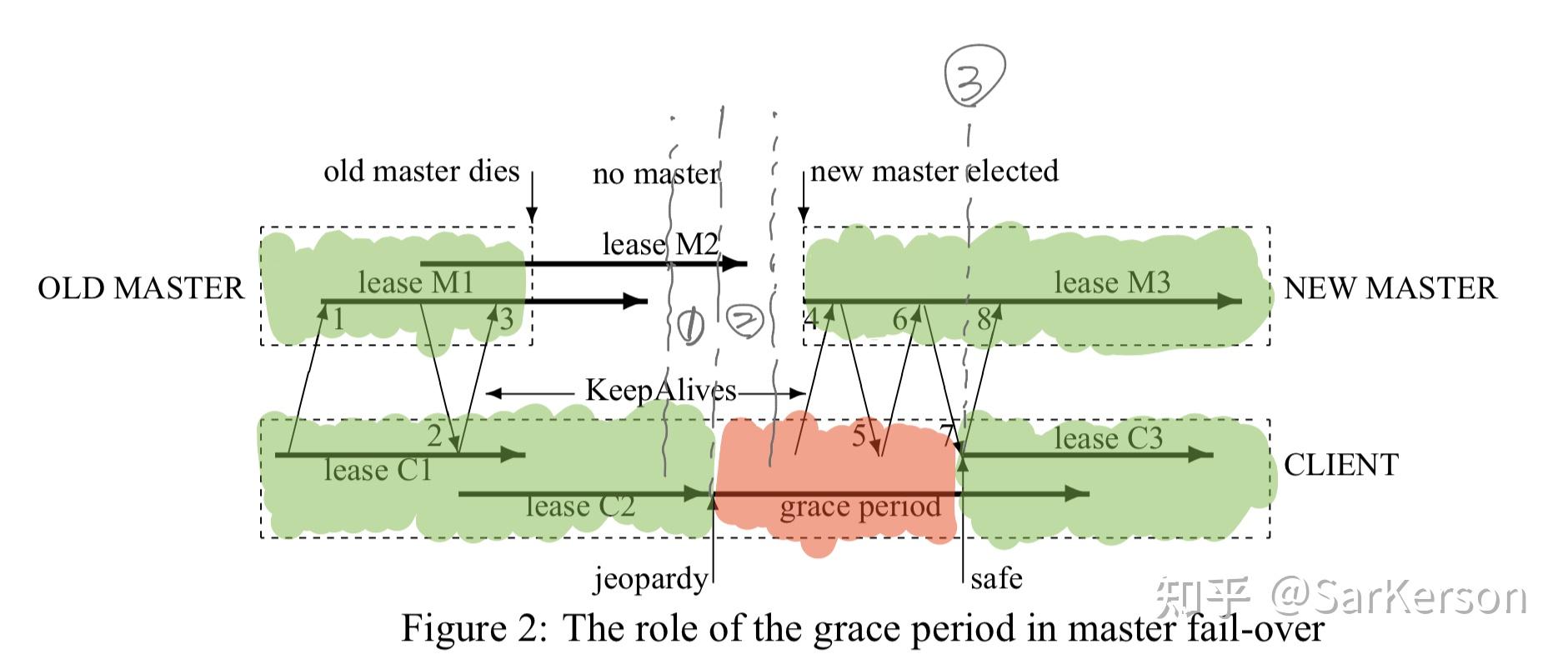
这里的多个临界条件,有没有可能存在锁冲突问题? 下面进行分析
- lease C2 还在,该 client 可以正常获取锁;lease M2 还在,其他 client 不能获取锁;
- lease C2 不在,该 client 不可以获取锁;lease M2 还在,其他 client 不能获取锁;
- 新 master 启动,
- 选择新的 epoch,拒绝老 epoch 的所有 client 请求
- 与客户端重新建立 session,并携带新 epoch,将所有 client cache 置为失效状态
- 等待 client ack,若某 client 超时则终止其 session(保证了该时刻,所有有效 client 状态一致)
- 单 master 模型保证了竞争锁的 client 有且只有一个成功
一致性分析
- 可线性化:相当于「主从复制」模型,所有的读写操作都是走主节点来解决,实际上也实现了「全序关系广播」。
Zookeeper VS Chubby
先看看两者的定位:
-
Chubby:provide coarse-grained locking as well as reliable storage for a loosely-coupled distributed system.
-
Zookeeper:provide a simple and high performance kernel for building more complex coordination primitives for the client.
可以看出,Chubby 旗帜鲜明的表示自己是为分布式锁服务的,而 Zookeeper 则倾向于构造一个“Kernel”,而利用这个“Kernel”客户端可以自己实现众多更复杂的分布式协调机制。自然的,Chubby倾向于提供更精准明确的操作来免除使用者的负担,Zookeeper 则需要提供更通用,更原子的原材料,留更多的空白和自由给 Client。也正是因此,为了更适配到更广的场景范围,Zookeeper 对性能的提出了更高的要求。
一致性
- Chubby:线性一致性(Linearizability)
- Zookeeper:写操作线性(Linearizable writes) + 客户端有序(FIFO client order)
Chubby 所要实现的一致性是分布式系统中所能实现的最高级别的一致性,简单的说就是每次操作时都可以看到其之前的所有成功操作按顺序完成,而 Zookeeper 将一致性弱化为两个保证,其中写操作线性(Linearizable writes)指的是所有修改集群状态的操作按顺序完成,客户端有序(FIFO client order)指对任意一个client来说,他所有的读写操作都是按顺序完成。
分布式锁
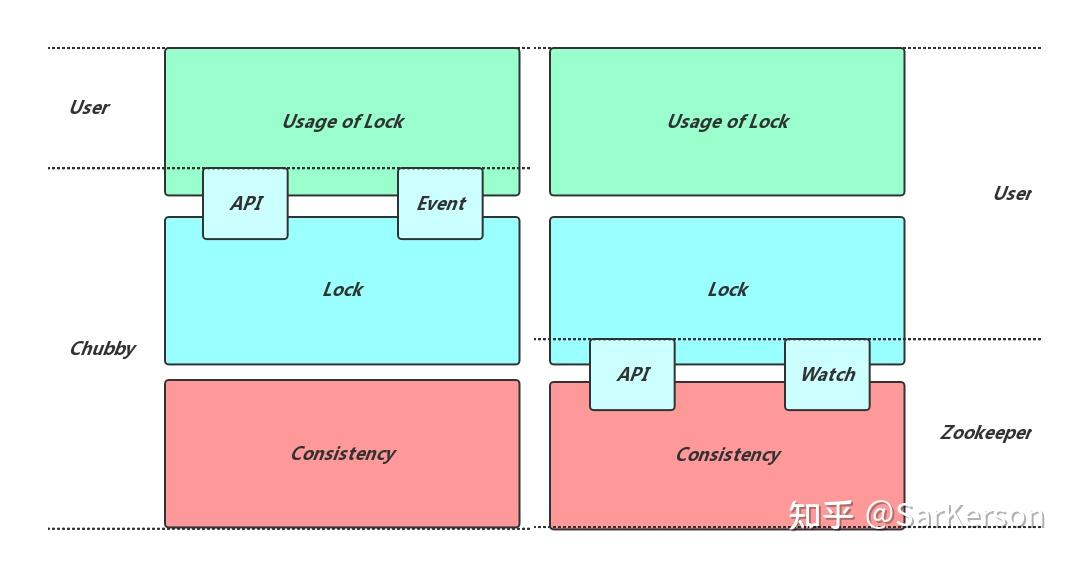
- Chubby:提供准确语义的Lock,Release操作,内部完成了一致性协议,锁的实现的内容,仅将锁的使用部分留给用户;
- Zookeeper:并没有提供加锁放锁操作,用户需要利用Zookeeper提供的基础操作,完成锁的实现和锁的使用部分的内容;
Netflix created curator library which later moved to Apache foundation, this library provides the commonly used functionality and cache management. This additional layer to zookeeper allows it providing strong consistency needed by some users. So whenever you want to use zookeeper, use curator library instead of native library unless you know what you are doing.
What about the RedLock Problem?
回到一开始的问题,redlock 的问题,zookeeper、chubby 能否解决呢?
一个正确的算法一旦返回结果,那必须是正确的结果,这点 zk、chubby 都可以保证(例如 zk 在 commit point 的时候,多数节点状态达成一致;chubby 维护一致性 cache 保证所有正常 client 状态一致);而 redlock 需要对返回的结果基于不可靠的时间进行判断,因此本身也是”neither fish nor fowl”
另外,Redis 锁需要自己实现续租逻辑,而 zk、chubby 不需要(使用 keepalive 长连接实现)。
一些与共识等价的问题
我们看到,达成共识意味着以这样一种方式决定某件事:所有节点一致同意所做决定,且这一决定不可撤销。通过深入挖掘,结果我们发现很广泛的一系列问题实际上都可以归结为共识问题,并且彼此等价(从这个意义上来讲,如果你有其中之一的解决方案,就可以轻易将它转换为其他问题的解决方案)。这些等价的问题包括:
线性一致性的 CAS 寄存器
寄存器需要基于当前值是否等于操作给出的参数,原子地决定是否设置新值。
原子事务提交
数据库必须决定是否提交或中止分布式事务。
全序广播
消息系统必须决定传递消息的顺序。
锁和租约
当几个客户端争抢锁或租约时,由锁来决定哪个客户端成功获得锁。
成员/协调服务
给定某种故障检测器(例如超时),系统必须决定哪些节点活着,哪些节点因为会话超时需要被宣告死亡。
唯一性约束
当多个事务同时尝试使用相同的键创建冲突记录时,约束必须决定哪一个被允许,哪些因为违反约束而失败。
Reference
- Distributed locks with Redis – Redis
- How to do distributed locking — Martin Kleppmann’s blog
-
[Is Redlock Safe? Reply to Redlock Analysis Hacker News (ycombinator.com)](https://news.ycombinator.com/item?id=11065933) - The Chubby lock service for loosely-coupled distributed systems.
- 第九章:一致性与共识 · ddia-cn (gitbooks.io)
- Paxos:Paxos lecture(Recommended) + Paxos Wikipedia + Paper(optional)
- 漫谈分布式共识算法与数据一致性 - beihai blog (wingsxdu.com)