GraphQL:A Backend Engineer’s Perspective
TLDR;本文是一个对 BFF 思想的学习与调研,也对业界经常用来实现 BFF 的 GraphQL 进行一些介绍。本文重点在于对业界方案进行的调研与小结,并在文末总结一种可以实践的 BFF 思路。
概述
有些人觉得 GraphQL 与微服务思想相悖,其观点在于中心化与去中心化。
但本人认为,GraphQL 思想与微服务(确切来说是领域服务)是不谋而合的,服务端可以更加面向领域对象编程,而非面向场景编程,因为借鉴该思想,服务端可以省去了维护面向场景的聚合逻辑,可以更加关注领域服务的开发。
GraphQL vs RESTful
这里简单介绍一下 GraphQL 的思路。在 Web 服务器中,RESTful 应该是最常见的规范。在这里通过简单的对比 RESTful 与 GraphQL 的区别,来介绍什么是 GraphQL,以及为什么需要它。
下面举了一个简单的例子,一个页面需要获取多个数据来进行渲染:
-
左图是经典的 RestFul 的做法,请求多个接口进行拼凑;
-
右图是 GraphQL,只有一个 path,通过类似 SQL 思想的 query 来获取数据;
因此 GraphQL 的名字非常生动形象,抽象了从多种异构存储或者服务中获取数据的过程。
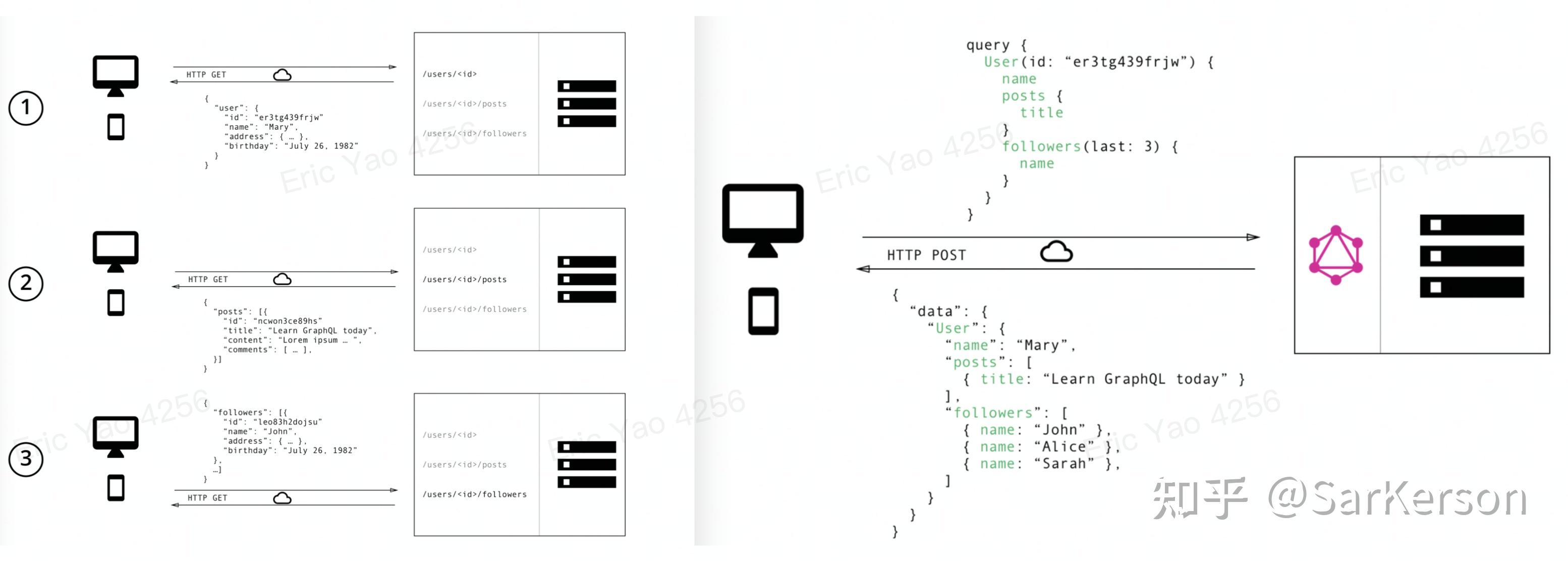
下面简单介绍 GraphQL 对于 RestFul 的一些优劣。
| GraphQL 优劣讨论 | 优点 | 缺点 |
|---|---|---|
| 宏观 | 服务端倾向于提供单一职责服务(微服务+领域驱动设计) | URI 对应资源路径,传统的 RestFul 对每个场景使用单独的 URI 获取对应资源 |
| 开发体验-前端 | 只需要请求一个接口,并且请求参数是直观的,按需取数后端自动处理路由逻辑,前端不需要执行多个请求有开源工具自动生成接口文档,不需要担心接口文档没有维护、更新 | |
| 开发体验-服务端 | 更加专注领域服务的构建,而不是面向场景编程,提高领域层逻辑的复用不需要关注接口应该拆分还是聚合的问题,职责交给网关不需要配置很多路由 | 原生 GraphQL 对每种展示字段需要新开辟一个字段解决(或者将逻辑下沉到终端,但是又缺少了灵活性)对于复杂业务,数据图可能非常大 |
| 性能 | 避免返回不必要字段耗费带宽避免 n+1 问题(fetch list + n * get(item)) | |
| 稳定性 | 内容聚合大大减少了 API 请求的次数,比如数据字段可选大大减少无用流量的传输schema 文件中的强类型,极大的降低程序 crash 的风险。 | 没法基于场景进行以下监控或者操作,只能基于字段超时控制:不同场景下,相同字段超时可能存在区别流量监控:基于场景的流量监控是刚需熔断机制:基于字段的熔断可能导致误伤 |
| 鉴权 | GraphQL 内置的 Directives 模块可以进行权限控制,包括字段级别,对象级别,接口级别,颗粒度非常细;RESTful 正常情况下只能做到路由级别的权限控制,接口里面的字段难以进行分级控制; | |
| 容灾 | CDN:同样可以实现基于 query 的缓存 | 限流:基于场景的限流是刚需 |
现有问题
下面列举了一些现有开发中常见的问题,这些问题可以直接使用 GraphQL,或者借鉴 GraphQL 的思路来解决。
前后端协同
-
微服务演进过程中,后端服务/接口骤增,客户端/前端开发需求时,单个页面进行多次请求后端服务,开发效率低下且数据加载时延较高,页面偏卡顿;
-
前端期望接口自由请求数据以进行快速迭代,而不需要等待服务端将新接口上线(对于那些已经有打包逻辑的领域对象);
-
服务端的数据模型在版本迭代中,会越来越膨胀,因为它相当于多个版本数据的一个并集,不同版本使用数据模型中的不同字段;
-
服务端往往在适配客户端/前端不同需求时,需要对数据进行加工,导致服务端掺杂UI逻辑,边界不清晰,不能更好的专注于领域逻辑;
-
对于不同版本的客户端,服务端需要做非常多的兼容逻辑,导致维护成本较大;
微服务职责划分
由于微服务架构的广泛应用,数量非常容易膨胀。这些微服务要么职能过于扁平,比如专门提供各种计数;要么职能过多,彼此之间存在交叠,比如多个内容服务提供了用户数据、作者数据、评论数据。
另外,传统的面向场景编程,如果设计不当,很容易陷入领域对象与场景对象划分的纠结之中。比如说,文章详情页这个场景,返回给前端的场景对象,是否要直接使用文章的领域对象,通常来说两者应该隔离开,使用两个不同的对象进行处理。但是,对于没有经验的工程师来说,通常会陷入二者的界线划分的难题之中,一旦划分失误,那么领域层将避免不了耦合一些场景层的展示逻辑。
打包服务
打包服务通常作为一个聚合服务存在,有点类似网关,通过请求指定所需的字段,从各种异构数据源获取数据,并打包为协议定义的对象。
传统的打包服务流程大致如下:
-
通过 loader manager 定义该 pack 请求的下游依赖,构成 loader 的 DAG 图;
-
执行所有 loader 进行数据获取,将数据放到透传上下文 datum 中;
-
所有 loader 执行完毕(或者超时),执行 packer 的打包逻辑,将 datum 映射为 packed doc;
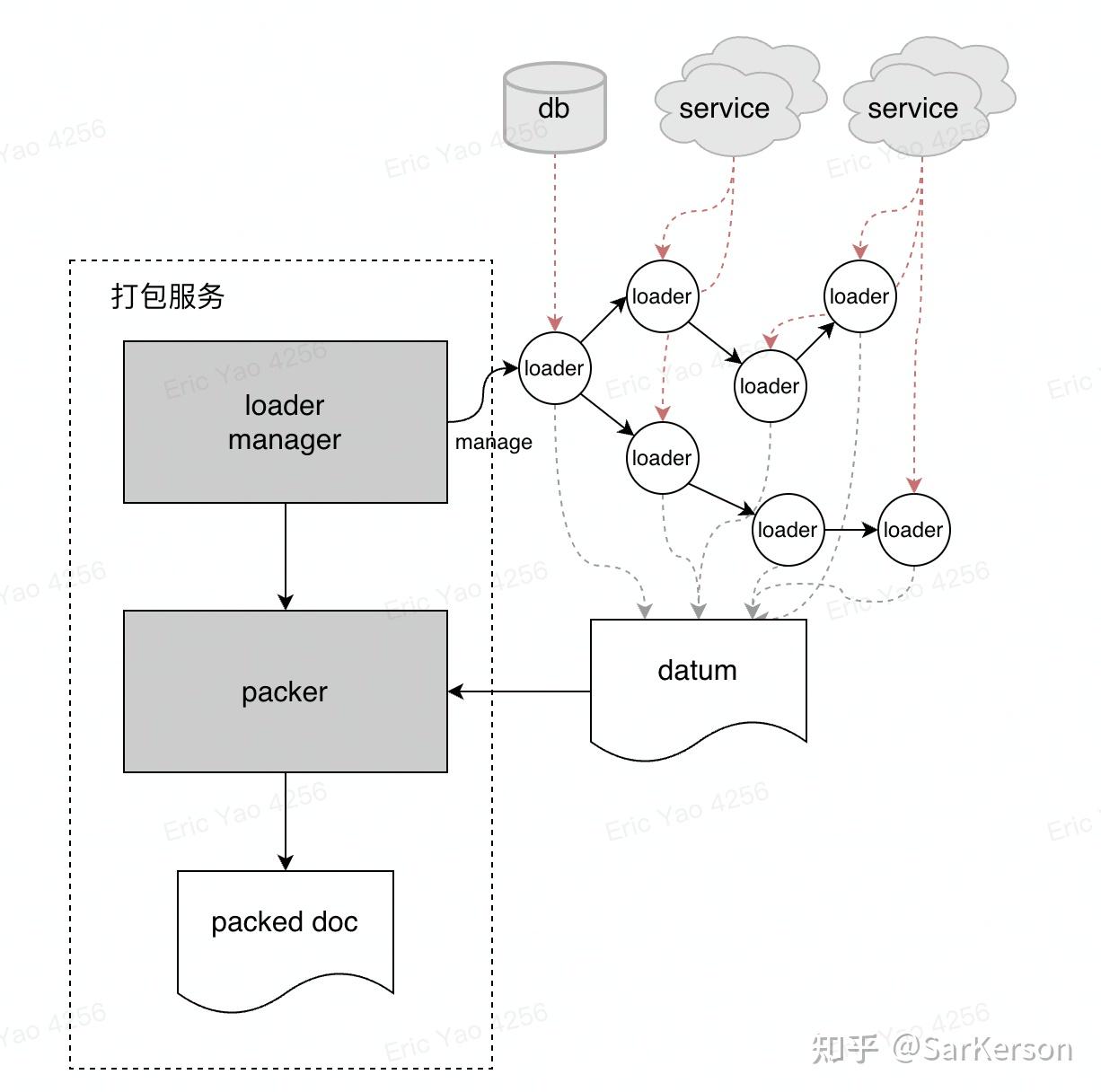
但是,这样的做法存在一些问题:
选择性打包
典型的基于 pack fields 的选择性打包,通常需要在代码层对每个 field 进行依赖的编排逻辑,会导致代码非常冗长。而如果对 field 进行分组,类似抖音的 pack level,则粒度又过大。
字段依赖
上述打包流程中,我们需要手动维护 loader 之间的依赖图。理想的做法是,通过指定每个字段对应的领域服务及对象依赖,自动解决依赖编排逻辑。
超时机制
典型的基于 loader_manager 的超时机制,粒度太大,因为各个子 loader 的超时可能不同,取决于子 loader 里面耗时最长的那个。但这个超时不好确定,一旦定不合理,比如说为了某一个短板 loader 而调高耗时,很容易导致上游拿不到整个数据。
维护成本
上面可以看到,loader 与 packer 的逻辑是解耦开的。这意味着,如果要修改某个 packed doc 返回值字段,你需要去定位该字段来自 datum 的哪个值,datum 这个值又是在哪个 loader 赋值的。而基于 GraphQL 的思想,则可以将字段的赋值逻辑收敛在 resolver 中,一定程度上可以降低维护成本。
字段权限控制
目前只有接口级别的权限控制,希望细化到字段 => psm 的维度的细粒度鉴权。
服务治理
通常业务会倾向于复用接口来提供服务,比如信息流会使用同一个 path 提供数据,根据入参进行业务逻辑编排。
但是这样也引入了一个问题,很难对具体的类型进行不同的超时处理。并且,针对具体的请求也很难统一进行一些埋点监控。
区分当前服务处理错误,与上游服务调用该服务处理超时。
当然埋点监控可以通过在入口层统一使用中间件来解决。但是对于超时处理、熔断,则难以复用 mesh 的服务治理能力。
业界方案
美团
https://tech.meituan.com/2021/05/06/bff-graphql.html
美团的思路比较优雅,但是私以为文章描述不是很清晰,这里尽所能对各个模块进行介绍。
取数展示分离
All problems in computer science can be solved by another level of indirection.
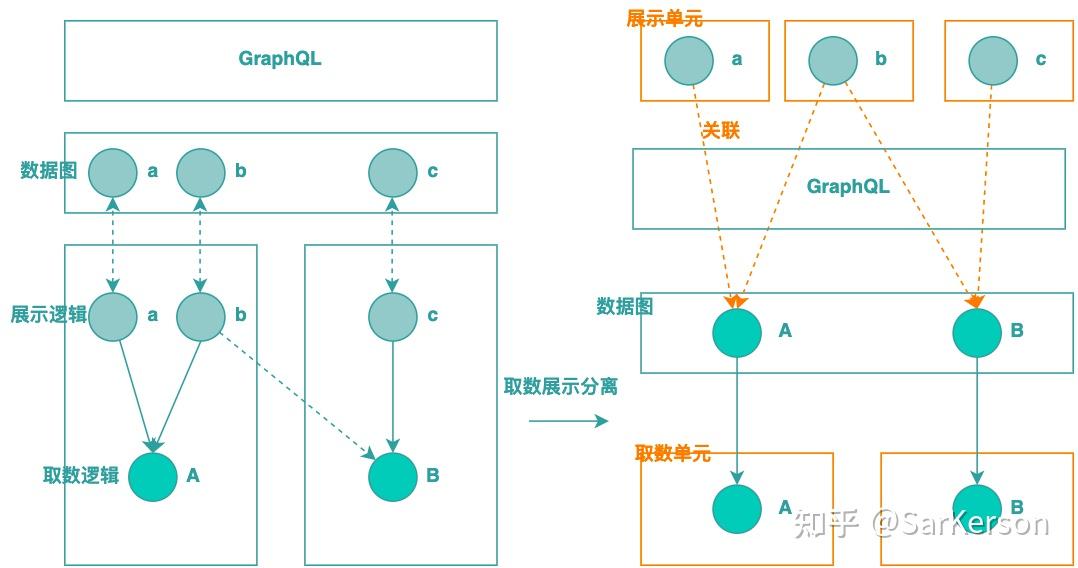
主要目的在于,避免在数据图中,混入展示层的逻辑。
传统的 GraphQL 方案中,每个 field 对应相应的 resolver,通常也需要对应单独的取数 / 打包,这样必然导致数据图非常大,而且其中包括很多冗余字段(比如 title、category、title_with_category 同时存在)。
通过取数和展示的分离,元数据的关联和运行时的组合调用,可以保持逻辑单元的简单,同时又满足复用诉求,这也很好地解决了传统方案中存在的展示服务的颗粒度问题。
相当于,GraphQL 充当了字段计算的职责,数据图负责更原子化的数据获取,这某种意义上也使得领域服务职责更加清晰及稳定。
查询模型归一
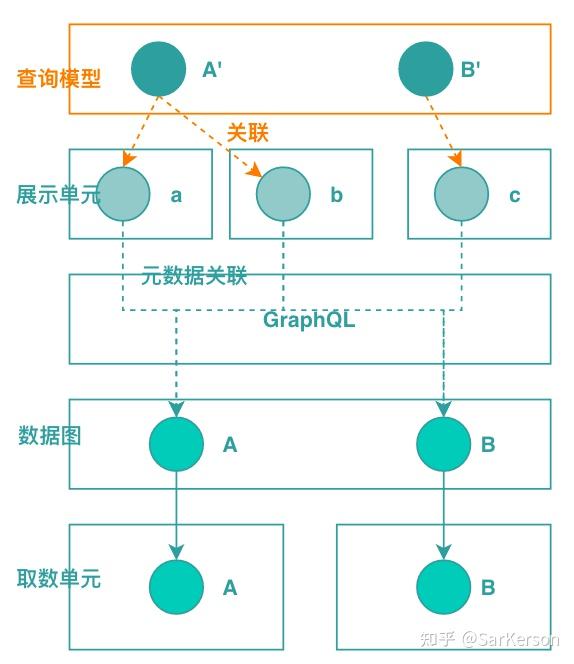
每个查询模型相当于一个场景。
私以为,查询模型相当于 schema(命名、类型、映射),并且每个字段维护一个映射(查询模型 => 展示单元),相当于一段动态代码,标识一个该场景的字段的计算逻辑。
查询模型可能会膨胀,比如描述某个场景下一个商品的模型,可能包含很多字段,通过标准字段 + 扩展属性的方式建立查询模型,能够较好地解决字段扩散的问题,类似于头条的内容云 optional_data。
其中,查询模型是多变的(不同版本、不同终端),展示单元变化较小,数据图变化非常小。
相当于,通过查询模型,解决了场景快速迭代与领域模型相对稳定的矛盾。
元数据驱动
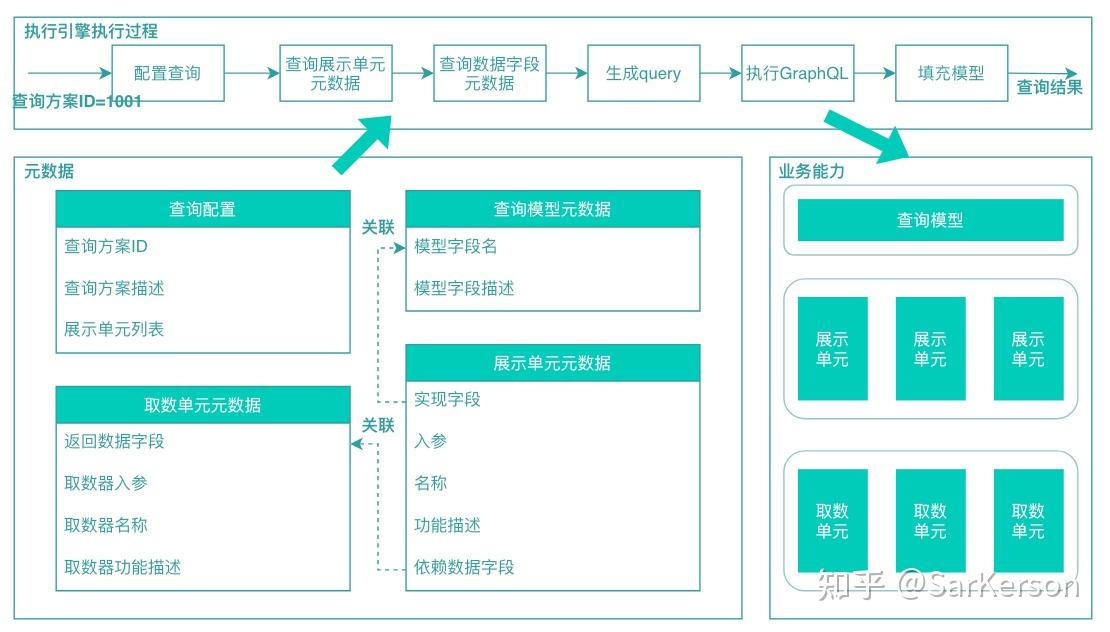
整体架构由三个核心部分组成:
-
业务能力:标准的业务逻辑单元,包括取数单元、展示单元和查询模型,这些都是关键的可复用资产。
-
元数据:描述业务功能(如:展示单元、取数单元)以及业务功能之间的关联关系,比如展示单元依赖的数据,展示单元映射的展示字段等。
-
执行引擎:负责消费元数据,并基于元数据对业务逻辑进行调度和执行。
所谓元数据驱动,无非描述一个查询模型的取数链路,查询模型 => 展示单元 => 取数单元。
不过,为每个模块记录一个元数据是有意义的,
-
方便可视化,给定一个查询模型,可以很方便查看其 schema 及查询链路
-
减少维护接口协议、接口文档的烦恼
-
低代码化,可以将其平台化,通过创建元数据搭建整条链路的实现
AirBnb
Eng https://medium.com/airbnb-engineering/reconciling-graphql-and-thrift-at-airbnb-a97e8d290712 中文版 https://juejin.cn/post/6844903698544459784
总结一下,AirBnb 在 GraphQL 架构中主要有两点可以参考:
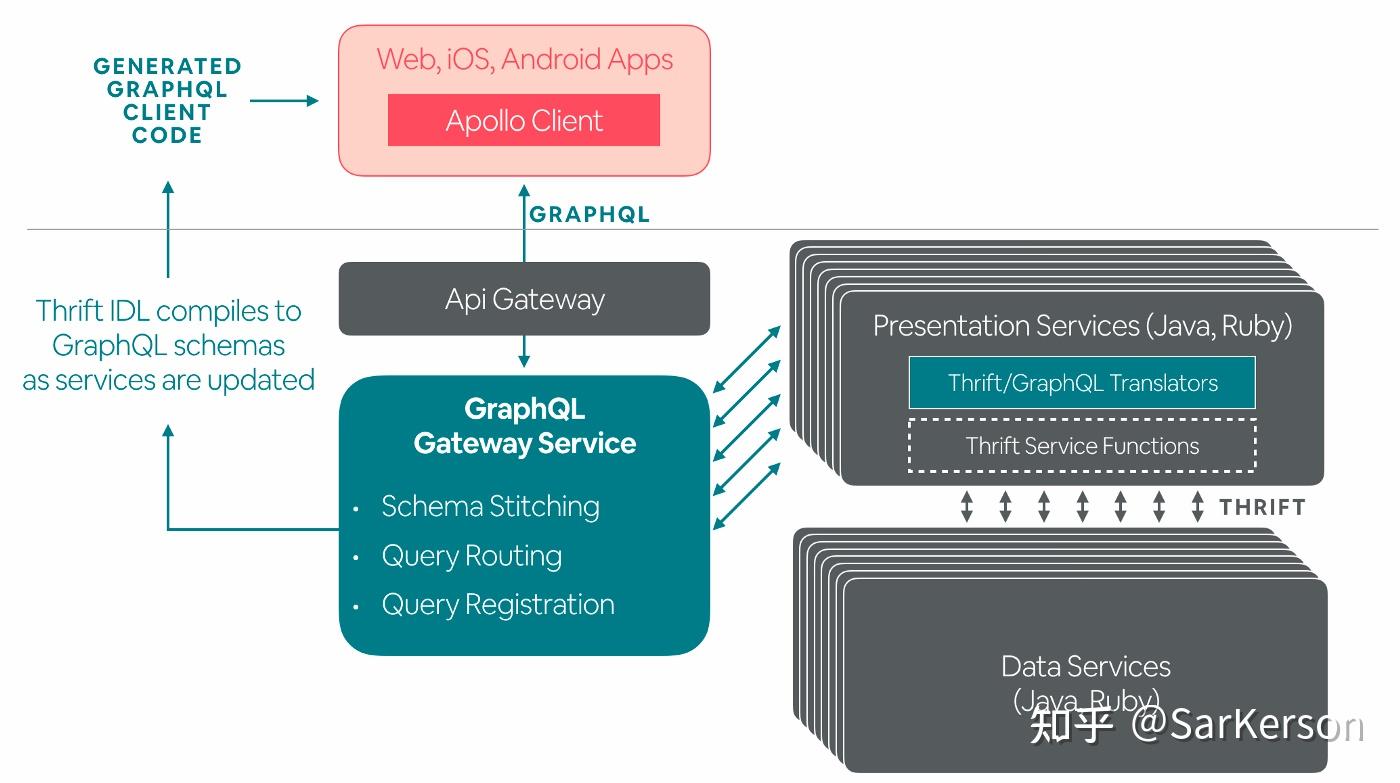
GraphQL 网关
AirBnb 直接使用 GraphQL 作为网关,承担以下职责:
-
聚合 Schema:将所有展现服务层的 GraphQL Schema 聚合在一起形成一个单一的 Schema。网关在初始化的时候获取和解析所有展现服务层的 GraphQL Schema,并将他们合并在一起,同时通过轮询来监听 Schema 的变化。
-
路由:将 GraphQL query 转发到相应的展现服务层去执行。
-
Query 注册:每个生产环境使用的 Query 都会注册生成一个 UUID。一是提高安全性,只有被注册过 query 才能在生产环境中执行;二是客户端不用每次都发送冗长的完整的 GraphQL query,只需使用 query 注册时生成的 UUID 即可。
Thrift/GraphQL 转换器
Thrift/GraphQL 转换器应用在展示层。在 AirBnb 的架构中,展示层处于网关层的直接下游的位置。
所有的 GraphQL 查询逻辑和 schema 定义全部都是通过展现服务层定义的 Thrfit 自动构建出来的。如果想让自己负责的展现服务层支持 GraphQL,只需把转换器模块包含进来即可。
头条直播
直播的 packer 很有 GraphQL 特色,通过定义每个字段的 resolver 来确定字段的打包逻辑,一个 resolver 可能包含一个或多个 loader。然后根据 IDL 生成的 graph 来确定请求 field 的依赖,只加载对应的数据。
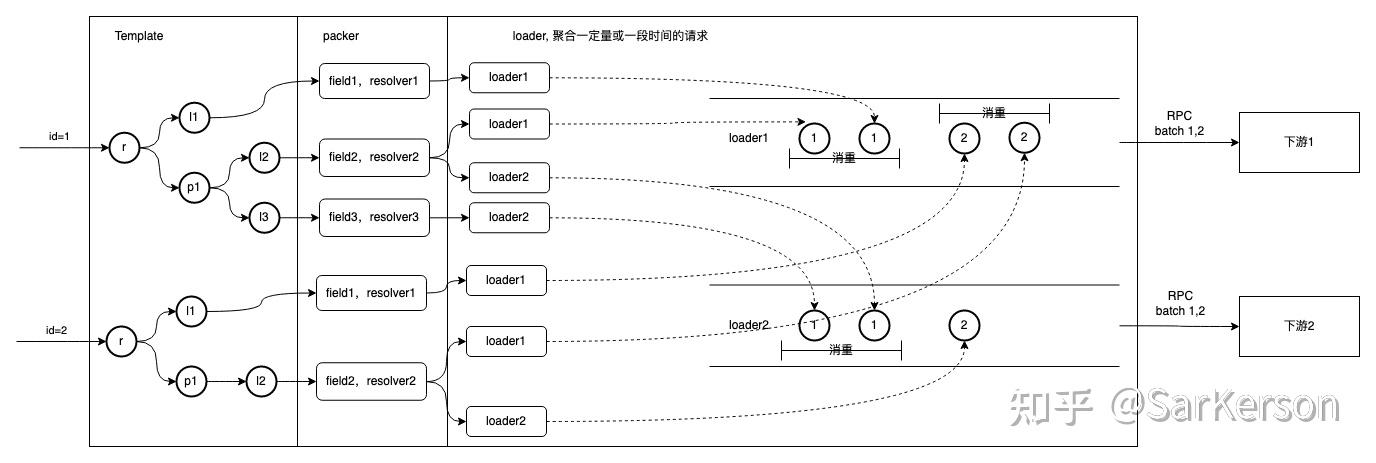
- 优点:
- load、pack 逻辑内聚在字段内,易于理解和维护
- 底层基于 dataloader 实现了 batching/caching 能力,减少调用次数,对下游友好
- field 维度的数据粒度,只请求必要数据,不做冗余加载
- 缺点:
- 使用了 dataloader 的基于时间窗口 batching 能力
- 如果一个批量请求的 load 被聚合到不同批次,会导致接口延时增大
- 打破原有 logid 的链路,会导致问题追溯变复杂
- 每个字段都需要维护一个 resolver,组织较清晰,但是代码量相对较大
- 使用了 dataloader 的基于时间窗口 batching 能力
可改进点
问题:对于同一个请求,不同字段可能依赖同一个下游数据,如果每个字段的 resolve 逻辑都单独调用一次,则会导致很多重复请求,造成读放大。因此直播使用了开源的 dataloader 来实现,会导致 batching 不同会话的请求。
解决:同一个会话共用一份缓存。将数据加载缓存在 context 中,如果已经有数据,则不必重复请求,并且 context 会随着会话终结而释放进行回收。
展望与总结
结合业界多个业务在 GraphQL 方面的实践,这里做一个小结。私以为,借鉴美团元数据管理的思路,是一种很好的解决思路。原因有二,一方面能够有效将变动最频繁的逻辑进行配置化管理,另一方面能够沉淀并充分复用领域层的业务逻辑。
另外,如果能顺便借鉴 AirBnb 把 query 进行注册并且在平台配置对应 gql,那么一方面可以防止端上请求不规范,另一方面可以实现动态修改 gql 而不需要客户端发版,可以在 proxy 层做一些骚操作。
实际上,上述两者完全可以相结合,下面描述一种 BFF 网关思路:
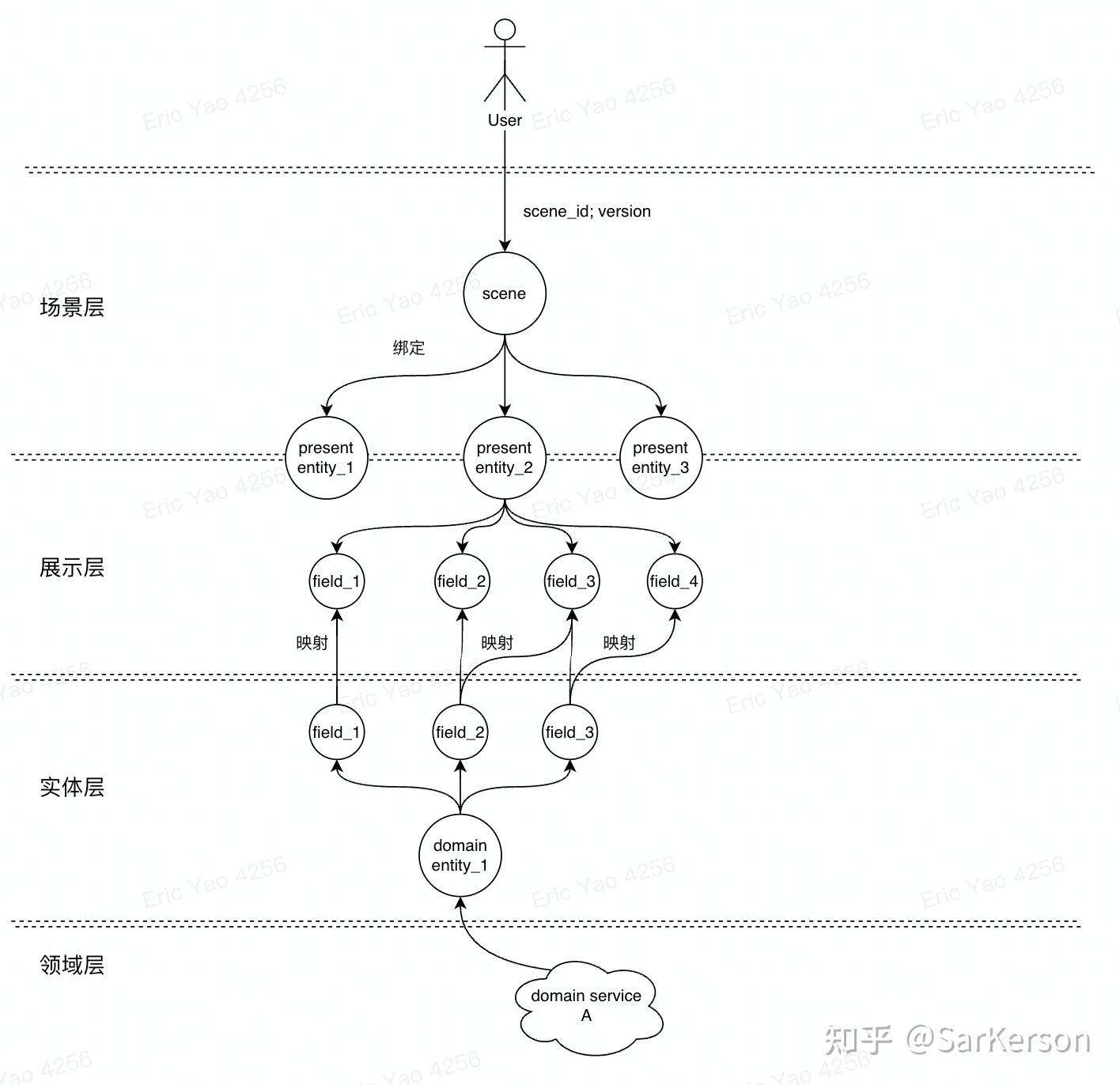
注:上图场景层/展示层/实体层都是提供一个平台进行管控。
场景层
-
场景层可以对业务线的场景进行注册、管理
-
每个场景对应一个客户端/前端页面,具有唯一标识,并且有版本的概念
-
每个场景绑定多个展示层实体 entity,可以通过 GraphQL 实现,进行字段裁剪或者 mapping,但不进行额外计算,如果需要额外计算,则可以新增字段实现,这有利于展示逻辑的沉淀
可以看到,场景层类似 AirBnb 的思路,通过 scene_id+version 确定一个 gql
展示层
-
展示层用于注册、管理展示实体
-
每个展示实体有多个字段,每个字段对应一个或多个领域实体字段;并可以选择直接赋值,或通过映射函数做计算,映射函数可以是 built-in 或者 customized
-
这里可以使用 GraphQL 实现,也可以使用其他方式
-
可以查看每个展示实体、以及具体字段的上层依赖,以此来提醒你某个展示层配置的影响范围
领域实体层
-
领域实体层用于注册、管理领域实体,你可以在此看到系统中所有领域实体的信息、描述
- 每个领域实体有多个字段,从一个指定的领域服务中获取
- 不建议从多个领域服务获取,这样做说明领域划分可能存在问题,并且可能造成读放大
- 可以查看每个领域实体、以及具体字段的上层展示、场景依赖,以此来提醒你某个 MR 修改的字段的影响范围
领域层
-
领域层即各个执行领域逻辑的微服务
-
领域服务的打包,可以借鉴直播的思路,将 load/pack 逻辑内聚,并通过上文提到的基于 context 的会话缓存来避免重复请求
一些想法
公共依赖
某些场景下,一个场景可能会关联的多个领域服务,这些领域服务可能有公共依赖,那么,场景层应该借鉴 AGW Loader 的思路,每个场景层可以配置多个 Loader,并提供可插拔的 built-in / customized 的公共依赖加载能力,通过 context 的透传能力透传到下游,或者在上述各个层级的入参配置进行引用从而达到透传的目的。
架构中的定位
对于列表场景,入口层可以是应用服务作为上游,此时 BFF 网关作为一个聚合打包服务,可以应对复杂打包场景,例如抖音 Pack 在架构中的位置。
而对于 item 场景,入口层可以是 TLB 作为上游,此时 BFF 网关作为一个网关,例如 AGW/Janus 在架构中的位置。
现阶段的一些建议
- 区分场景层实体与领域层实体。举个例子:
type IdeaDetail struct { // 对文章的点亮(类似笔记)
IdeaId int64
IdeaAuthor *Author
IdeaContent string
// ...
Post *Post // 文章
Group *Group // 文章所在小组
}
type IdeaDetail struct { // 对文章的点亮(类似笔记)
Idea *Idea
Post *Post // 文章
Group *Group // 文章所在小组
}
type IdeaMeta struct {
IdeaId int64
PostId int64
GroupId int64
AuthorId int64
}
type Idea struct {
IdeaId int64
IdeaAuthor *Author
IdeaContent string
// ...
}
左边的实体 IdeaDetail 其实是场景层实体,领域层不应该直接使用该实体作为打包对象,而是通过外键的方式,抽离一个中间的 IdeaMeta,场景层直接关联具体的领域层对象或者展示层对象(如果能细化到展示层当然更好),这样的话,每个领域服务只需要打包所在上下文的数据(Idea 领域打包 Idea 的,Post 领域打包 Post 的…),不需要关心其他上下文数据。
而抽离出的 IdeaMeta,便是上文提到的场景层公共依赖 Loader 思路。
-
区分展示层逻辑与领域层逻辑。举个例子:文章内容是领域层逻辑,基于文章内容计算的简介是展示层逻辑;图片 URI 算领域层逻辑,基于 URI 打包的 URL 是展示层逻辑。
-
划分好领域上下文,这是一个大话题,可以参考领域驱动设计相关书籍。
另外注意,上述三层能力中,每一层都可以通过提供 RPC/HTTP 形式的 OpenAPI 对外提供能力。
以上如果有疏漏,也欢迎批评指正。
Reference
-
https://www.howtographql.com/basics/1-graphql-is-the-better-rest/
-
https://tech.meituan.com/2021/05/06/bff-graphql.html
-
https://medium.com/airbnb-engineering/reconciling-graphql-and-thrift-at-airbnb-a97e8d290712