信息流系统设计
TL;DR; 本文以关注流为例子,介绍了几种信息流的实现方案,并对比其优缺点,介绍了各自适合的应用场景。并归纳了信息流领域常见的幻读、不可重复读问题,参考数据库隔离级别实现的思路,提出对应的两个解决方案。
信息流(或称 Feed 流)这种功能在我们手机 APP 中几乎随处可见,最典型的就是微信朋友圈、Twitter 等。
但是对于推荐流跟关注流这两种 Feed 流,它们背后用到的技术架构差别会比较大。不同于基于模型排序的推荐流,关注流通常基于时间线来排序,用户对数据的完整性和排序都比较敏感。
push mode
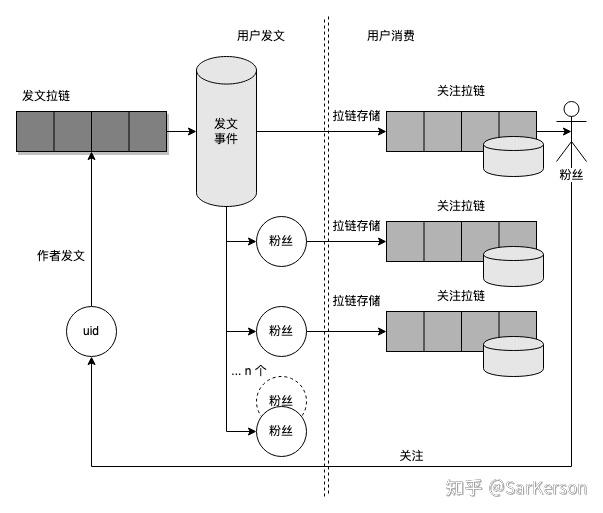
push mode 对每个粉丝维护一个「关注拉链」的存储;每当关注的用户有新动态(发文、评论等)时,则将动态离线写入其粉丝的「关注拉链」存储中。
用户发文时,遍历所有的粉丝,将文章写入所有粉丝的「关注拉链」存储中。
用户消费信息流时,直接从「关注拉链」中读取即可。
好处: 读帖简单;
坏处: 发帖复杂,存在写扩散问题;大 v 粉丝量多时存在性能;
适用场景: 用户活跃,经常刷帖;无大 v,用户粉丝量少;
pull mode
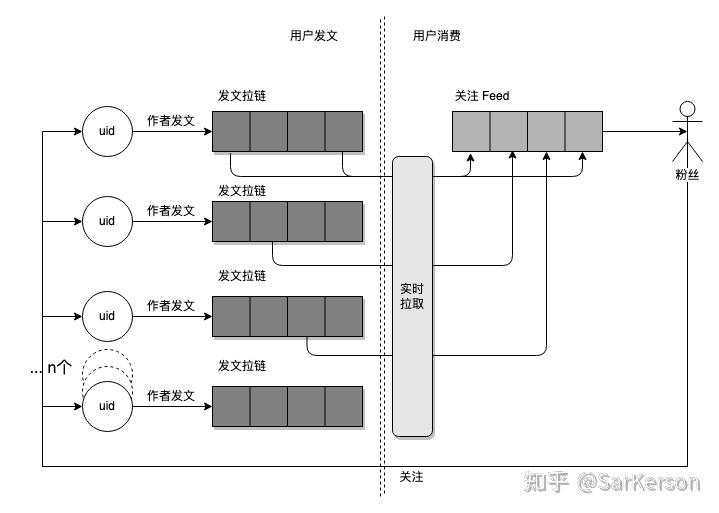
pull mode 即实时召回,每个用户不会维护一个拉链进行存储,而是实时拉取「关注用户」的动态,进行实时排序。
用户发文时,写入自己的「发文拉链」中;
用户消费信息流时,遍历关注的所有作者,从作者发文拉链中实时拉取数据,进行合并、排序;
好处: 节约存储,避免写扩散;发帖简单;
坏处: 读帖复杂;关注人多时存在性能问题;
适用场景: 用户不活跃,很少读帖;有大 v 场景,粉丝量很多;关注的人少;
pull & push 混合
| 优点 | 缺点 | 适用场景 | |
|---|---|---|---|
| Pull mode | 节约存储,避免写扩散发帖简单 | 读帖复杂关注人多时存在性能问题 | 用户不活跃,很少读帖有大 v 场景,粉丝量很多关注的人少 |
| Push mode | 读帖简单 | 发帖复杂,存在写扩散问题大 v 粉丝量多时存在性能 | 用户活跃,经常刷帖无大 v,用户粉丝量少 |
针对上述,对用户群体进行划分,混合使用 pull & push,具体操作如下:
- 将用户群体分为活跃 G1、不活跃 G2 两个组;
- 当大明星 X1 发帖时,将帖子写入 X 的发件箱的同时,顺便写入其粉丝中属于 G1 那部分的收件箱;
- 当路人甲 X2 发帖时,采用 push mode,遍历他的所有粉丝并将帖子写入粉丝收件箱;
现在考虑消费场景:
- G1 用户登录刷Feed流时:直接从自己的收件箱读取帖子即可,保证了活跃用户的体验。
- G2 用户突然登录刷Feed流时:
- 读他的收件箱;
- 遍历他所关注的大 V 用户的发件箱提取帖子;
- merge 上述结果;
注:因为有 pull mode 的场景存在,因此即使是混合模式,每个阅读者所能关注的人数也要设置上限。
关注流的方案
根据量级测算,笔者所在业务关注流使用了 pull-mode,存储选型使用了内部的 IndexService。这是一个基于 LMDB 的纯内存数据库,并且会建立基于 score 的索引,由于每条发文拉链不会很长,扇出百级别、近千级别仍然可以有不错的性能。
| 特性 / 存储选型 | IndexService | ByteGraph | Redis |
|---|---|---|---|
| 存储模型 | key:value|score|extra(可以基于 extra 进行业务过滤) | Vertex –Edge–> Vertex | key:value|score |
| 性能 | 批量取倒排延时 IndexService < redis < Rocksdb | 底层依赖 Rocksdb,latency 比 IndexService 高 | 性能优于 abase,因为 abase 基于 rocksdb |
| 召回 | 支持多种 merge支持排序 | 业务自己 merge单条召回支持排序,多路召回需要业务自己排序 | 业务自己 merge单条召回支持排序,多路召回需要业务自己排序 |
| 读取 | 支持 impression_container 消重对于多路召回,不需要业务维护游标,使用内存现算 | 业务自己消重业务需要维护多路游标,否则可能导致漏数据 | 业务自己消重业务需要维护多路游标,否则可能导致漏数据 |
| 拓展性 | 拓展好,extra_info 可以携带拓展信息 | 拓展好,edge 可以携带拓展信息 | 拓展差,需要额外维护 meta 信息 |
注意,即使后续切换到 pull & push 混合模式,仍然可以使用该技术栈来解决,并且这时候,召回的扇出会变得非常小(用户收件箱+关注的几个大V的发件箱)。虽然这时候用 ByteGraph 性能也不赖,但是业务方需要维护多个游标(每路召回对应一个),实现起来仍然比较复杂。
不可重复读、幻读
上述关注流场景是基于时间线排序,时间线的一个特点就是,数据写了,score 就不会改变(score 就是发文的 timestamp)。
但是某些业务场景可能不是按照严格时间线,而是按照点赞数等互动行为的热度来排序,这时候 score 会经常变动。基于时间线通常使用 (start_time, count) 来拉数据,而基于热度通常是使用 offset、count,即游标的起始值以及读取的数量。
那么对于此场景,使用上述任何一种方案,都可能导致缺数据、或者多数据的问题。
本质上,这个问题类似数据库的不可重复读、幻读。下面进行简单分析:
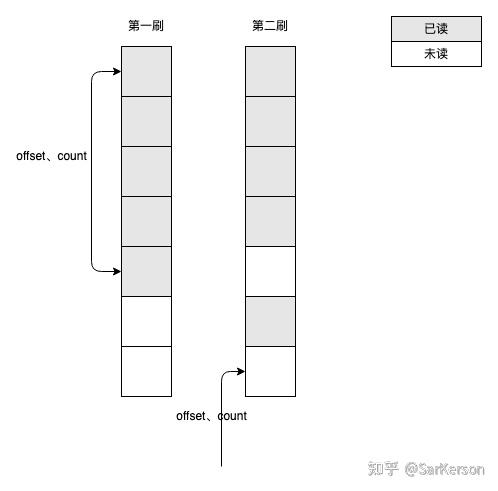
如下图所示,第一刷返回 5 条之后,考虑以下几种情况:
- 如果下面有其他 item 有 score 的变更,导致插在前 5 条之中;(不可重复读)
- 如果恰好有新增的 item 插入到前 5 条之中;(幻读)
那么会导致第二刷返回的数据包含了第一刷的部分内容,并且漏掉了本该在第二刷返回的部分内容。
这大概是数据库领域的经典问题了。
数据库(这里指 InnoDB)是使用 MVCC 机制来解决上述问题的,即维护一个基于事务版本实现的视图,在可重复读隔离级别下,整个事务执行过程中看到的都是事务开始时的快照。
而对于 ES 而言,也有类似问题。给定一个分页查询(ES 里称为 from、size,跟上述提到的 offset、count 一样一样的),ES 通常需要在每个分片中搜索得到 [0, size+from) 区间内的所有数据,然后在 coordinator 进行 merge 计算得到结果并返回。在进行分页查询期间,数据有任何变动的话,则可能会影响数据的完整性,出现上述提到的信息流一摸一样的问题。
ES 的解决方案与 InnoDB 的思想类似,分页起始时,返回一个快照,由于 ES 没有事务的概念,因此该快照存在一个过期时间,由客户端来指定。这里将分页开始到快照结束称为一个会话,ES 保证在该会话期间,分页查询访问的是同一个快照。详细可以阅读 ES earch-after。
解决方案
本文提供两个解决方案供参考。
方案一
预请求+一致性哈希+会话缓存
- 每次会话开始时,服务端生成一个 token,并预请求 X 条数据进行本地缓存。缓存 key 是 token,值是 X 条数据 ID;
- 接下来该用户的所有的 load more 行为,经过网关一致性哈希路由到同一台后端实例,读取内存中的缓存,进行分页操作;
这样的话,至少可以保证前 X 条数据从会话开始之后是稳定的。
当然,也可以使用分布式缓存来替换上述的一致性哈希+单机缓存方案,可以根据性能需求灵活选择。
局限性: 集群实例数变化时路由会失效;首刷需要获取 X 条数据,X 过大时会影响首刷性能;当用户量很大时,会占用很大内存(或其他存储),影响性能;
另外,通常来说,数据重复不可接受,而数据不完整用户很难感知。X 条数据之后,有可能会有重复问题,所以一般会走客户端消重来配合食用,数据不完整则无解。
方案二
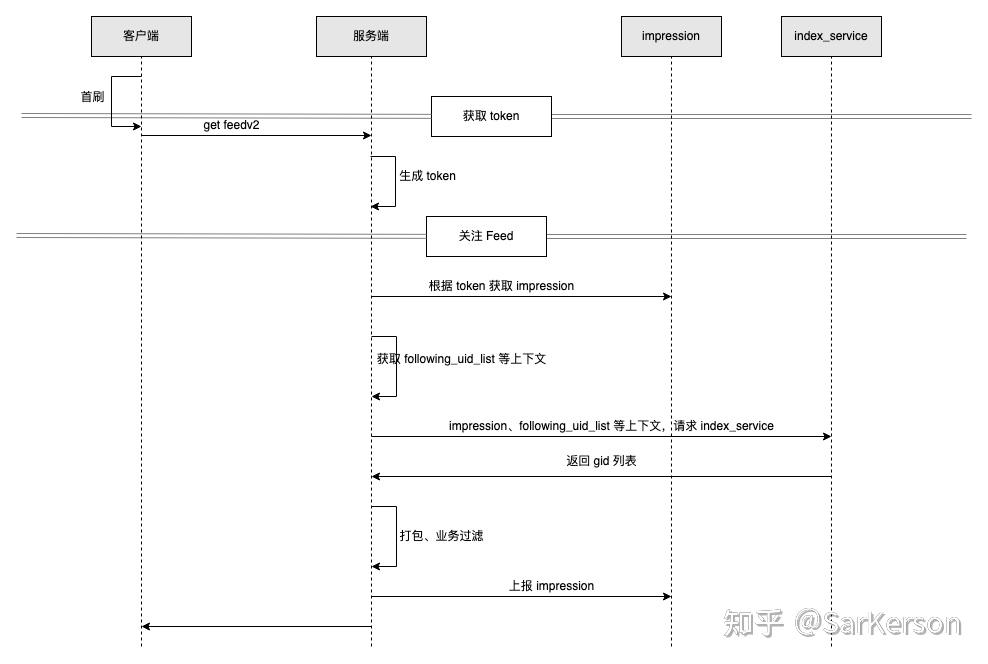
从头拉数据+消重;参考选型 index_service+impression
- 每次会话开始时,服务端生成一个 token,token=会话起始时间戳;
- 没有 offset 的概念,服务端底层会从头拉取 index_service 的数据,只是携带 impression 上下文进行消重;
- 每一刷服务端返回 count 个数据,并上报 impression 消重;
index_service 底层依赖 LMDB,可以应对大规模的数据集,因此对于拉取用户所需的那么几刷数据没有性能问题(因为大部分场景下所需召回倒排不会很多,例如文章评论,就只需要一个倒排)。
当然,消重也可以走其他方案,比如客户端透传、服务端自己记录来实现。
业界方案
朋友圈
https://cloud.tencent.com/developer/article/1168946
注:猜测使用混合模式,并且注意每个用户能看到的朋友圈,其实是有数量上限的,因此收件箱必然是有截断的,而发件箱则是全量;
https://blog.mi.hdm-stuttgart.de/index.php/2021/03/10/how-to-scale-real-time-tweet-delivery-architecture-at-twitter/
小结
本文以关注流为例子,介绍了几种信息流的实现方案,并对比其优缺点,介绍了各自适合的应用场景。并归纳了信息流领域常见的幻读、不可重复读问题,参考数据库隔离级别实现的思路,提出对应的两个解决方案。