TL;DR; 本文介绍常见时序数据库的基本架构,并以 InfluxDB 为例子介绍其存储模型及存储引擎的原理。最后介绍公司的 metrics 常见写入及读取操作。通过本文,你可以对时序数据库的原理有个初步了解,并可以对查询操作得心应手。
简介
基本概念
时序数据库是处理时序数据最优的数据库类型,而时序数据是随时间变化而被监控,跟踪,降采样,聚合的指标数据和事件。
为什么需要时序数据库?
特性
时序数据,区别于其他数据,拥有以下特征:
- 数据随着时间增长,根据维度取值,而数据维度几乎不变。
- 持续高写入吞吐量,设备越多,写入数量越大,而且由于定期采样,写入量平稳。
- 持续高读取吞吐量。
- 几乎不会有更新操作(一个设备在某个时间点产生的数据不会变动)以及单独数据点的删除(通常只会删除过期时间范围内所有的数据)
- 查询一般都是查最近产生的数据,很少会去查询过期的数据。
- 设备之间的数据关联性小,同种类设备A和设备B产生的数据互相并不依赖,你并不需要join。
面临的挑战
- 时序数据的写入:如何支持每秒钟上千万上亿数据点的写入。
- 时序数据的读取:如何支持在秒级对上亿数据的分组聚合运算。
- 成本敏感:由海量数据存储带来的是成本问题。如何更低成本的存储这些数据,将成为时序数据库需要解决的重中之重。
应用场景
Metrics不仅仅可以用于软件开发中的监控指标大盘,还有以下应用场景:
- 监控软件系统: 虚拟机、容器、服务、应用
- 监控物理系统: 设备、机器、接入的设备、环境、我们的房屋、我们的身体
- 资产跟踪应用: 汽车、卡车、物理容器、运货托盘(Pallets)
- 金融交易系统: 传统证券、新兴的加密数字货币
- 事件应用程序: 跟踪用户、客户的交互数据
- 商业智能工具: 跟踪关键指标和业务的总体健康情况
解决方案
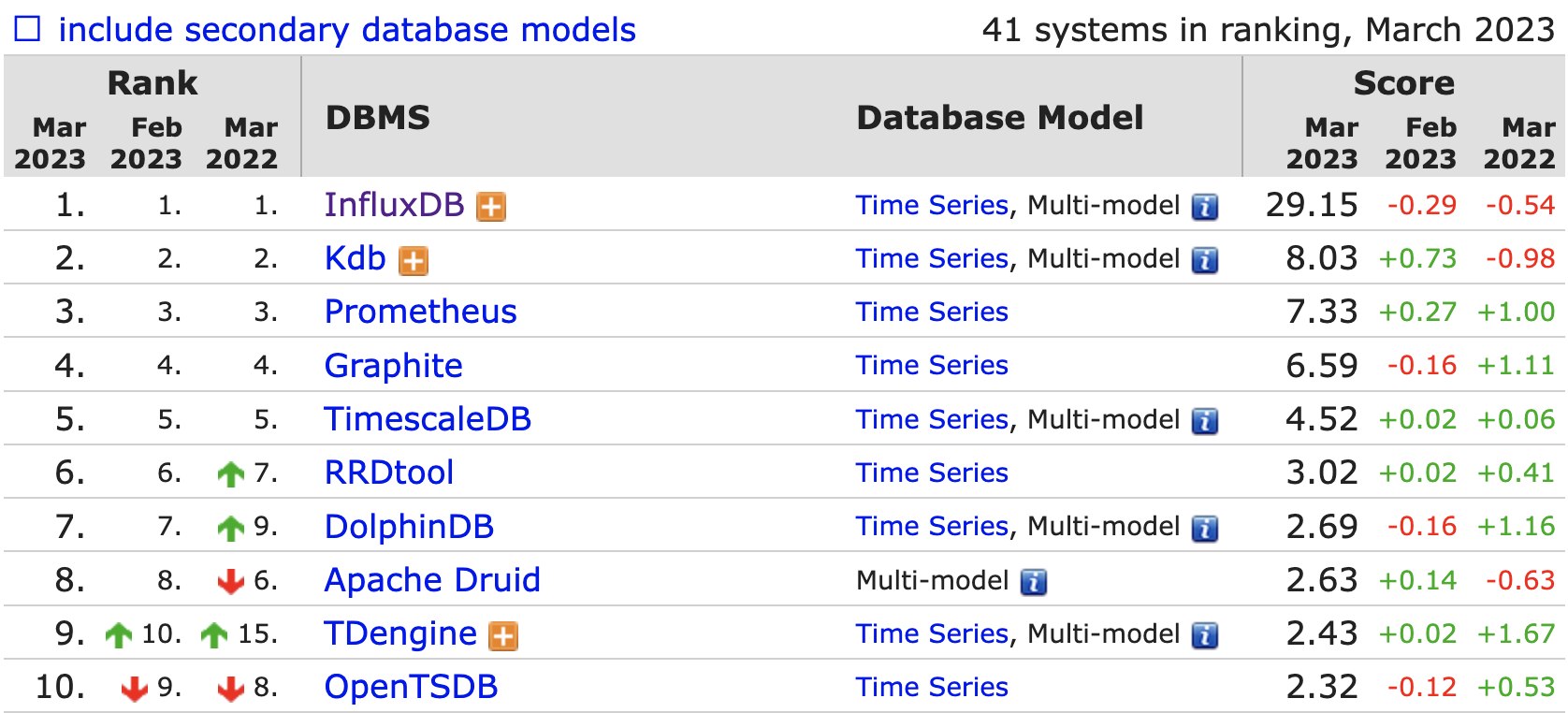
https://db-engines.com/en/ranking/time+series+dbms
组件概览
采集器
采集器是用于采集时序数据的组件。它们通常是通过一些特定的协议或API获取数据,并将其发送到时序数据库中。
通常会在服务器端部署 agent 来进行数据采集,然后传送给时序库。这里常见有推拉两种模式。推模式下,采集器会周期性地向时序数据库发送数据,实时性更高,且适合短作业,但是对写吞吐有较高要求;拉模式下,时序数据库会定期向采集器发起请求获取最新的数据,稳定性更高,但有延迟,通常只用于长作业。
时序库
监控系统的架构中,最核心的就是时序库。与传统的关系型数据库不同,时序数据库通常采用分布式架构和列式存储以支持高吞吐量和低延迟的数据写入和查询。常见的时序数据库包括InfluxDB、OpenTSDB、Prometheus等。它们通常提供了一些特殊的查询语言和API以便进行时序数据的查询和操作。
告警引擎
告警引擎的核心职责就是处理告警规则,生成告警事件。通常来讲,用户会配置数百甚至数千条告警规则,一些超大型的公司可能要配置数万条告警规则。每个规则里含有数据过滤条件、阈值、执行频率等,有一些配置丰富的监控系统,还支持配置规则生效时段、持续时长、留观时长等。
当然,随着时代的发展,也有系统支持统计算法和机器学习的方式做告警预判。AiOps 概念中最容易落地,或者说落地之后最容易有效果的,就是告警引擎。
告警引擎通常有两种架构,一种是数据触发式,一种是周期轮询式。
- 数据触发式,是指服务端接收到监控数据之后,除了存储到时序库,还会转发一份数据给告警引擎,告警引擎每收到一条监控数据,就要判断是否关联了告警规则,做告警判断。因为监控数据量比较大,告警规则的量也可能比较大,所以告警引擎是会做分片部署的,即部署多个实例。这样的架构,即时性很好,但是想要做指标关联计算就很麻烦,因为不同的指标哈希后可能会落到不同的告警引擎实例。
- 周期轮询式,架构简单,通常是一个规则一个协程,按照用户配置的执行频率,周期性查询判断即可,因为是主动查询的,做指标关联计算就会很容易。像 Prometheus、Nightingale、Grafana 等,都是这样的架构。
数据展示
监控数据的可视化也是一个非常通用且重要的需求,业界做得最成功的当数 Grafana。Grafana 采用插件式架构,可以支持不同类型的数据源,图表非常丰富,基本可以看做是开源领域的事实标准。很多公司的商业化产品中,甚至直接内嵌了 Grafana。当然,Grafana 新版本已经修改了开源协议,使用 AGPLv3,这就意味着如果某公司的产品基于 Grafana 做了二次开发,就必须公开代码。
业界方案
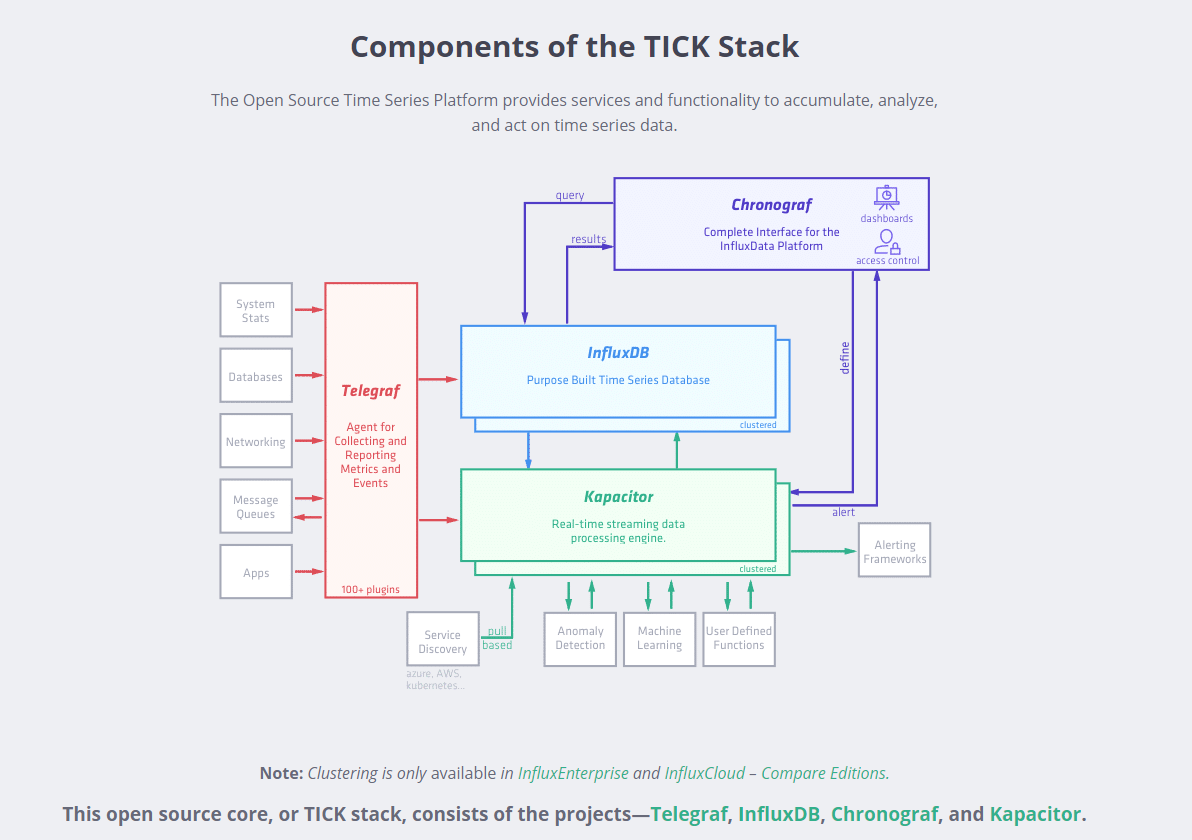
InfluxData TICK Stack
https://zhoujinl.github.io/2018/02/27/tick/
TICK 是由 InfluxData 开发的一套运维工具栈,由 Telegraf, InfluxDB, Chronograf, Kapacitor 四个工具的首字母组成。这一套组件将收集数据和入库、数据库存储、展示、告警四者囊括。
- Telegraf: 用Golang开发的代理程序,可用于收集和提交metric。Telegraf工作原理大概是这样:定时去执行输入插件收集数据,数据经过处理插件和聚合插件,通过输出插件输出到数据存储。
- InfluxDB:一款专门处理高写入和查询负载的时序数据库。
- Chronograf: Chronograf 是InfluxData的开源可视化引擎,可让通过数据的实时可视化快速构建仪表板,并支持与 Kapacitor 联动。
- Kapacitor: 指标和事件处理和告警引擎。使用它将时间序列数据处理成可操作的告警,并将这些告警发送到许多流行的产品,如 PagerDuty,Slack 等。
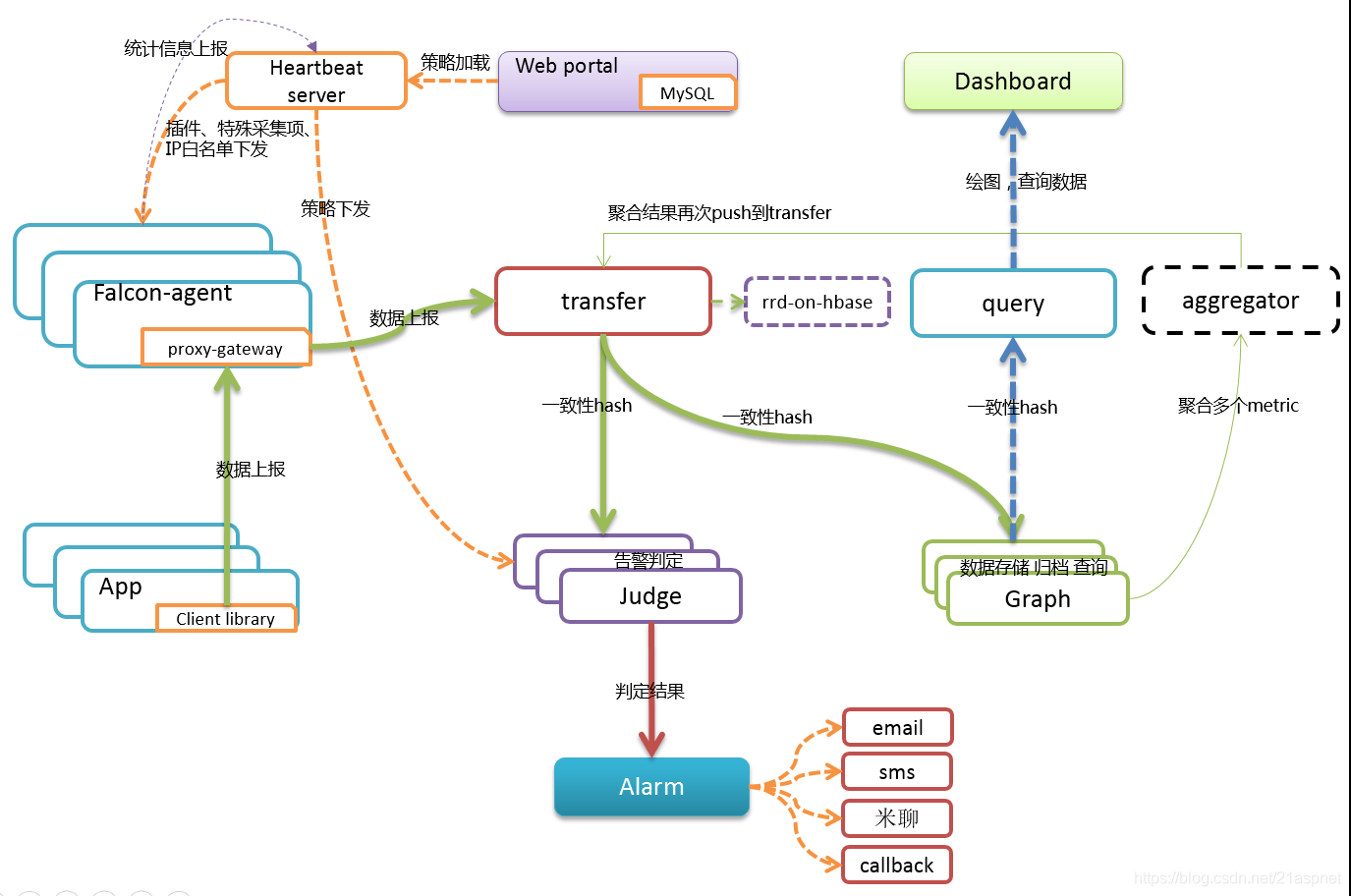
Open-Falcon
https://cloud.tencent.com/developer/article/1845407
小米开源的云监控系统,提供了采集、存储、查询、告警、展示等一整套解决方案,支持主机、应用、网络等多种监控数据类型。
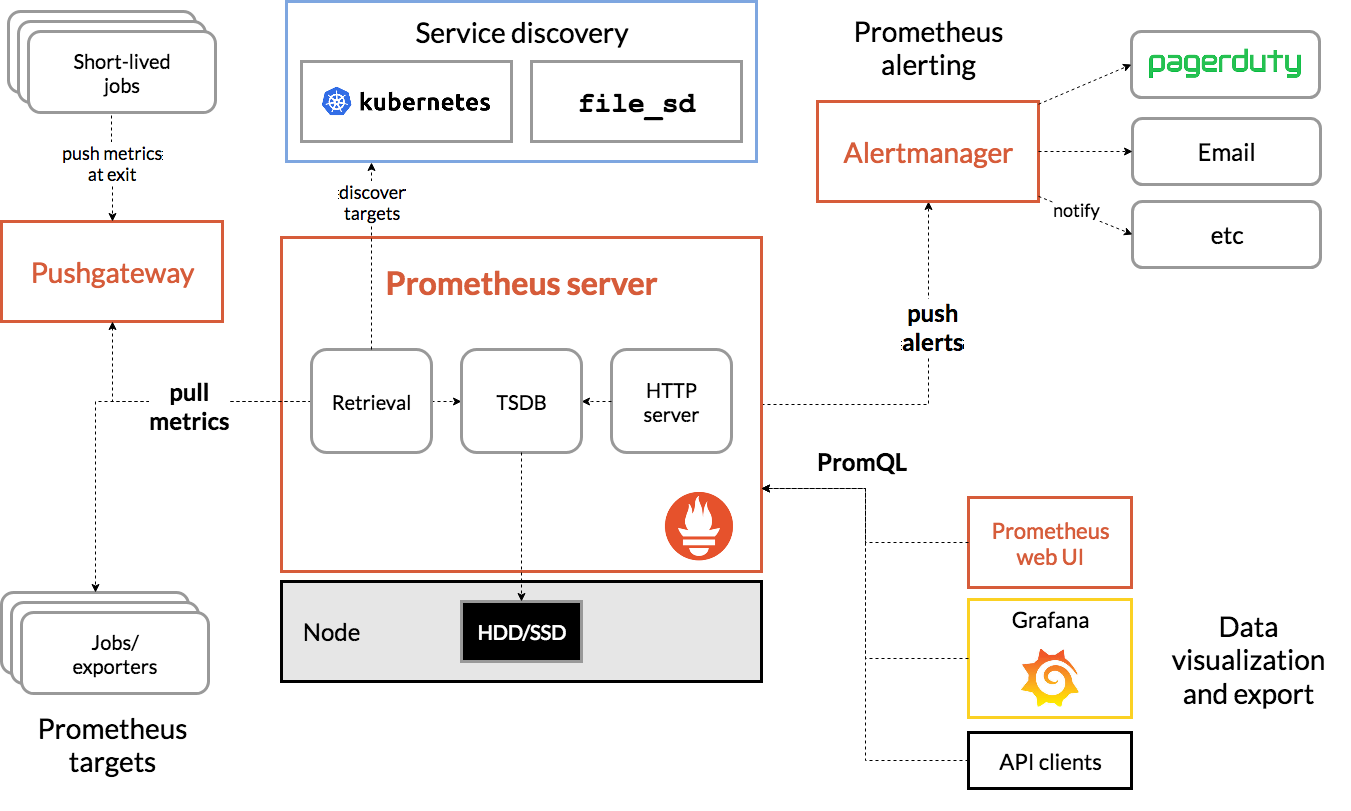
Prometheus Stack
https://prometheus.kpingfan.com/01-introduction/01.prometheus%E6%9E%B6%E6%9E%84/
由 Prometheus、Alertmanager 和 Grafana 组成的一整套解决方案,用于采集、存储、查询和可视化时序数据,并提供了告警和自动化操作的功能。
- Prometheus Server:Prometheus组件中的核心部分,负责对监控数据的获取,存储及查询。
- Exporter:负责将监控数据通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
- PushGateway:通过PushGateway将监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。解决短作业无法提供通信服务的问题。
- AlertManager:在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。AlertManager集成了邮件,Slack等通知方式,也提供Webhook自定义告警处理。
1.3.2.4. Metrics
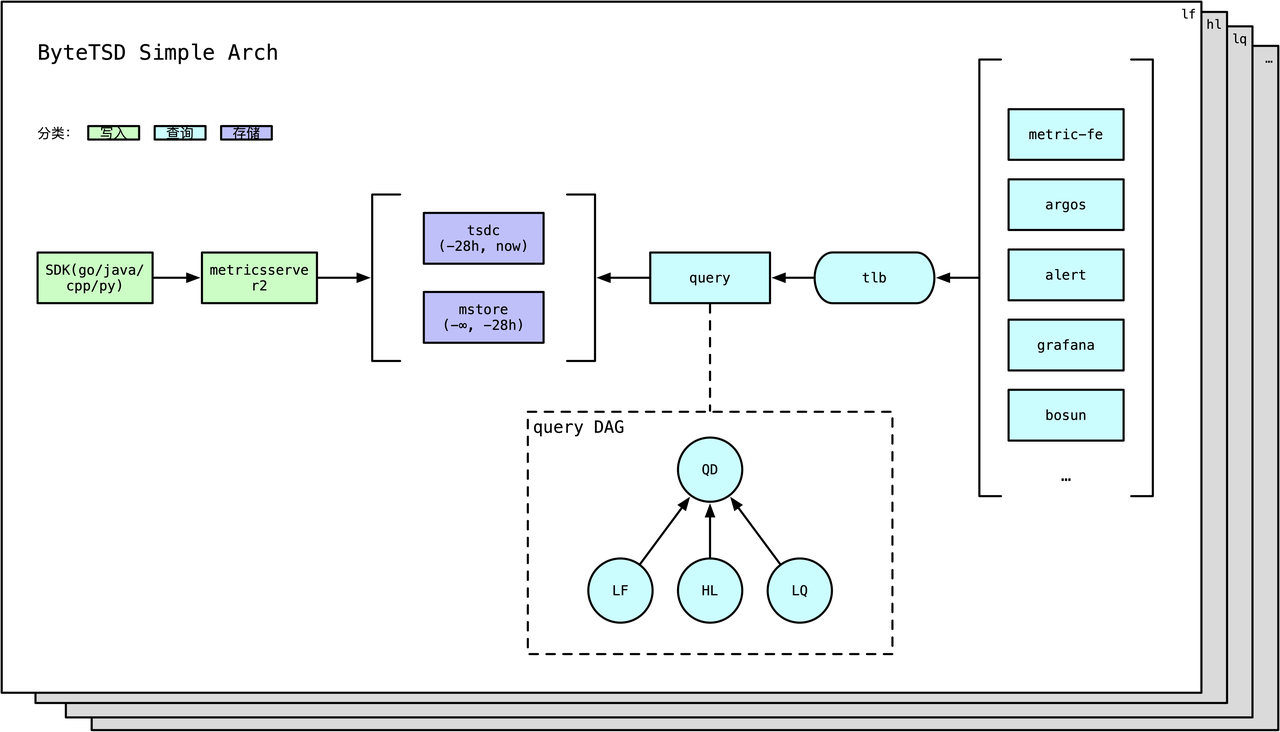
写入
写入侧组件是用户需要感知的,由如下2类:
- SDK: Metrics提供了多种开发语言的SDK
- agent: Metrics在每台物理机/云主机都有部署名为
metricserver2的agent,该agent负责收集SDK打过来的指标,并且每30s进行一次序列内、时间纬度上的聚合,然后发送给Metrics后端。
存储
按照时序数据的冷热特点,Metrics将数据按照时间纬度,存放在不同的存储系统:
- 近28小时数据:存放在热存
tsdc - 28小时以外数据:存放在冷存
mstore(on HDFS)
此外,mstore会archive历史数据,具体规则:
- 近30天内:不archive
- 近60天~近30天:按照5分钟一个点archive
- 60天以以外:按照1h一个点archive
存储模型及存储引擎
这里以 influxdb 为例子,介绍其存储模型及存储引擎,其他时序数据库思路类似
存储模型
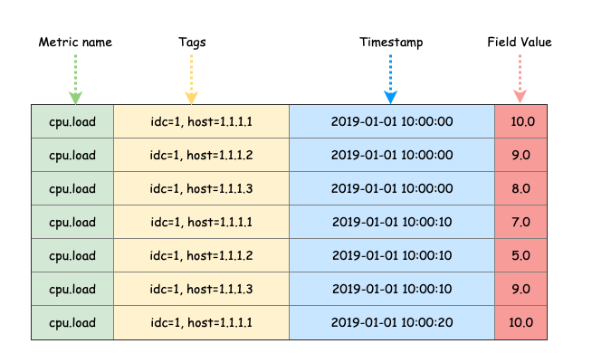
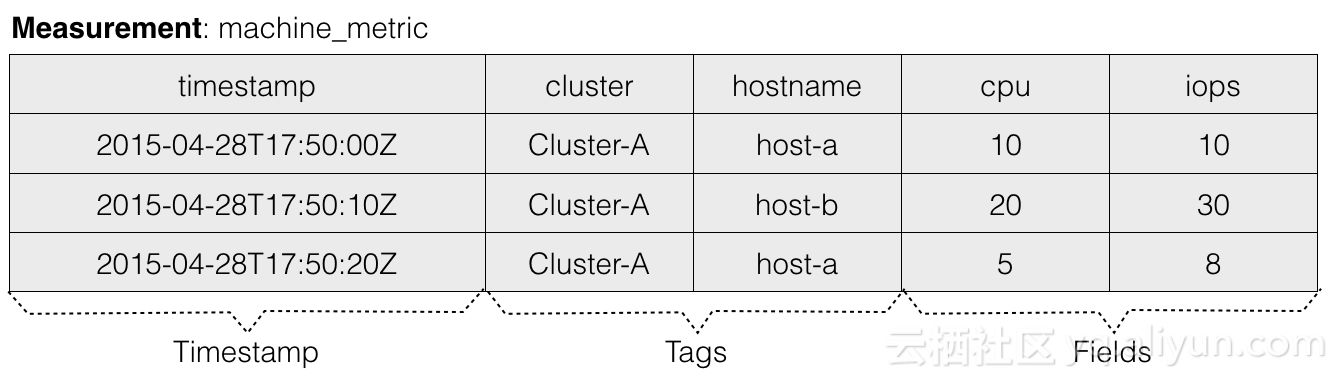
InfluxDB 使用的是典型的 KV 存储模型。Measurement+Tags 确定一个 timeseries。
下面是一条向InfluxDB中写入一条数据的命令行,来看下这条数据由哪几个部分组成:
INSERT machine_metric,cluster=Cluster-A,hostname=host-a cpu=10 1501554197019201823
上面是一条向InfluxDB中写入一条数据的命令行,来看下这条数据由哪几个部分组成:
- Measurement:Measurement代表数据所属监控指标的名称。例如上述例子是对机器指标的监控,所以其measurement命名为machine_metric。
- Tags:用于描述measurement的不同的维度,允许存在一个或多个Tag,每个Tag也是由TagKey和TagValue构成。
- Field:一行measurement数据可以对应多个value,每个value根据Field来区分。
- Timestamp: 时序数据的必备属性,代表该条数据所属的时间点,可以看到InfluxDB的时间精度能够精确到纳秒。
- TimeSeries:Measurement+Tags的组合,在InfluxDB中被称为TimeSeries。TimeSeries就是时间线,根据时间能够定位到某个时间点,所以TimeSeries+Field+Timestamp能够定位到某个Value。这个概念比较重要,在后续的章节中都会提到。
最终在逻辑上每个Measurement内的数据会组织成一张大的数据表,如下图所示:

在查询时,InfluxDB支持在Measurement内任意维度的条件查询,你可以指定任意某个Tag或者Filed的条件做查询。接着上面的数据案例,你可以构造以下查询条件:
SELECT * FROM "machine_metric" WHERE time > now() - 1h;
SELECT * FROM "machine_metric" WHERE "cluster" = "Cluster-A" AND time > now() - 1h;
SELECT * FROM "machine_metric" WHERE "cluster" = "Cluster-A" AND cpu > 5 AND time > now() - 1h;
从数据模型以及查询的条件上看,Tag和Field没有任何区别。从语义上来看,Tag用于描述Measurement,而Field用于描述Value。从内部实现来上看,Tag会被全索引,而Filed不会,所以根据Tag来进行条件查询会比根据Filed来查询效率高很多。
存储引擎
https://docs.influxdata.com/influxdb/v1.8/concepts/storage_engine
https://zhuanlan.zhihu.com/p/32710333
概念
InfluxDB在经历了几个小版本的BoltDB后,最终决定自研TSM,TSM的设计目标一是解决LevelDB的文件句柄过多问题,二是解决BoltDB的写入性能问题。TSM全称是Time-Structured Merge Tree,思想类似LSM,不过是基于时序数据的特性做了一些特殊的优化。来看下TSM的一些重要组件:
- In-Memory Index - The in-memory index is a shared index across shards that provides the quick access to measurements, tags, and series. The index is used by the engine, but is not specific to the storage engine itself.
- Write Ahead Log(WAL) : 数据会先写入WAL持久化,后进入memory-index和cache。Cache内数据会异步刷入TSM File,在Cache内数据未持久化到TSM File之前若遇到进程crash,则会通过WAL内的数据来恢复cache内的数据,这个行为与LSM是完全类似的。
- Cache: TSM的Cache与LSM的MemoryTable类似,其内部的数据为WAL中未持久化到TSM File的数据。若进程发生failover,则cache中的数据会根据WAL中的数据进行重建。
- TSM Files: TSM File与LSM的SSTable类似,TSM File由四个部分组成,分别为:header, blocks, index和footer。后文会详细介绍。
- Compaction: compaction是一个将write-optimized的数据存储格式优化为read-optimized的数据存储格式的一个过程
TSM 文件
TSM文件最核心的由Series Data Section以及Series Index Section两个部分组成,其中前者表示存储时序数据,而后者存储文件级别B+树索引,用于在文件中快速查询时间序列数据块。
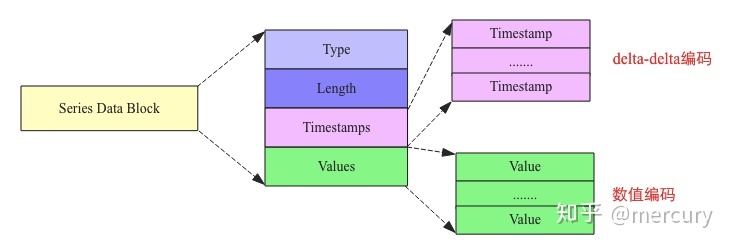
Series Data Block
Map中一个Key对应一系列时序数据,因此能想到的最简单的flush策略是将这一系列时序数据在内存中构建成一个Block并持久化到文件。然而,有可能一个Key对应的时序数据非常之多,导致一个Block非常之大,超过Block大小阈值,因此在实际实现中有可能会将同一个Key对应的时序数据构建成多个连续的Block。但是,在任何时候,同一个Block中只会存储同一种Key的数据。
另一个需要关注的点在于,Map会按照Key顺序排列并执行flush,这是构建索引的需求。Series Data Block文件结构如下图所示:
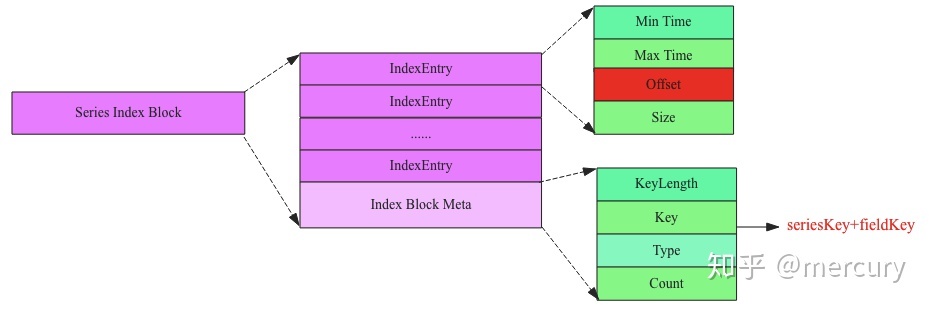
Series Index Block
每个key 对应一个Index Block。
很多时候用户需要根据Key查询某段时间(比如最近一小时)的时序数据,如果没有索引,就会需要将整个TSM文件加载到内存中才能一个Data Block一个Data Block查找,这样一方面非常占用内存,另一方面查询效率非常之低。为了在不占用太多内存的前提下提高查询效率,TSM文件引入了索引。TSM文件索引数据由一系列索引Block组成,每个索引Block的结构如下图所示:
Series Index Block由Index Block Meta以及一系列Index Entry构成:
- Index Block Meta最核心的字段是Key,表示这个索引Block内所有IndexEntry所索引的时序数据块都是该Key对应的时序数据。
- Index Entry表示一个索引字段,指向对应的Series Data Block。指向的Data Block由Offset唯一确定,Offset表示该Data Block在文件中的偏移量,Size表示指向的Data Block大小。Min Time和Max Time表示指向的Data Block中时序数据集合的最小时间以及最大时间,用户在根据时间范围查找时可以根据这两个字段进行过滤。
读写
https://zhuanlan.zhihu.com/p/97247465
写入
Writes are appended to the current WAL segment and are also added to the Cache. Each WAL segment has a maximum size. Writes roll over to a new file once the current file fills up. The cache is also size bounded; snapshots are taken and WAL compactions are initiated when the cache becomes too full. If the inbound write rate exceeds the WAL compaction rate for a sustained period, the cache may become too full, in which case new writes will fail until the snapshot process catches up.
When WAL segments fill up and are closed, the Compactor snapshots the Cache and writes the data to a new TSM file. When the TSM file is successfully written and fsync’d, it is loaded and referenced by the FileStore.
Updates (writing a newer value for a point that already exists) occur as normal writes. Since cached values overwrite existing values, newer writes take precedence. If a write would overwrite a point in a prior TSM file, the points are merged at query runtime and the newer write takes precedence.
Deletes occur by writing a delete entry to the WAL for the measurement or series and then updating the Cache and FileStore. The Cache evicts all relevant entries. The FileStore writes a tombstone file for each TSM file that contains relevant data. These tombstone files are used at startup time to ignore blocks as well as during compactions to remove deleted entries.
Queries against partially deleted series are handled at query time until a compaction removes the data fully from the TSM files.
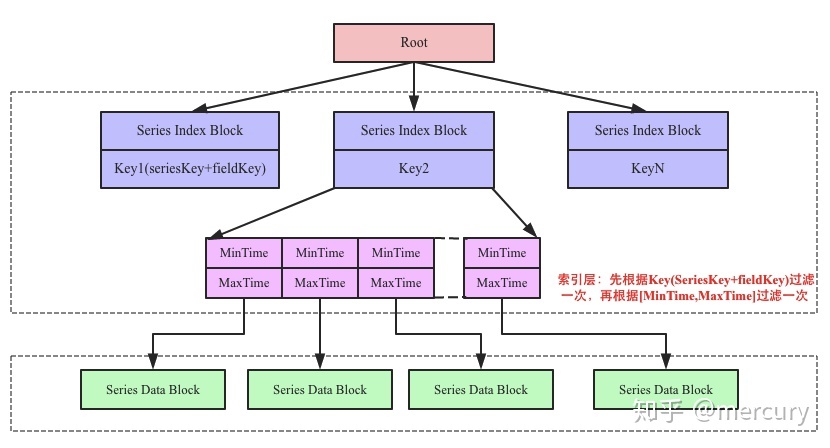
读取
上图中中间部分为索引层,TSM在启动之后就会将TSM文件的索引部分加载到内存,数据部分因为太大并不会直接加载到内存。用户查询可以分为三步:
- 首先根据Key找到对应的SeriesIndex Block,因为Key是有序的,所以可以使用二分查找来具体实现。
- 找到SeriesIndex Block之后再根据查找的时间范围,使用[MinTime, MaxTime]索引定位到可能的Series Data Block列表。
- 将满足条件的Series Data Block加载到内存中解压进一步使用二分查找算法根据timestamp查找即可找到。
压缩
Level Compaction
InfluxDB将TSM文件分为4个层级(Level 1-4),compaction只会发生在同层级文件内,同层级的文件compaction后会晋升到下一层级。从这个规则看,根据时序数据的产生特性,level越高数据生成时间越久,访问热度越低。由Cache数据初次生成的TSM文件称为Snapshot,多个Snapshot文件compaction后产生Level1的TSM文件,Level1的文件compaction后生成level2的文件,依次类推。
低Level和高Level的compaction会采用不同的算法,低level文件的compaction采用低CPU消耗的做法,例如不会做解压缩和block合并,而高level文件的compaction则会做block解压缩以及block合并,以进一步提高压缩率。
Index Optimization Compaction
当Level4的文件积攒到一定个数后,index会变得很大,查询效率会变的比较低。影响查询效率低的因素主要在于同一个TimeSeries数据会被多个TSM文件所包含,所以查询不可避免的需要跨多个文件进行数据整合。所以IndexOptimizationCompaction的主要作用就是将同一TimeSeries下的数据合并到同一个TSM文件中,尽量减少不同TSM文件间的TimeSeries重合度。
Full Compaction
InfluxDB在判断某个Shard长时间内不会再有数据写入之后,会对数据做一次FullCompaction。FullCompaction是LevelCompaction和IndexOptimization的整合,在做完一次FullCompaction之后,这个Shard不会再做任何的compaction,除非有新的数据写入或者删除发生。这个策略是对冷数据的一个规整,主要目的在于提高压缩率。
查询优化
演变历程
InfluxDB 的存储引擎经历了从 LSM Tree => B+Tree => TSM Tree 的过程。
https://docs.influxdata.com/influxdb/v1.8/concepts/storage_engine/
Metrics
写入
metrics_agent 每30s进行一次序列内、时间纬度上的聚合,然后发送给Metrics后端。
counter
- 会将在指定tagkv集合积攒的值与打上来的值相加作为新值, 关注的是变化量和变化速率
- 会一直累加直到达到 double 类型的最大值,即2^1024,也就是1.79E+308
- 适用于求rate{counter}(rate表示求导,counter表示去掉导数的负值)之后计算任意操作的速率(qps/tps/ops) 使用。
- 举个例子,每分钟新增打点 30 个,rate{counter}对 60 秒求导,30/60 = 0.5,查询时勾上 rate,counter 的情况下的值就是 0.5
Store
- 打上来什么值就是什么值,实际显示的值是30秒的采样周期中最后打上来的值。
- 会按照 tag 分组后统计(tag 相同的 30 秒内取最后一次的值,tag 不同的两个都上传)
适用于只关注每个周期最新状态的监控采集,如 CPU/内存使用率,线程数,连接数,消费积压量
Timer
- 将30秒的采样周期内(同一个ms2/宿主机)打上来的值缓存起来,然后在采样周期结束时统计本采样周期内打上来的值。
个人理解,timer 本质上与 counter/store 类似,只不过顺便提供了窗口计算功能。猜测 metrics 在 agent 端对 timer 数据做了预处理,预计算了 metrics 在窗口内的统计数据。例如:counter(30秒打了有多少个值,大致为__qps__*30)、avg、pctx 等。
| t0 | t0+10s | t0+20s | t0+30s | t0+40s | t0+50s | … | t0+ns | |
|---|---|---|---|---|---|---|---|---|
| Raw data | 27 | 28 | 29 | 32 | 31 | 30 | 27.3 | |
| .min | 27 | 30 | - | |||||
| .max | 29 | 32 | - | |||||
| .avg | 28 | 31 | - | |||||
| .counter | 3 | 3 | - |
rate_counter
类似打点类型-counter,但是是将30秒的采样周期内打上来的值累加/30秒,算出变化率,比如QPS。最终将这个变化率emit出去。查询时如果再次求rate,就是变化率的变化率,比如QPS的变化率。不关注增量,只关注变化率的可以使用这个打点,相对于 counter 查询时无需做 rate计算,开销较低,支持流式聚合,支持预聚合等优化
meter
为Counter和Rate_Counter的结合,一次meter类型的打点可以生成两种类型打点。
查询
https://tech.bytedance.net/articles/6867450721697185799
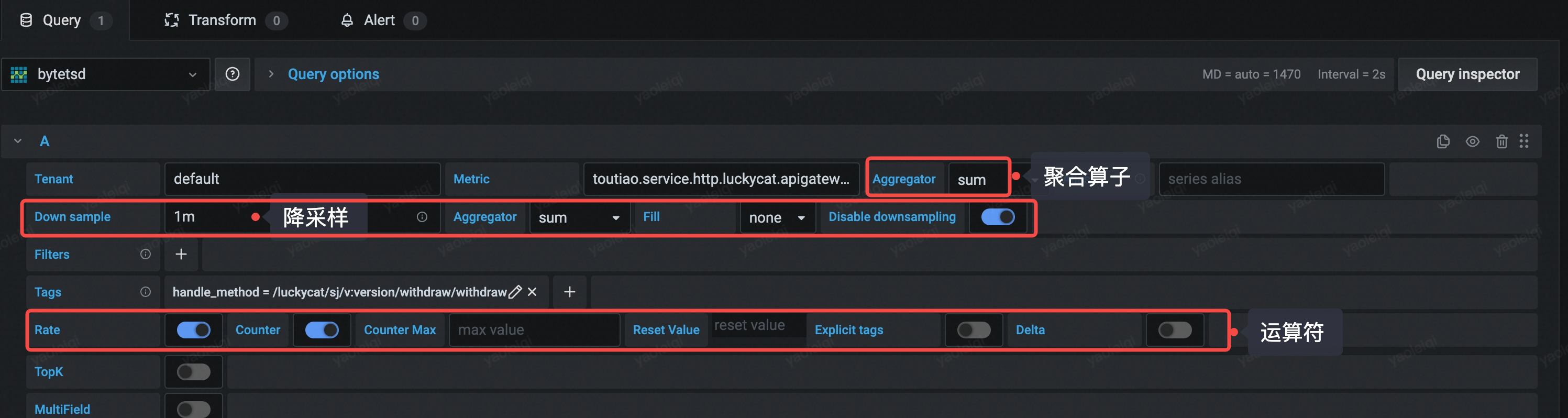
了解基本原理之后,查询逻辑基本可以通吃
- 聚合算子:对指定 tag 的 timeseries 进行 groupby
- 降采样:在执行聚合算子之后,对新数据进行执行降采样操作
- 运算符:在上述两种 reduce 操作执行之后,执行运算符,得到结果列表
附录
引用
-
[In-memory indexing and the Time-Structured Merge Tree (TSM) InfluxDB OSS 1.8 Documentation](https://docs.influxdata.com/influxdb/v1.8/concepts/storage_engine/) - Metrics看这一篇就够了
-
[InfluxDB storage subsystem: the TSM files Just my thouhgts](https://migue.github.io/post/influx-storage-tsm-component/) -
[InfluxDB storage subsystem: an introduction Just my thouhgts](https://migue.github.io/post/quick-tour-influx-storage/)
拓展阅读
- https://tech.bytedance.net/articles/6867450721697185799
- Log Structured Merge Trees
- LevelDB: a fast key-value storage