目标
文本偏战术设计,目标有以下两点:(对战略设计感兴趣的话,可以参考文末的拓展阅读)
- 了解 DDD:你可以了解 DDD 概念,并看懂大部分 DDD 的项目代码;
- 落地 DDD:你可以了解如何用 DDD 思想来建模、落地项目,并了解所需注意的事项与规范;
前言
Eric Evans 于 2003 年出版了《领域驱动设计:软件核心复杂性应对之道》,在书中他创造了领域驱动设计方法。是“领域驱动“领域的指明灯。
Vaughn Vernon 于 2014 年出版了《实现领域驱动设计》分别从战略和战术层面详尽地讨论了如何实现 DDD,其中包含了大量的最佳实践、设计准则和对一些问题的折中性讨论。
DDD 的作用域:DDD 可以是单服务内,也可以是多个服务组成(微服务化)的系统范围内。
微服务化不可回避两个问题:
- 如何划分服务?(识别界限上下文)
- 微服务内部如何组织子模块,如何高效应对业务发展?(以领域为核心的分层架构)
微服务与 DDD,在解决复杂业务问题时,采用了相同的指导思想,即分而治之。分治的手段有优雅也有不优雅,DDD 是一种分治的指导思想。
DDD 的目标
在做架构设计时,一个好的架构应该需要实现以下几个目标:
- 独立于框架:架构不应该依赖某个外部的库或框架,不应该被框架的结构所束缚(可以轻松从 kite 切换成 kitex)。
- 独立于UI:前台展示的样式可能会随时发生变化(今天可能是网页、明天可能变成 console、后天是独立 app),但是底层架构不应该随之而变化。
- 独立于底层数据源:无论今天你用 MySQL、Oracle 还是 MongoDB、TiDB,甚至使用文件系统,软件架构不应该因为不同的底层数据储存方式而产生巨大改变。
- 独立于外部依赖:无论外部依赖如何变更、升级,业务的核心逻辑不应该随之而大幅变化。
- 可测试:无论外部依赖了什么数据库、硬件、UI或者服务,业务的逻辑应该都能够快速被验证正确性。
DDD 正是服务于上述目标的一个方法论。
由于 DDD 不是一套框架,而是一种架构思想,所以在代码层面缺乏了足够的约束,导致 DDD 在实际应用中上手门槛很高,甚至可以说绝大部分人都对 DDD 的理解有所偏差。
我对 DDD 的理解也可能是有偏差的,但这个可能偏差的理解,带着我回答了文章开头提到的问题,所以这个有偏差的理解也值得你一起来探讨。下文总结自业界多种实践沉淀下来的方法论,让你对 DDD 的架构、各层级的职责及约束有个认知,降低 DDD 的实践门槛。期望通过下文描述,可以让你以 DDD 思想,参与 DDD 项目的具体开发中。
概念
案例
这里想通过一个案例,让你对 DDD 思想中涉及的概念有个宏观上的认知。
需求:
用户可以通过银行网页转账给另一个账号,支持跨币种转账。

我们可以看到,一段业务代码里经常包含了参数校验、数据读取存储、业务计算、调用外部服务等多种逻辑。在这个案例里虽然是写在了同一个方法里,在真实代码中经常会被拆分成多个子方法,但实际效果是一样的,而在我们日常的工作中,绝大部分代码都或多或少的接近于此类结构。在 Martin Fowler 的 P of EAA 书中,这种很常见的代码样式被叫做 Transaction Script(事务脚本)。虽然这种类似于脚本的写法在功能上没有什么问题,但是长久来看,他有以下几个很大的问题:可维护性差、可扩展性差、可测试性差。
考虑以下场景:
- 突然又来了一个同币种转账的需求,上述逻辑是不是又有复制一份?
- 又有另外一个场景,涉及到转账,上述逻辑又得复制一份?
- 有一天,转账逻辑变更了,例如需要做合规检测,每个场景是不是都要修改?
下面是经过 DDD 思想重构后的代码:
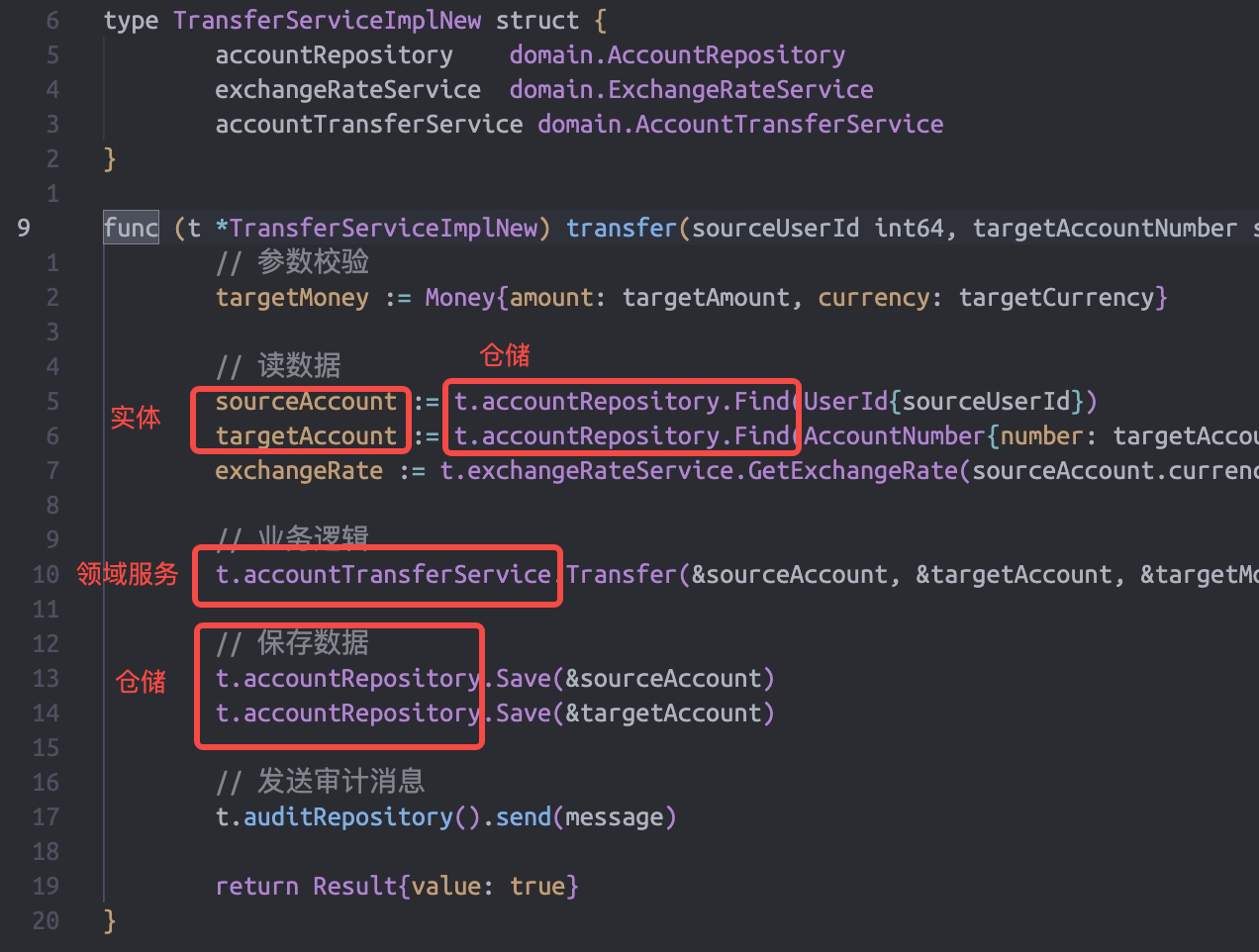
相比之下:
- 应用层主要做编排,并且大概率这个编排逻辑是很少变动的;
- 业务逻辑沉淀到了领域服务中,一处改动,多处收益;
- 每个模块都是可测试的;
实体(Entity)
- 定义:有唯一标识,能表示一个业务的生命周期的对象。
- 组成:实体由两部分组成:领域属性+领域能力
- 领域属性:对实体的描述,是实体的一部分。领域属性又可以分为,简单属性(string/int64等)和复杂属性(结构体,称为值对象)。
- 领域能力:实体自己的职责范围,能做什么,也可以叫作「实体行为」。
- 实体行为:实体行为又称为领域能力,就是当前的业务对象能干什么事情,落地到代码上,就是实体的public方法。一般调用者都是application层。
- 原则:实体能自己干的事情,尽量自己干,不要交给聚合或领域服务,这样每个领域对象各司其职,把自己的行为做完整。然后和其他领域对象之间的边界职责又很清楚,这样的严格的组织,能容易地帮助业务实现高内聚。区别于过程式编码,需要考虑的东西会多很多,但会对长期业务发展带来好处。
- 实体行为的粒度:实体行为的颗粒度,只有写代码的时候才会真正的思考。
- 颗粒度大小:原则上我们要求行为是颗粒度是最细的一件事情。提倡一个实体行为只干一件事情,这件事情的颗粒度最好是最细的。这样的好处就是为了方便复用。一般反对在一个实体的行为上去做一件以上事情,当你这么做的,你会发现非常难取名,你的方法上需要有两个动词,这时候,我们就要拆了。
- 当我们的颗粒度很细的时候,application 层需要做很多编排工作,这时候,你可以通过领域服务的方式进行封装。
- 颗粒度大小:原则上我们要求行为是颗粒度是最细的一件事情。提倡一个实体行为只干一件事情,这件事情的颗粒度最好是最细的。这样的好处就是为了方便复用。一般反对在一个实体的行为上去做一件以上事情,当你这么做的,你会发现非常难取名,你的方法上需要有两个动词,这时候,我们就要拆了。
- 实体和其他元素的关系

值对象(Value Object)
值对象通常作为实体的属性而存在,比如封面图、简介、标题、时间等。实体是客观存在的事物,值对象是为了描述事物,抽象出来的概念。是否拥有唯一身份标识,是实体与值对象的本质区别。
值对象也是可以有行为,可以进行沉淀。例如,图片,对应的主题色计算,是一种沉淀;电话号码,对应的有效性检测是一种沉淀;等等。
IDL 设计,尽量使用值对象建模思想,而不是分散的属性,难以管理、复用、沉淀
聚合(Aggregate)
领域模型内的实体和值对象好比个体,而能让实体和值对象协同工作的组织就是聚合,用来确保这些领域对象在实现共同的业务逻辑时,能保证数据的一致性。
场景:订单里面,包含商品、优惠券、邮费等属性,优惠券的存在,导致商品单价下降。当一个操作涉及多个实体操作时,并且存在一致性时,则需要把这些实体当作一个整体,这个整体叫做聚合。
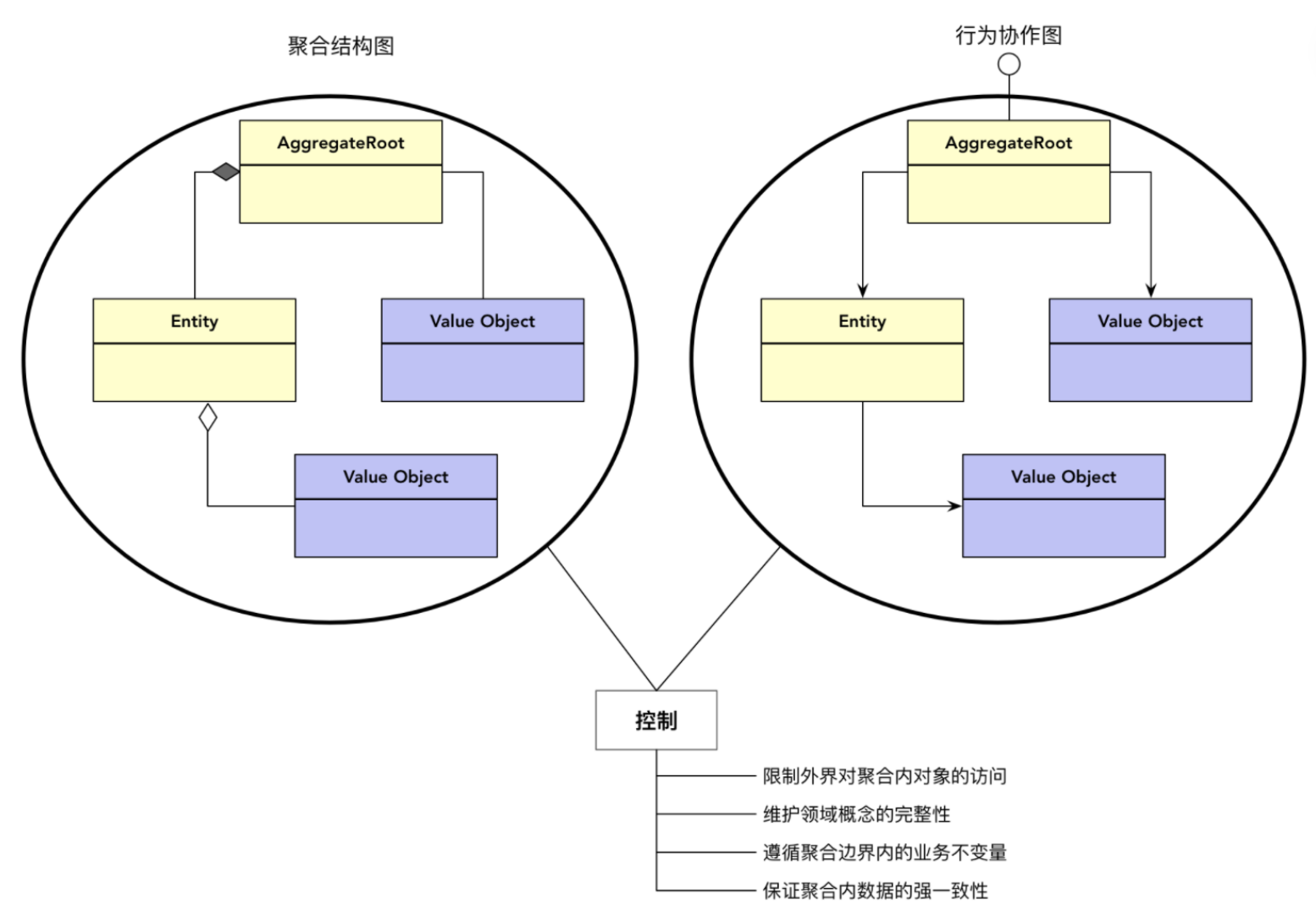
聚合由业务和逻辑紧密关联的实体和值对象组合而成,是数据修改和持久化的基本单元,每个聚合对应一个仓储,实现数据的持久化。
内容消费领域,读取、打包是常见的例子。datum 就是一种聚合,通过 loader 来加载 datum,datum 有自己的领域行为,例如校验、过滤等等。
仓储(Repository)
仓储负责聚合的「增删改查」操作,一个聚合(实体是一种特殊的聚合)对应一个仓储。
Repository VS DAO?
DAO 下,业务代码为数据层服务。DAO 操作的是数据库对象,基于此思想编写的代码,自然你的领域逻辑中就会包含数据库的读写逻辑、数据对象到领域对象的转换操作,会使得业务代码与数据库逻辑强耦合。
Repository 下,数据层为业务代码服务。Repository 的出入参是领域对象,领域层只包含领域对象,不包含仓储层对象及逻辑。因此,一旦要换底层存储,则再编写一个 Repository 接口实现就好了。
区分好领域模型、数据模型。
领域服务(Domain Service)
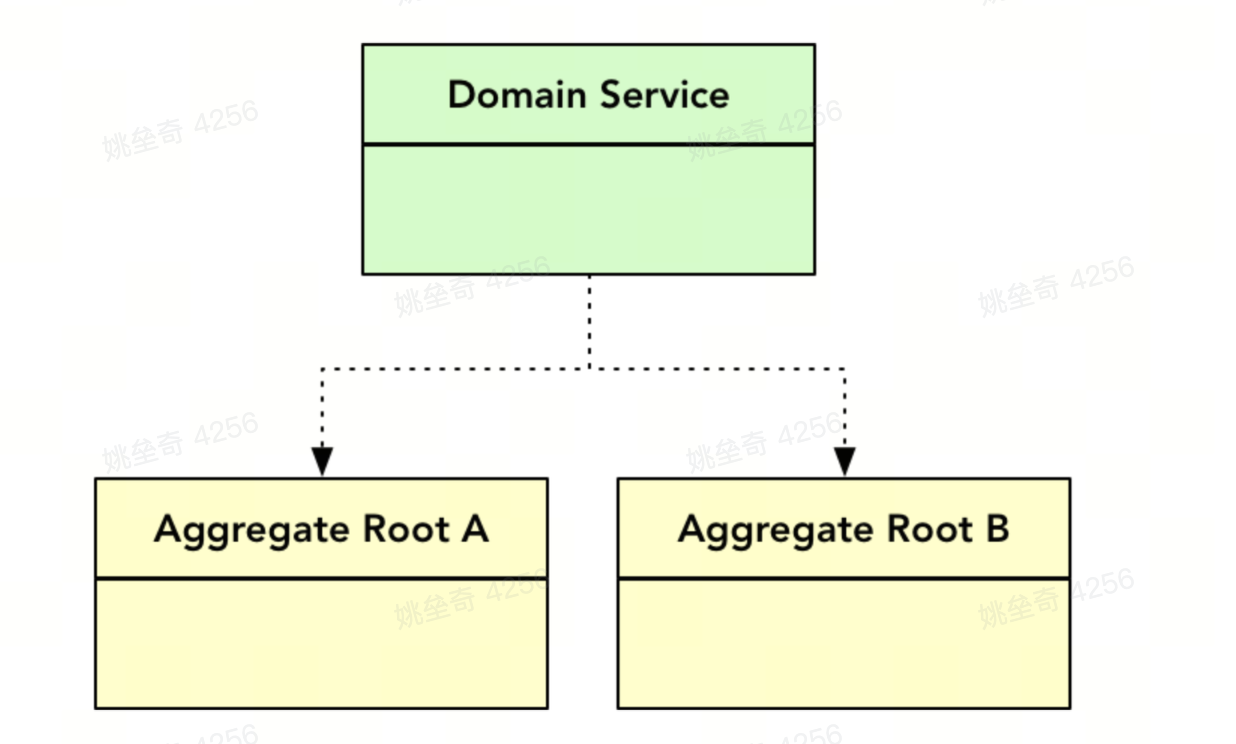
当一个自治的聚合无法完成一个完整的业务场景,需要共同协作完成时,可以引入领域服务来封装多个聚合的协作行为。
另一种场景是,如果实体的相关行为,需要引入仓储,那么也可以封装领域服务来解决。
封装为领域服务的目的是,如果有第二个场景,需要用到这一个或多个聚合的协作行为时,可以直接复用,即实现领域知识的沉淀。
分层
传统分层架构
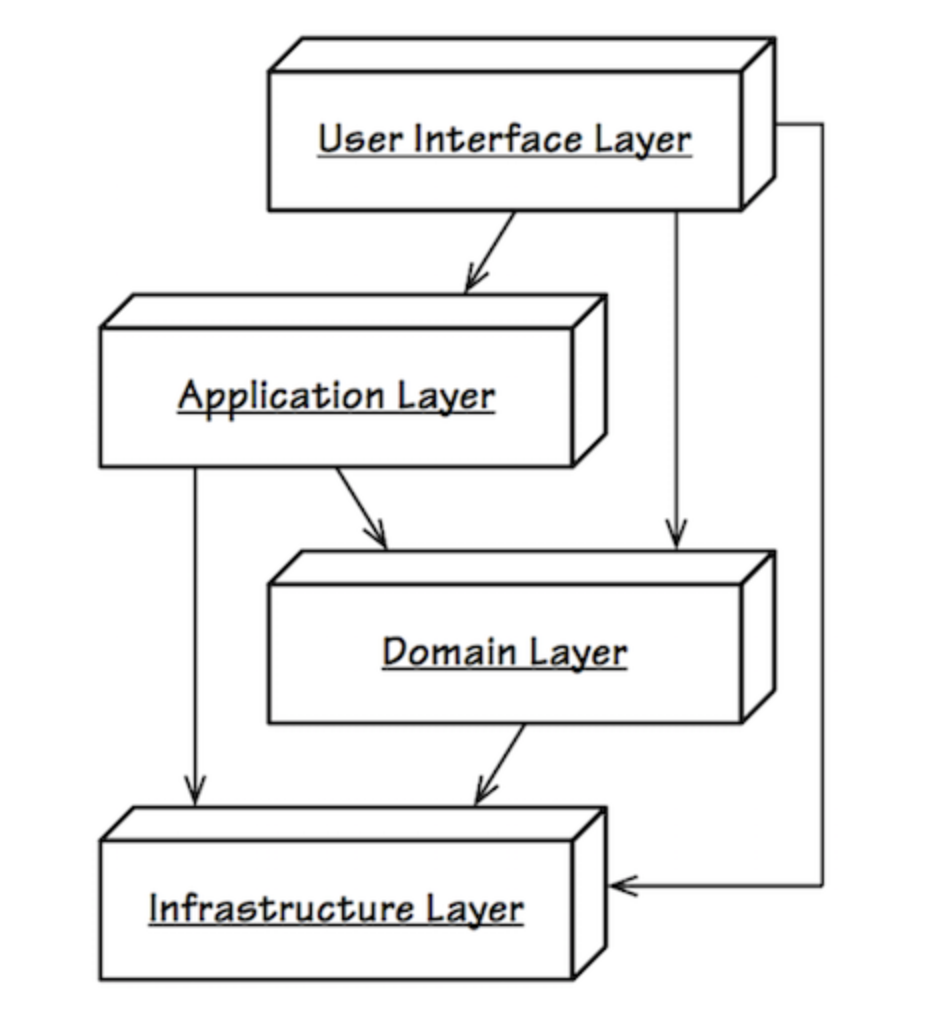
分层架构模式被认为是所有架构的始祖,被广泛地应用于Web、企业级应用和桌面应用。在这种架构中,我们将一个应用程序或者系统分为不同的层次。
分层架构的一个重要原则是:每层只能与位于其下方的层发生耦合。分层架构也分为几种:在严格分层架构中,某层只能与直接位于其下方的层发生耦合;而松散分层架构则允许任意上方层与任意下方层发生耦合。由于用户界面层和应用服务通常需要与基础设施打交道,许多系统都是基于松散分层架构的。
使用依赖倒置的分层架构
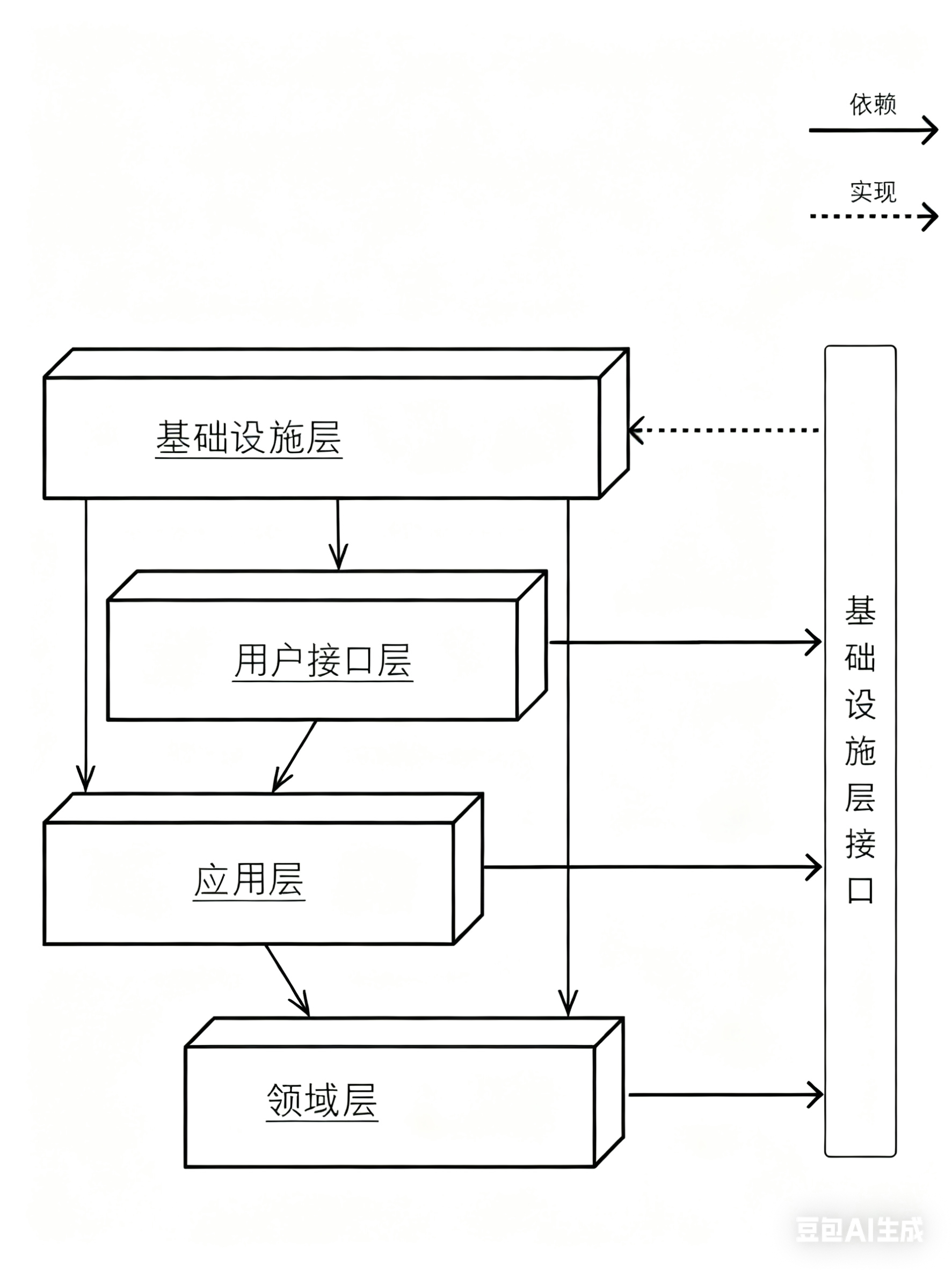
然而,在传统的分层架构中,却存在着一些问题,因为领域层或多或少地需要使用基础设施层,即领域层中的有些接口实现依赖于基础设施层。这使得业务规则和数据存储的代码耦合在一起。
在书籍《实现领域驱动设计》中,Vernon 提出了基于依赖倒置的 DDD 分层架构,来改进传统分层架构。全书提到的 DDD 架构,不额外说明的情况下,都是基于该思想作为具体落地实现(具体来说是用六边形架构)。
依赖倒置原则(Dependency Inversion Principle,DIP),由 Robert C. Martin 于 1996 年提出,其定义如下:
高层模块不应该依赖于低层模块,两者都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。该原则的提出具备重大意义,后面提到的六边形架构、洋葱架构、整洁架构,都是基于依赖倒置的分层架构的变种,没有实质上改变。
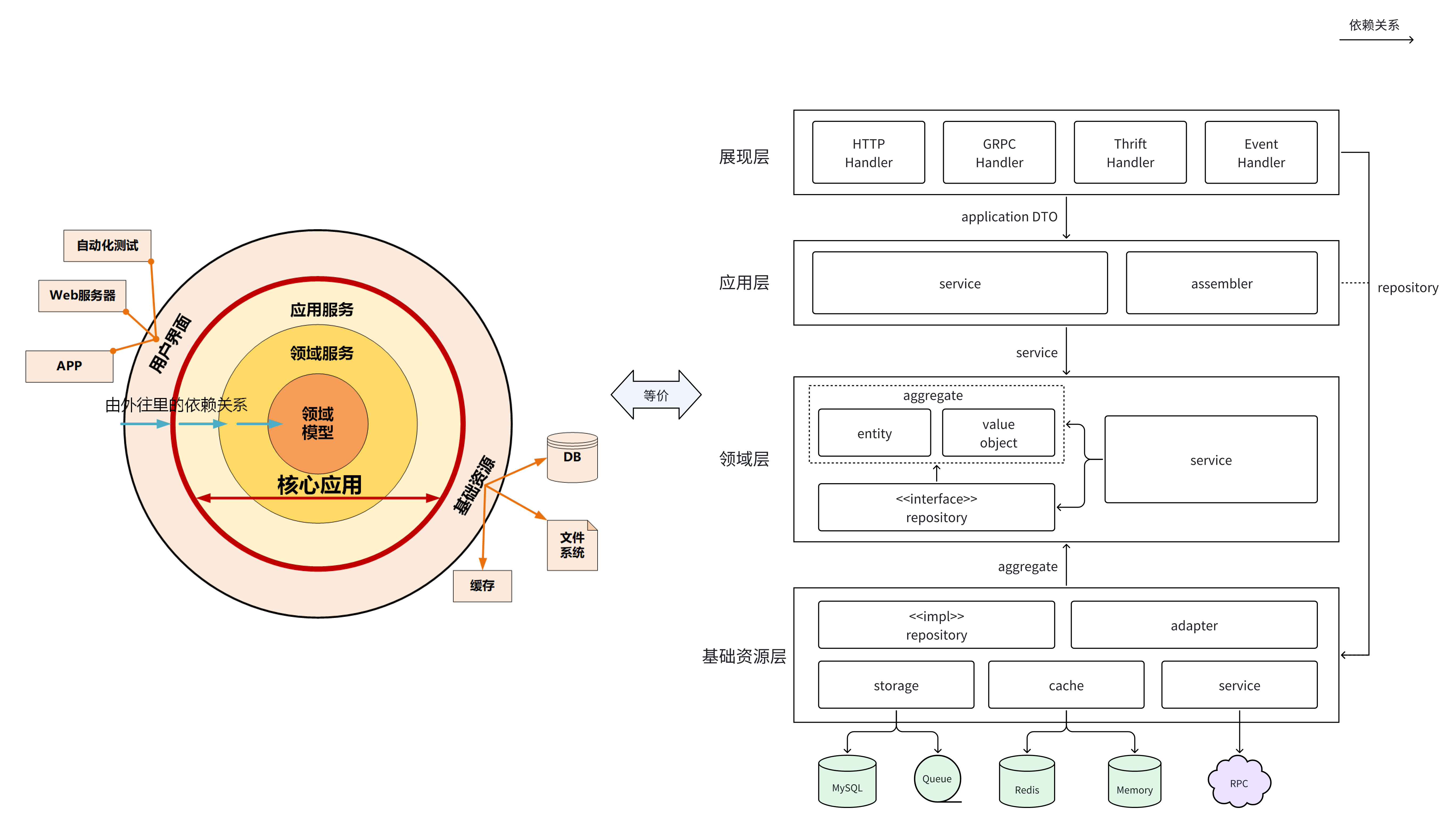
用户接口层
| 职责 | 即常见的 Hanlder。用户接口层负责向用户显示信息和解释用户指令。这里的用户可能是:用户、程序、自动化测试和批处理脚本等等。 |
|---|---|
| 注意 | 如果用户界面使用了领域模型中的对象,那么此时的领域对象仅限于数据的渲染展现。在采用这种方式时,可以使用展现模型(Presentation Model,14)对用户界面与领域对象进行解耦。 否则,领域对象修改,可能会导致展示层变化;或者展示层逻辑入侵领域层。 |
| 输入输出 | + 输入:用户请求 + 输出:展示层对象 |
| 核心组件 | assembler:对应用层返回的 DTO 做适配,返回不同前端所需数据 |
| 规范 | 请求对象是有业务“语意”的,尽量避免复用,哪怕参数是一样的。 即,每个接口 req/resp 的 IDL 定义不复用。 |
DTO 是什么?
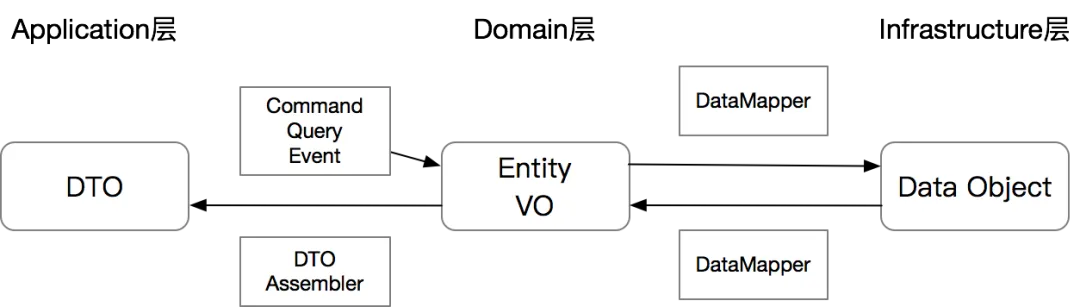
DTO Assembler:在Application层,Entity 到 DTO 的转化器有一个标准的名称叫 DTO Assembler。Martin Fowler 在 P of EAA 一书里对于 DTO 和 Assembler 的描述:Data Transfer Object。DTO Assembler 的核心作用就是将一个或多个相关联的 Entity 转化为一个或多个 DTO。
Data Converter:在 Infrastructure 层,Entity 到 DO 的转化器没有一个标准名称,但是为了区分 Data Mapper,我们叫这种转化器 Data Converter。这里要注意 Data Mapper 通常情况下指的是 DAO。
应用层
| 职责 | 应用层是很薄的一层,理论上不应该有业务规则或逻辑,主要面向用例和流程相关的操作。但应用层又位于领域层之上,因为领域层包含多个聚合,所以它可以协调多个聚合的服务和领域对象完成服务编排和组合,协作完成业务操作。 |
|---|---|
| 注意 | 在设计和开发时,不要将本该放在领域层的业务逻辑放到应用层中实现。因为庞大的应用层会使领域模型失焦,时间一长你的微服务就会演化为传统的三层架构,业务逻辑会变得分散、难以维护。 |
| 输入输出 | + 输入:用户请求 + 输出:DTO |
| 核心组件 | + assembler:对领域层、repo 层返回的 entity、aggr 做组装、适配,这个中间对象叫做 DTO + app_service:若编排在多个场景使用,则可以封装为 app_service 供多个 handler 调用 |
| 规范 | 应用服务只负责业务流程串联,不负责业务逻辑。业务逻辑内聚到 domain 实现。 |
常用的ApplicationService“套路”
我们可以看出来,ApplicationService 的代码通常有类似的结构:AppService 通常不做任何决策,仅仅是把所有决策交给 DomainService 或 Entity,把跟外部交互的交给 Infrastructure 接口,如 Repository 或防腐层。
一般的“套路”如下:
- 准备数据:包括从外部服务或持久化源取出相对应的 Entity、Aggr 以及外部服务返回的 DTO。
- 执行操作:包括新对象的创建、赋值,以及调用领域对象的方法对其进行操作。需要注意的是这个时候通常都是纯内存操作,非持久化。
- 持久化:将操作结果持久化,或操作外部系统产生相应的影响,包括发消息等异步操作。
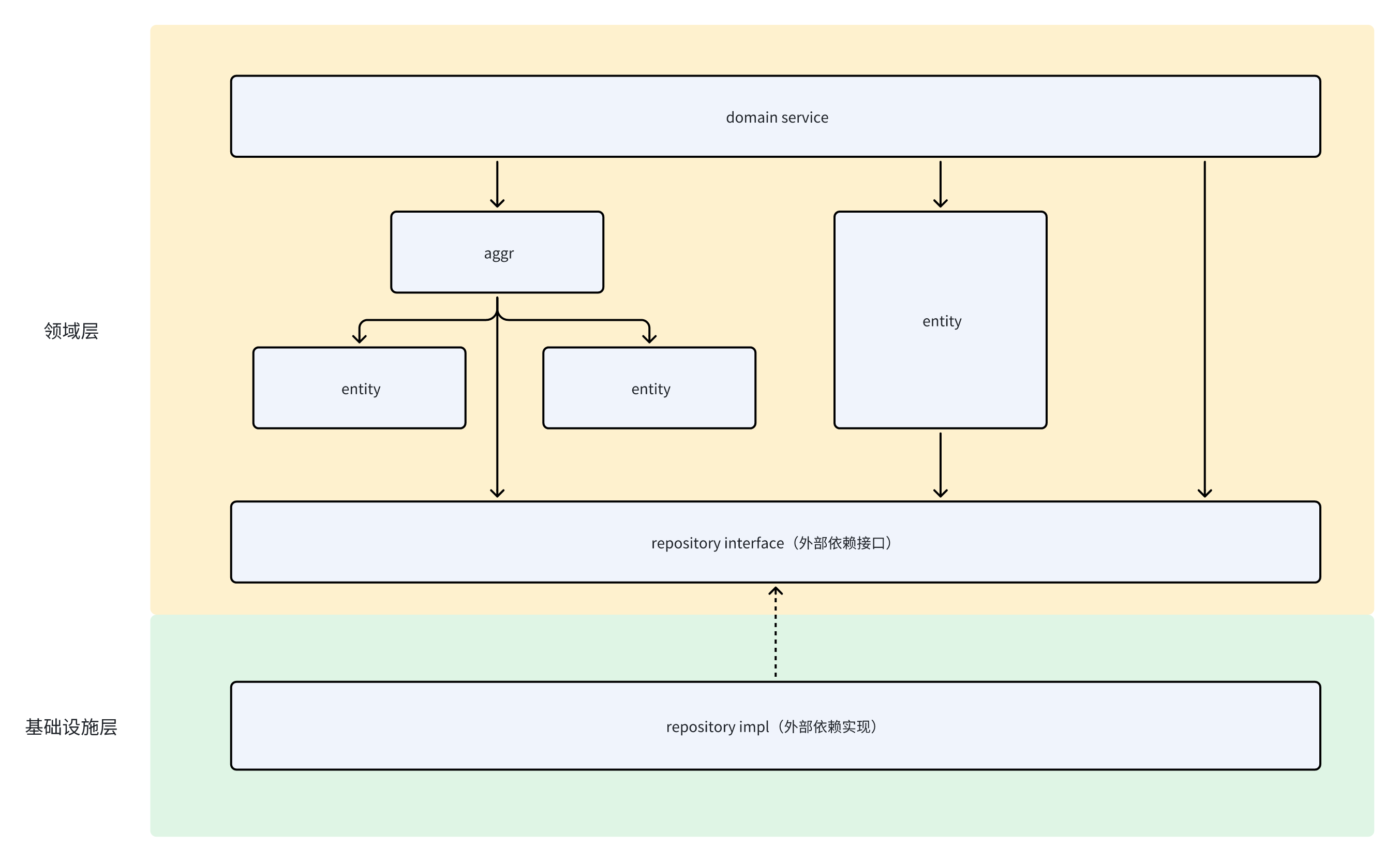
领域层
| 职责 | 领域层的作用是实现企业核心业务逻辑,通过各种校验手段保证业务的正确性。领域层主要体现领域模型的业务能力,它用来表达业务概念、业务状态和业务规则。 |
|---|---|
| 注意 | 领域层的对当前系统的依赖只有领域层 |
| 核心组件 | + 聚合根、实体、值对象、领域服务 + 仓储接口 |
| 规范 | + 对依赖进行抽象接口设计(repo interface),使得业务逻辑和技术实现是相互隔离的。 + entity 只负责内存操作,不负责数据的存储。存储交给 inf/repo 层实现。 + 当操作涉及两个或以上的 entity 时,应该使用聚合根,放在 domain/aggr 目录下 + 当重要的逻辑无法挂到 entity、aggr 上来实现时,或者需要引入 repo,可以考虑构建领域服务,放在 domain/service 目录下。 |
传统开发方法中,是面向数据开发,即在业务逻辑中适配数据库的数据。在 DDD 思想中,领域层、应用层需要什么数据,约定好接口即可,交给 infra 层来实现。
在传统架构设计中,由于上层应用对数据库的强耦合,很多公司在架构演进中最担忧的可能就是换数据库了,因为一旦更换数据库,就可能需要重写大部分的代码,这对应用来说是致命的。那采用依赖倒置的设计以后,应用层就可以通过解耦来保持独立的核心业务逻辑。当数据库变更时,我们只需要更换 repository 实现就可以了,这样就将资源变更对应用的影响降到了最低。
基础层
| 职责 | 基础层是贯穿所有层的,它的作用就是为其它各层提供通用的技术和基础服务,包括第三方工具、驱动、消息中间件、网关、文件、缓存以及数据库等。比较常见的功能还是提供数据库持久化。 |
|---|---|
| 注意 | 基础层包含基础服务,它采用依赖倒置设计,封装基础资源服务,实现应用层、领域层与基础层的解耦,降低外部资源变化对应用的影响。 |
| 输入输出 | + 输入/输出:通常是原始数据类型、领域对象 |
| 核心组件 | + repo:实现领域层、应用层约定的 interface + dependency:service/db/cache 等所有外部依赖 |
| 规范 | repo 的入参和出参除了原始数据类型,只能包含领域对象 |
小结
在传统架构中,代码从上到下的变化速度基本上是一致的,改个需求需要从接口、到业务逻辑、到数据库全量变更,而第三方变更可能会导致核心业务代码的重写。但是在 DDD 中不同模块的代码的演进速度是不一样的:
- Domain 层属于核心业务逻辑,属于经常被修改的地方。比如:原来不需要扣手续费,现在需要了之类的。通过 Entity 能够解决基于单个对象的逻辑变更,通过 Domain Service 解决多个对象间的业务逻辑变更。顺便你会发现,改了一个 domain 逻辑,所有的应用层都会受益。
- Application 层属于 Use Case(业务用例)。业务用例一般都是描述比较大方向的需求,接口相对稳定,特别是对外的接口一般不会频繁变更。添加业务用例可以通过新增 Application Service 或者新增接口实现功能的扩展。
- Infrastructure 层属于最低频变更的。一般这个层的模块只有在外部依赖变更了之后才会跟着升级,而外部依赖的变更频率一般远低于业务逻辑的变更频率。
所以在 DDD 架构中,能明显看出越外层的代码越稳定,越内层的代码演进越快,真正体现了领域“驱动”的核心思想。
架构选型
六边形架构
https://medium.com/ssense-tech/hexagonal-architecture-there-are-always-two-sides-to-every-story-bc0780ed7d9c
2005 年六边形架构被提出,比较鲜明的特点是将上下层结构换成同心圆结构,同心圆内层代表了应用的业务逻辑,外层代表应用的用户接口(driving-side)及外部资源(driven-side)。
如右上图,红圈内的核心业务逻辑(应用程序和领域模型)与外部资源(包括应用的上游比如APP、Web 应用等,以及应用的下游比如数据库、缓存等)完全隔离,两者通过适配器进行交互,很好地实现了系统核心业务与外部依赖资源的解耦。通过适配器负责内层和外层的协议转换,使得系统核心业务能够以一致的方式被上游访问(不同的协议比如HTTPs、消息队列等,可以用不同适配器访问),也能适配不同的下游存储引擎。
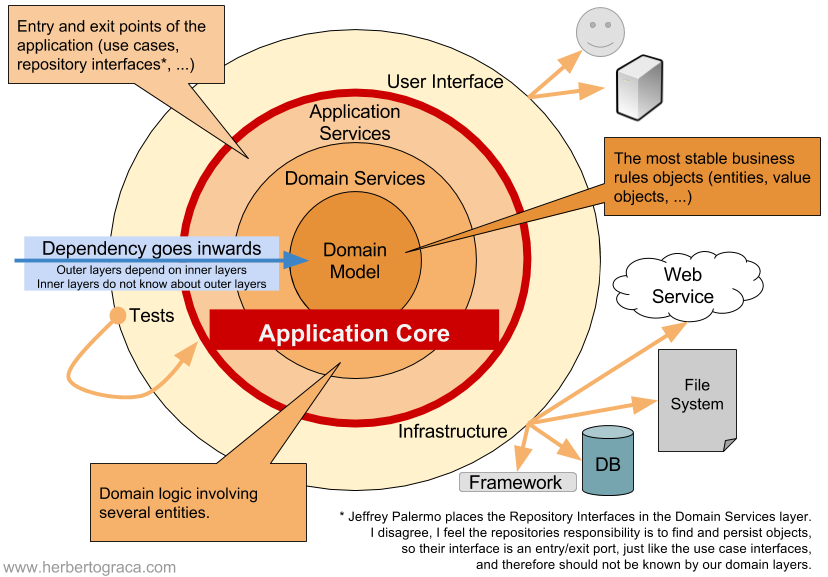
洋葱架构
2008 年洋葱架构被提出。洋葱架构可以看作是六边形架构的衍生,两者有相同的思路,都主张将业务核心逻辑与外部依赖资源进行解耦,避免外部依赖代码渗透到业务核心逻辑中。此外,洋葱架构在业务逻辑中加入了一些在 DDD 分层概念,比如用户接口层、应用层、领域层和基础层。
I propose a new approach to architecture. Honestly, it’s not completely new, but I’m proposing it as a named, architectural pattern. Patterns are useful because it gives software professionals a common vocabulary with which to communicate. There are a lot of aspects to the Onion Architecture, and if we have a common term to describe this approach, we can communicate more effectively.
原文:https://jeffreypalermo.com/2008/07/the-onion-architecture-part-1/
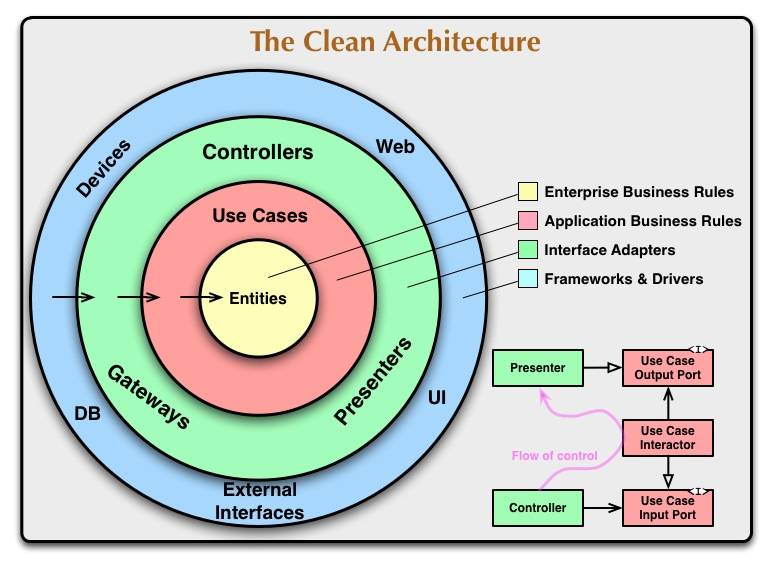
整洁架构
整洁架构,是 Robert C. Martin 在 2012 年提出的概念,本质上没有提出新的架构模式,而是整合了六边形架构、洋葱架构等架构模式,统一了命名及规范,让开发者可以使用统一的语言进行交流。
Though these architectures all vary somewhat in their details, they are very similar. They all have the same objective, which is the separation of concerns. They all achieve this separation by dividing the software into layers. Each has at least one layer for business rules, and another for interfaces.
原文:https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
解析:https://betterprogramming.pub/the-clean-architecture-beginners-guide-e4b7058c1165
小结
基于依赖倒置原则的分层架构及其派生出来的各种架构模式,其思想是高度一致的。除了命名不一样、切入点不一样之外,其他的整体架构都是基于一个二维的内外关系。这也说明了基于DDD的架构最终的形态都是类似的。
概括起来,有以下几个核心点:
- 抽象不依赖细节,细节应该依赖抽象。
- 内层模块不感知外层模块的存在。
- 业务逻辑应该高度内聚在领域层。
即使遵循上述架构模式,具体落地的时候,仍然有非常多的细节值得注意。
总结
DDD 不是一个什么特殊的架构,而是任何传统代码经过合理的重构之后最终一定会抵达的终点。DDD 的架构能够有效的解决传统架构中的问题:
- 高可维护性:当外部依赖变更时,内部代码只用变更跟外部对接的模块,其他业务逻辑不变。
- 高可扩展性:做新功能时,绝大部分的代码都能复用,仅需要增加核心业务逻辑即可。
- 高可测试性:每个拆分出来的模块都符合单一性原则,绝大部分不依赖框架,可以快速的单元测试,做到100%覆盖。
- 代码结构清晰:当团队形成规范后,可以快速的定位到相关代码。
Reference
- 蓝皮书《领域驱动设计》Eric Evans
- 红皮书《实现领域驱动设计》Vaughn Vernon
- 优秀 DDD 博客
- 殷浩谈DDD系列(这系列强烈推荐,整体思路很清晰,实操性比较强)
- 一些 DDD 资源汇总 https://github.com/evancyz/ddd-learning?tab=readme-ov-file