Caffeine 的实现原理
缓存算法其实包含两个部分,准入策略(Admission Policy)以及淘汰策略(Eviction Policy)。一般情况下,对于一个元素,我们先判断是否接受该元素(使用准入策略),若接受的话,则从 Cache 中选择一个替代品(使用淘汰策略),从而把新元素放到 Cache 中。
本文重点介绍 JAVA 中著名的缓存方案 Caffeine 的底层实现,即 Tiny-LFU 算法,并首先简明地介绍了各个常见的缓存淘汰算法,包括实现原理以及优缺点讨论。
码字不易,转载请声明出处,否则后果自负。
缓存淘汰算法
LRU
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是 “如果数据最近被访问过,那么将来被访问的几率也更高”。
实现
通常使用链表实现,靠前的代表最近访问,靠后的代表不经常访问。当 Cache 满的时候,将 Cache 中最不经常访问的元素(链表的尾部节点)驱逐,并全盘接受新来的元素,直接插入到链表头部。
优缺点
当存在热点数据时,LRU 的效率很好,但偶发性的、周期性的批量操作会导致 LRU 命中率急剧下降,缓存污染情况比较严重,即会缓存大量长尾数据。
LRU-K
LRU-K(Least Frequently Used K) 中的 K 代表最近使用的次数,因此 LRU 可以认为是 LRU-1,该算法相当于结合了 LRU 与 LFU 的思想。LRU-K 的主要目的是为了解决 LRU 算法 “缓存污染” 的问题,其核心思想是将 “最近使用过 1 次” 的判断标准扩展为 “最近使用过 K 次”。
实现
需要维护一个记录表来记录元素的访问次数,当且仅当元素的访问次数大于阈值 K 的时候,才将元素移动到 Cache 中。淘汰策略还是 LRU,只是相当于准入门槛变高而已。
优缺点
LRU-K 避免了长尾请求对 LRU 的影响。但是由于 LRU-K 还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比 LRU 要多;另外,当 K 值的取值需要权衡,当 K 值很大的时候,LRU-K 的适应能力会变差,需要大量数据访问才能将历史访问清除。
ARC
ARC(Adaptative Replacement Cache)结合了 LRU 跟 LFU 两个策略,维护了两个 LRU Cache(L1, L2)。L1 缓存只访问过一次的,L2 缓存至少访问过两次的。
实现
ARC 从 L1、L2 中分别划出两个子列表 T1、T2,其中 T1 代表最近访问,T2 代表最高频访问;并分别维护两个僵尸(Ghost)列表 B1、B2,分别存储从 T1、T2 中被驱逐的元素,B1、B2 都使用 LRU 策略。当两个 Cache 满了的时候,如果 T1 中的数据被驱逐,则该数据被存储到 B1 中,同理,T2 驱逐的数据存到 B2 中。
T1 与 T2 的长度的动态调整,体现了一种负反馈调节的思想:
-
如果 B1 中的数据经常被访问,则说明 T1 不够长,所以会拓展 T1 长度,缩短 T2 长度,表现更像 LRU。
-
如果 B2 中的数据经常被访问,则说明 T2 不够长,所以会拓展 T2 长度,缩短 T1 长度,表现更像 LFU。
优缺点
ARC 解决了 LRU 中 Non-Scan-Resistent 问题,即对于某些长尾请求,会导致 T1 中缓存了大量长尾数据,但是 T2 却不会受很大影响。
SLRU
SLRU(Segmented LRU)将 LRU 分成保护段(protected segment)和试用段(probationary segment),其实思想跟 ARC 差不多,只不过没有动态调节段的占比,而且只有 T1 与 T2 之间的交换,舍弃了 B1、B2。保护段缓存访问超过一次的,试用段则全盘接受新来的数据。
实现
新数据会被存储在试用段,后续如果被访问到,则被提升到保护段。当保护段满的时候,数据会被淘汰至试用段,这时候如果试用段也满了的话,则联动使用 LRU 驱逐。
局限性
在该实现中,保护段与试用段的占比是固定的,因此对于分布经常变动的请求是次于 ARC 的。
LFU
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是 “如果数据过去被访问多次,那么将来被访问的频率也更高”。
实现
LFU 记录数据历史访问记录,即对极大部分数据(包括被驱逐的)都维护一个引用计数,当 Cache 满的时候,将 Cache 中频率最低的与新来的(频率高的)进行交换,并更新 Cache 中的排序(通常用最小堆实现)。
优缺点
一般情况下,LFU 效率要优于 LRU,且能够避免周期性或者偶发性的操作导致缓存命中率下降的问题。但 LFU 需要记录数据的历史访问记录,一旦数据访问模式改变,LFU 需要更长时间来适用新的访问模式。
另一方面,经典算法中,维护引用计数需要占用大量内存空间,并且每次更新都需要重新依照访问计数排序,在实际应用中不可能直接这么硬干。
LFU-Aging
基于 LFU 的改进算法,其核心思想是 “除了访问次数外,还要考虑访问时间”。例如,两天前的一个热门视频在今天可能无人问津,但是因为访问频率曾经非常高,导致这个视频依然占坑在缓存中。
实现
该算法的实现其实有很多种,例如 In-Memory LFU 采用了两个策略:
- 限制最高访问计数。即达到阈值则不再增加计数。
- 周期性对引用计数作衰减操作,例如除予某个系数。
优缺点
LFU-Aging 因为减少了 LFU 带来的高频旧数据的缓存污染问题,相比于 LFU 能够更快适应新的访问模式。但是依然避免不了 LFU 的两个问题,并且衰减系数也是个参数活,需要慢慢调节。
Window-LFU
上述 LFU-Aging 解决了 LFU 其中一个痛点,即不适应访问模式的剧烈变化。而 Window-LFU 旨在解决 LFU 需要维护所有数据的访问历史带来的巨大内存消耗的问题。顾名思义,Window-LFU 维护了一个定长计数窗口,记录最近访问的 W 个元素的访问计数。
实现
维护一个长度 W 的 FIFO 计数队列(Window),记录最近 W 个元素,元素的计数以 Window 中的计数为准,当 Cache 满了的时候,用 WIndow 中的计数进行驱逐。
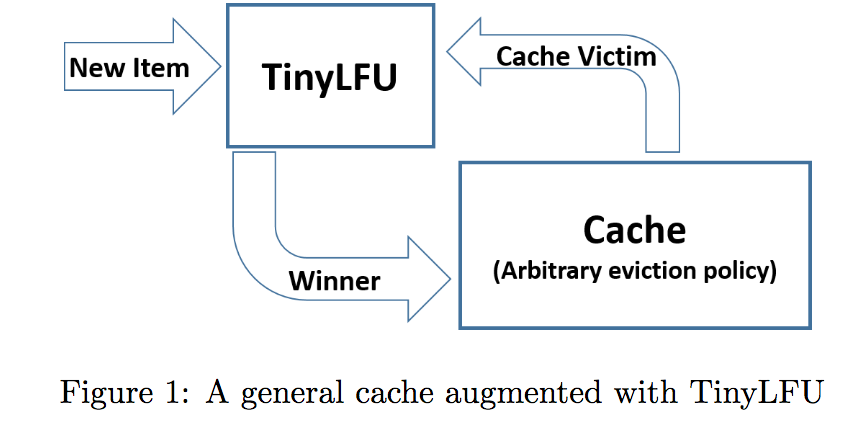
TinyLFU
顾名思义,TinyLFU 也是 LFU 的一种变体,TinyLFU 方案可以分为两个重要部分,分别是实现 TinyLFU 的准入策略和 Cache 实现的驱逐策略(可以使用多种置换方案,如 LFU、LRU)。当新来一个元素时,Cache 选择要驱逐的元素(victim),TinyLFU 通过引用计数判断替换为新来的元素是否有收益(即是否会带来更高的命中率)。
近似引用计数
近年来有很多针对大数据流的统计研究,期望得到一种压缩的数据结构,例如用来反映数据流中元素的出现频率。比较著名的一类算法是基于布隆过滤器的 Sketch。布隆过滤器用来判断一个给定元素是否存在,而 Sketch 用来判断给定元素出现的频率,具体的做法与布隆过滤器类似,使用一组哈希函数,映射到引用计数矩阵的某几个值,通过对应的几个结果值来反映给定元素的近似出现频率。例如,Minimal Increment Counting Bloom Filter 取的是几个哈希结果的最小值作为频率的近似值,每次新增元素也只对最小计数值进行递增操作。
但是这类算法有一个问题,现实中的数据流通常带有大量长尾请求,这些请求的出现频率非常低,很容易就把 Sketch 打得饱和,使得计数有很大误差。
TinyLFU 提出的方案很简单,每次添加一个新元素时,则对一个 counter 进行递增,当计数达到某一个阈值的时候,则对所有计数器作衰减操作(乘上某个衰减系数)。
由于 counter 都是整型,因此长尾元素的计数大概率会被衰减操作置零;另外一方面,衰减操作也会把高频的旧数据逐渐置零,相当于一个 Aging 操作。

准入策略
上文提到,TinyLFU 负责准入策略,其实就是把即将淘汰的元素(Cache 中的 victim)与即将到来的元素进行对比,对比的依据是两者在 Sketch 中的计数。
虽然上述 Sketch 的重置方案能够解决长尾数据带来的缓存污染问题,但是 TinyLFU 还引入了布隆过滤器,后面称为 Doorkeeper,来进一步减少这个问题的影响。具体的做法如下:
- 判断新来的元素是否在 doorkeeper 中,没有的话,则插入 doorkeeper,否则插入 Sketch 中
- 当请求一个元素的时候,如果元素在 doorkeeper 中的话,则返回 Sketch 中的计数+1,否则直接返回 Sketch 中的计数。

每次对 Sketch 进行重置的时候,也需要对 doorkeeper 进行清空操作。
由于前置布隆过滤器 Doorkeeper 的存在,计数为整型的 Sketch 占用的内存可以更小,因为一些长尾请求已经被 Doorkeeper 拒之门外。
驱逐策略
其实驱逐策略很简单,就是一个普通的 LFU 策略,每次需要淘汰的时候,选择频率最小(通常用最小堆实现)的元素进行替换。
W-TinyLFU
TinyLFU 其实对一些突如其来的高频请求不够友好,因为这些请求很可能在积攒足够频率之前就被淘汰了,通常来说,LRU 对这类请求有着更好的效果。

在该结构中,Cache 使用 SLRU 驱逐策略及 TinyLFU 准入策略,而 Window 则使用 LRU 驱逐策略并全盘接受任何新元素(没有准入门槛)。
每当一个元素进来时,都会被 Window 接受,被 Window 淘汰的元素有机会通过 Filter(Doorkeeper+Sketch)与 Cache 中的元素竞争。如果竞争成功的话,则相当于 Cache 中的元素被驱逐,否则相当于 Window 中的元素被驱逐。
可以看到 W-TinyLFU 兼具了 LRU 与 LFU 的优点。该算法也是 JAVA 中著名的缓存 Caffeine 的底层实现方案。
Reference
- ARC 算法:https://blog.csdn.net/WSKINGS/article/details/46416451
-
Caffein 简介:http://highscalability.com/blog/2016/1/25/design-of-a-modern-cache.html
- Tiny-LFU 论文:https://arxiv.org/pdf/1512.00727.pdf
- 论文简单解读:https://segmentfault.com/a/1190000016091569?utm_source=tag-newest