浅谈 Golang 编译原理及其应用
TL;DR;本文简要介绍 Golang 编译的各个阶段干了什么,即从源文件到最终的机器码中间经历的过程。并从汇编代码、AST 入手介绍了相关的应用场景及实现原理。本文第一节深度参考了 解析器眼中的 Go 语言,也非常推荐有时间的读者阅读原文。
编译原理
编译器的前端一般承担着词法分析、语法分析、类型检查和中间代码生成几部分工作.
编译器后端主要负责目标代码的生成和优化,也就是将中间代码翻译成目标机器能够运行的二进制机器码。
词法分析
过程:源代码文件 => 词法分析(lexer) => Token 序列
词法分析:词法分析是将字符序列转换为 Token 序列的过程。源代码在计算机看来其实就是一个由字符组成的、无法被理解的字符串,所有的字符在计算器看来并没有什么区别,为了理解这些字符我们需要做的第一件事情就是将字符串分组,即转换为 Token 序列,这能够降低理解字符串的成本,简化源代码的分析过程,这个转换的过程就是词法分析。
func (s *scanner) next() {
// ...
s.stop()
startLine, startCol := s.pos()for s.ch == ' ' || s.ch == '\t' || s.ch == '\n' && !nlsemi || s.ch == '\r' {
s.nextch()
}
s.line, s.col = s.pos()
s.blank = s.line > startLine || startCol == colbase
s.start()
if isLetter(s.ch) || s.ch >= utf8.RuneSelf && s.atIdentChar(true) {
s.nextch()
s.ident()return
}
switch s.ch {
case -1:
s.tok = _EOF
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(false)
// ...
}
}
上述节选的代码是遍历源文件不断获取最新的字符,将字符通过 cmd/compile/internal/syntax.source.nextch 方法追加到 scanner 持有的缓冲区中,并在 cmd/compile/internal/syntax.scanner.next 中对最新的字符进行词法分析的过程。
语法分析
过程:Token 序列 => 语法分析 => AST
语法分析:语法分析是根据某种特定的文法,对 Token 序列构成的输入文本进行分析并确定其语法结构的过程。语法分析由文法、分析方法构成。文法描述了语法的组成,分析方法则是解析文法的过程。
文法
上下文无关文法是用来形式化、精确描述某种编程语言的工具,我们能够通过文法定义一种语言的语法,它主要包含一系列用于转换字符串的生产规则(Production rule)。
The Go Programming Language Specification(Go 语言说明书)使用 EBNF 范式对 Golang 语法进行描述。
下面是使用 EBNF 范式对 EBNF 本身进行描述:
Production = production_name "=" [ Expression ] "." .
Expression = Alternative { "|" Alternative } .
Alternative = Term { Term } .
Term = production_name | token [ "…" token ] | Group | Option | Repetition .
Group = "(" Expression ")" .
Option = "[" Expression "]" .
Repetition = "{" Expression "}" .
生产规则是由 Term 与下述操作符组成:
| alternation
() grouping
[] option (0 or 1 times)
{} repetition (0 to n times)
"" string
. terminator symbol
src/cmd/compile/internal/syntax/parser.go 文件中描述了 Go 语言文法的生产规则:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
PackageClause = "package" PackageName .
PackageName = identifier .
ImportDecl = "import" ( ImportSpec | "(" { ImportSpec ";" } ")" ) .
ImportSpec = [ "." | PackageName ] ImportPath .
ImportPath = string_lit .
TopLevelDecl = Declaration | FunctionDecl | MethodDecl .
Declaration = ConstDecl | TypeDecl | VarDecl .
从上述 SourceFile 相关的生产规则我们可以看出,每一个文件都包含一个 package 的定义以及可选的 import 声明和其他的顶层声明(TopLevelDecl),每一个 SourceFile 在编译器中都对应一个 cmd/compile/internal/syntax.File 结构体,可以从该定义中轻松找到两者的联系:
type File struct {
Pragma Pragma
PkgName *Name
DeclList []Decl
Lines uint
node
}
分析方法
语法分析的分析方法一般分为自顶向下和自底向上两种,这两种方式会使用不同的方式对输入的 Token 序列进行推导:
- 自顶向下分析:解析器会从开始符号分析,通过新加入的字符判断应该使用什么生产规则展开当前的输入流;
- LL 使用自顶向下分析方法
- 自底向上分析:解析器会从输入流开始,维护一个栈用于存储未被归约的符号,当栈中符号满足规约条件,则会规约成对应的生产规则;
- LR(0)、SLR、LR(1) 和 LALR(1) 都是使用了自底向上的处理方式;
- Lookahead:在不同生产规则发生冲突时,解析器需要通过预读一些 Token 判断当前应该用什么生产规则对输入流进行展开或者归约,例如在 LALR(1) 文法中,需要预读一个 Token 保证出现冲突的生产规则能够被正确处理。
Go 语言的解析器使用了 LALR(1) 的文法来解析词法分析过程中输出的 Token 序列,得到 AST。
AST
语法分析器最终会使用不同的结构体来构建抽象语法树中的节点,File 是根结点。
type File struct {
Pragma Pragma
PkgName *Name
DeclList []Decl
Lines uint
node
}
src/cmd/compile/internal/syntax/nodes.go 文件中也定义了其他节点的结构体,比如函数声明的结构:
type (
Decl interface {
Node
aDecl()
}
FuncDecl struct {
Attr map[string]bool
Recv *Field
Name *Name
Type *FuncType
Body *BlockStmt
Pragma Pragma
decl
}
}
这里草草了解对 AST 的说明,在「应用」一节会举一个有关 AST 的例子,这里顺便推荐一个在线解析 AST 的工具。
另外,非常推荐一本详细讲解 AST 的书籍,有兴趣的读者可以查阅 https://chai2010.cn/go-ast-book/index.html。
类型检查
过程: AST => 类型检查 => 关键字改写的 AST
得到 AST 之后,对象类型、对象值已经出来了,这时候执行类型检查是很方便的事情;如果有任何类型不匹配,则会在该阶段抛出异常,这个过程叫做静态类型检查。
与静态类型检查互补的是动态类型检查,例如我们在代码中会将 interface{} 转换成具体类型,如果无法发生转换就会发生程序崩溃,那么这里实际上涉及到动态类型检查。动态检查会依赖编译期间得到的类型信息。
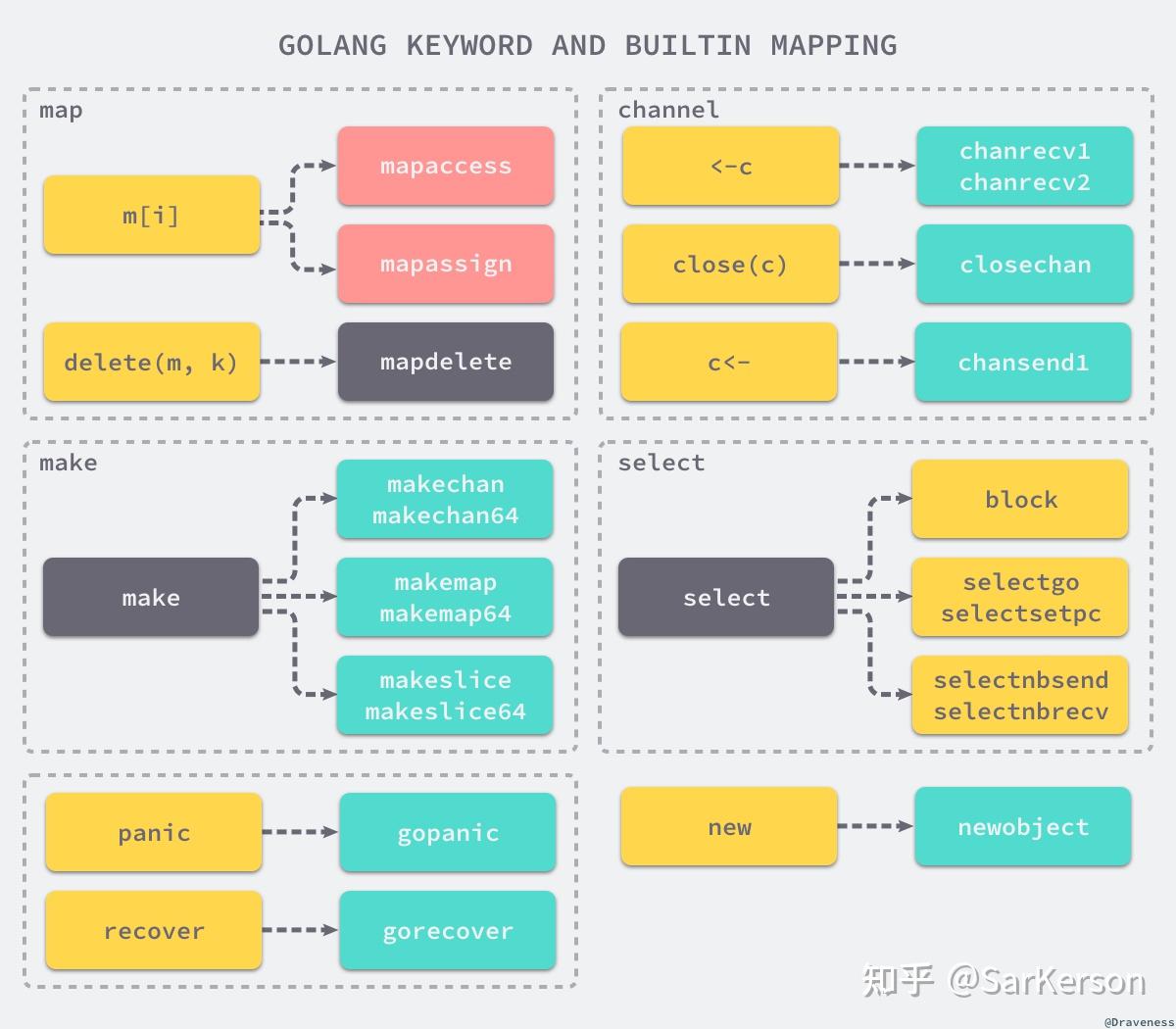
另外,执行类型检查的同时,会对内建函数进行一些替换操作,例如 make => runtime.makeslice 或者 runtime.makechan 。
中间代码生成
过程:AST => 并发编译所有函数 => SSA 等代码优化 => 中间代码
生成中间代码之前,编译器还需要替换抽象语法树中节点的一些元素,即编程语言给开发者的语法糖。该操作将一些关键字和内建函数转换成函数调用,例如: 将 panic、recover 两个内建函数转换成 runtime.gopanic 和 runtime.gorecover 两个真正运行时函数,而关键字 new 也会被转换成调用 runtime.newobject 函数。
经过 walk 系列函数的处理之后,抽象语法树就不会改变了,Go 语言的编译器会将 AST 转换为具备 SSA 特性的中间代码。
我们能在 GOSSAFUNC=func_name go build main.go 命令生成的文件中,看到指定函数 func_name,每一轮处理后的中间代码。
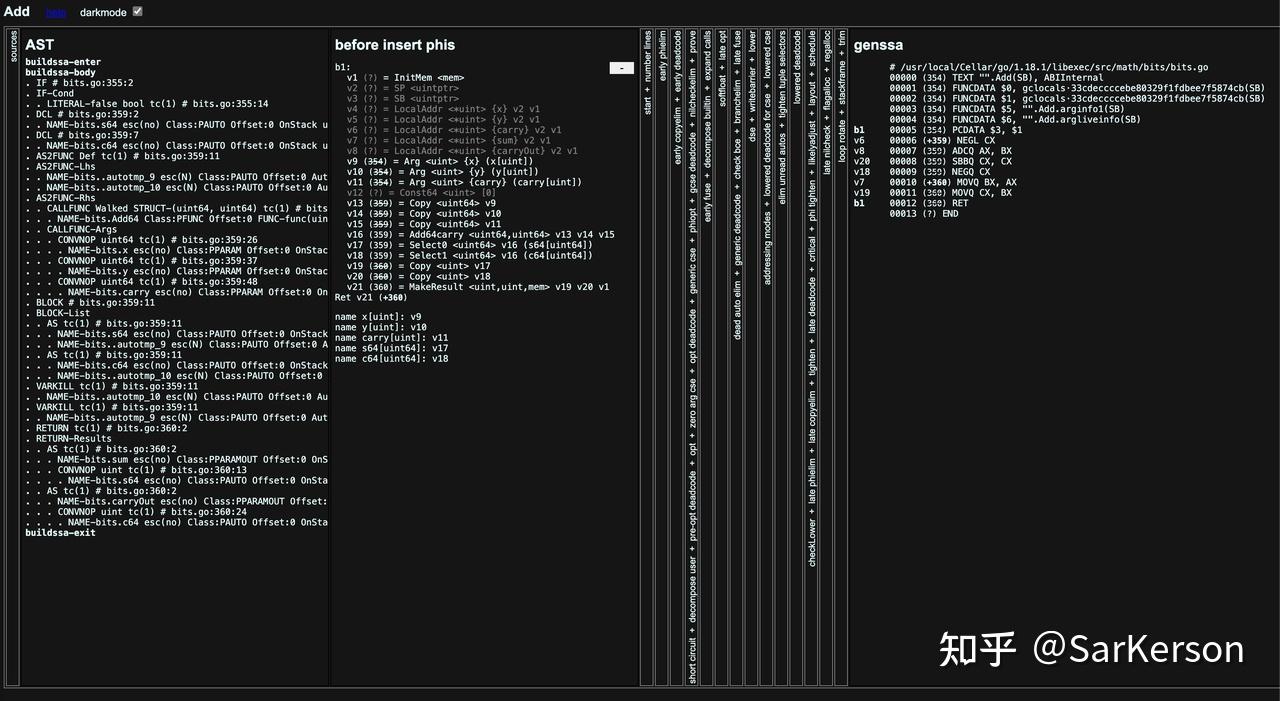
中间代码是一种更接近机器语言的表示形式,对中间代码的优化和分析相比直接分析高级编程语言更容易。
机器码生成
SSA 输出结果跟最后生成的汇编代码已经非常相似了,随后调用的 cmd/compile/internal/gc.Progs.Flush 会使用 cmd/internal/obj 包中的汇编器将 SSA 转换成汇编代码。
我们可以使用命令生成汇编代码,GOOS=linux GOARCH=amd64 go tool compile -S main.go。这种方式生产的并非标准的汇编代码,而是上节提到的中间代码。不过进行分析的话也可以使用。
如果想获得更准确,并且更加标准化的汇编代码,可以使用 go tool objdump -s <interesting_function_> main
usage: go tool objdump [-S] [-gnu] [-s symregexp] binary [start end]
-S print Go code alongside assembly
-gnu print GNU assembly next to Go assembly (where supported)
-s string
only dump symbols matching this regexp
自举
自举的定义是,使用 Golang 编写的程序来构建 Golang 编写的程序。实际上,要构建 x ≥ 5 的 Go 1.x,必须在 $GOROOT_BOOTSTRAP 中已经安装 Go 1.4(或更高版本)。而 Go 1.4 本身是依赖 C 语言的。所以这个自举过程其实也并不神秘。
应用
机器码
Monkey Patch
原理:获取 from 的函数地址 => 将跳转 to 的汇编指令替换 from 的函数体
Monkey Patch 是一个实现函数替换的工具,通常用在本地测试 Mock 数据的场景。这里简单介绍函数替换的实现原理。
举个例子,对于下述程序,我们的目标是实现某个函数replace(a, b),使得调用函数 a 的时候,实际上运行函数 b。
package main
func a() int { return 1 }
func b() int { return 2 }
func main() {
// replace(a, b)
print(a())
}
先看其汇编代码:
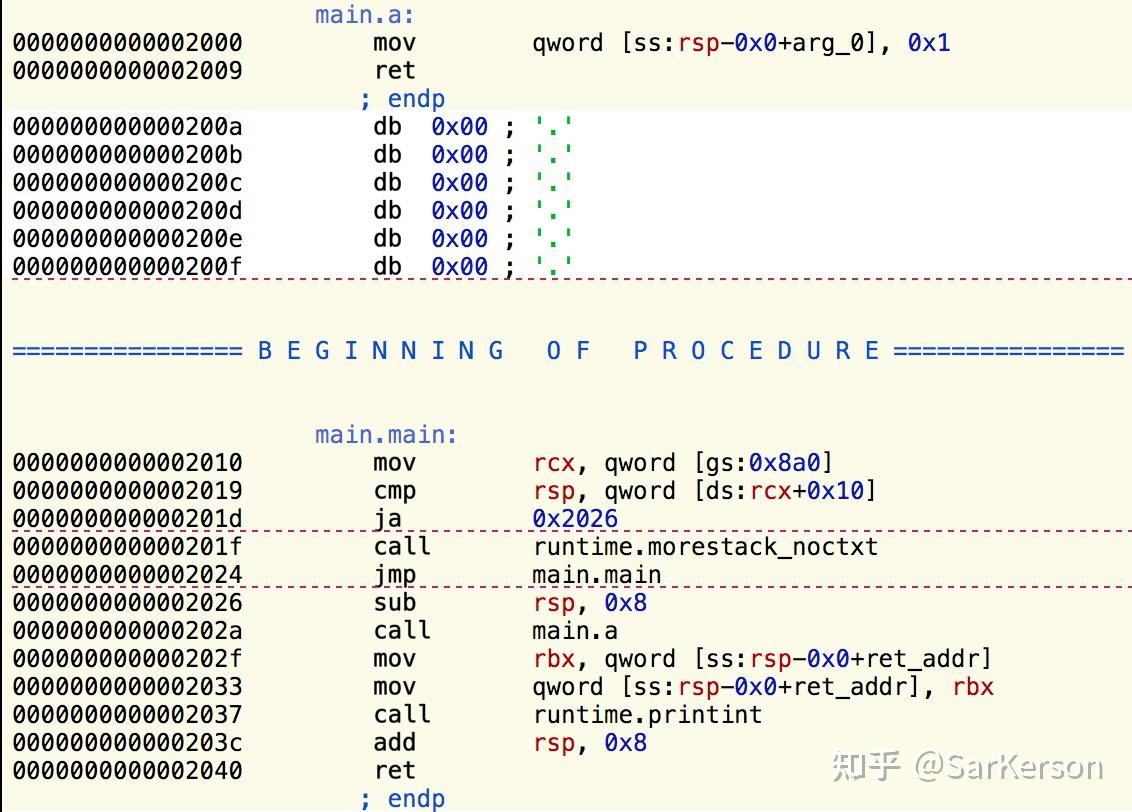
再强调一下,我们的目标是调用函数 a 的时候,实际上调用 b。
可以看到 0x2000-0x2009 是函数 main.a 的函数体。
那么,要达到目标,需要把下述汇编代码替换到 0x2000-0x2009 的内存位置。
mov rdx, main.b.f
jmp [rdx]
因此,将汇编对应的机器码(字节表示,可以使用在线汇编器进行转换)强制拷贝到函数main.a 的内存位置即可。
详细可以查阅原文,这里只是简单介绍一下实现的过程。
https://berryjam.github.io/2018/12/golang%E6%9B%BF%E6%8D%A2%E8%BF%90%E8%A1%8C%E6%97%B6%E5%87%BD%E6%95%B0%E4%BD%93%E5%8F%8A%E5%85%B6%E5%8E%9F%E7%90%86/
性能分析
我们借助 pprof 工具,对性能瓶颈进行分析。找到到更具体的问题代码块,可以再通过汇编分析等方法,定位到影响性能的代码。
下图是嵌套指针导致的指令依赖,而无法充分利用指令并行的一个例子。
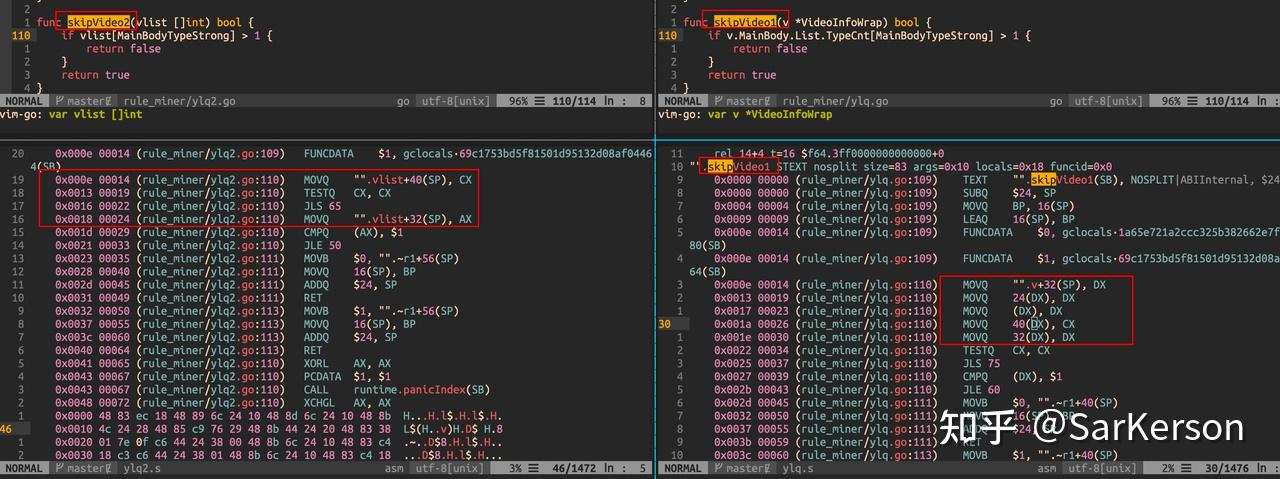
通过汇编指令分析性能瓶颈,帮助机器更好地优化,例如:
-
充分利用指令并行
-
避免不可预测的分支
-
提高指令缓存命中率
详细可以参阅 CSAPP 的第五章,之前记了相关的一段笔记:第五章 优化程序性能
AST
魔改代码
有时候,你需要批量修改代码。例如,你需要给很多个 Handler 添加一个公有的 BaseCheck 逻辑。
这时候,可选的做法是,加一个 BaseHandler 实现改 BaseCheck 方法,让其他 Handler 嵌套 BaseHandler 从而继承该公有方法。然后在所有的 Handler 的 check 方法中,调用继承过来的 BaseCheck 方法,即新增下述高亮部分的代码。
package handler
import "package_path/biz/base_handler"
type HandlerA struct {
*base_handler.BaseHandler
}
func (h *HandlerA) check() error {
// other checks by handler A
// other checks by handler A
if err := h.BaseCheck(); err != nil { // inherit from BaseHandler
return err
}
}
问题来了,当 handler 非常多(大型项目可能有几十上百个)时,手动给每个 handler 文件添加上述逻辑显然不是很爽。
回顾一下上面提到的 AST,我们可以利用 AST 解析整个 go 文件,得到所有的节点。那么当我知道需要在哪些节点上新增代码,便可以写代码来生成这部分代码,我们把这个工具暂称 generator。
这里面涉及两个步骤:
-
识别目标节点
-
插入新节点(要新增的代码块)
我们可以先手动对任何一个 handler 加这部分代码,然后观察其 AST,模仿该 AST 来编写 generator。上文提到一个在线解析 AST 的工具,我们把已经写好的 handler 贴进去,找到我们感兴趣的那部分逻辑。
例如你要给每个 Handler 的声明添加 *base_handler.BaseHandler 这个 field,我们来看对应的代码以及 AST:
type Handler struct {
*base_handler.BaseHandler
reqCtx *request.RequestContext
}
0 *ast.File {
3 . Name: *ast.Ident {
5 . . Name: "xx_handler"
7 . }
8 . Decls: []ast.Decl (len = 5) {
9 . . 0: *ast.GenDecl {}
95 . . 1: *ast.GenDecl {
96 . . . Doc: nil
98 . . . Tok: type
100 . . . Specs: []ast.Spec (len = 1) {
101 . . . . 0: *ast.TypeSpec {
102 . . . . . Doc: nil
103 . . . . . Name: *ast.Ident {
105 . . . . . . Name: "Handler"
106 . . . . . . Obj: *ast.Object {
107 . . . . . . . Kind: type
108 . . . . . . . Name: "Handler"
112 . . . . . . }
113 . . . . . }
115 . . . . . Type: *ast.StructType {
117 . . . . . . Fields: *ast.FieldList {
119 . . . . . . . List: []*ast.Field (len = 2) {
120 . . . . . . . . 0: *ast.Field {
121 . . . . . . . . . Doc: nil
122 . . . . . . . . . Names: nil
123 . . . . . . . . . Type: *ast.StarExpr {
124 . . . . . . . . . . Star: foo:15:2
125 . . . . . . . . . . X: *ast.SelectorExpr {
126 . . . . . . . . . . . X: *ast.Ident {
127 . . . . . . . . . . . . NamePos: foo:15:3
128 . . . . . . . . . . . . Name: "base_handler"
129 . . . . . . . . . . . . Obj: nil
130 . . . . . . . . . . . }
131 . . . . . . . . . . . Sel: *ast.Ident {
132 . . . . . . . . . . . . NamePos: foo:15:16
133 . . . . . . . . . . . . Name: "BaseHandler"
134 . . . . . . . . . . . . Obj: nil
135 . . . . . . . . . . . }
136 . . . . . . . . . . }
137 . . . . . . . . . }
138 . . . . . . . . . Tag: nil
139 . . . . . . . . . Comment: nil
140 . . . . . . . . }
141 . . . . . . . . 1: *ast.Field {
142 . . . . . . . . // ...
183 . . }
更改目标节点
观察上述 AST,可以发现 *ast.File 这个源文件节点下面,声明部分 Decls 就有 Handler 的声明语句。这个声明中有一个 Fields 节点,就是 Handler 的字段定义。
根据该 AST 可以很方便写出目标节点的识别代码,本文使用了 “golang.org/x/tools/go/ast/astutil” 这个库,相比于 “go/ast” 库,astutil 支持获取节点的父节点等功能。
func main() {
fset := token.NewFileSet()
file, err := parser.ParseFile(fset, "input.go", nil, parser.ParseComments)
if err != nil {
log.Fatal(err)
return
}
astutil.Apply(file, nil, func(c *astutil.Cursor) bool {
n := c.Node()
switch x := n.(type) {
case *ast.File:
for _, decl := range x.Decls {
if genDecl, ok := decl.(*ast.GenDecl); ok {
for _, spec := range genDecl.Specs {
switch dx := spec.(type) {
case *ast.TypeSpec:
// 下面判断是 type struct 声明,并且名称以 Handler 结尾
if dx.Name != nil && strings.HasSuffix(dx.Name.Name, "Handler") {
if stype, ok := dx.Type.(*ast.StructType); ok {
// checkIfAddBaseHandlerDone 判断是否已经插入过该 field
if !checkIfAddBaseHandlerDone(stype.Fields) {
// 在 fields.List 中插入 baseHandler 的 field
stype.Fields.List = append([]*ast.Field{newAddBaseHandlerField()}, stype.Fields.List...)
}
}
}
}
}
}
}
}
printer.Fprint(os.Stdout, fset, file)
}
func newAddBaseHandlerField() *ast.Field {
return &ast.Field{
Names: nil,
Type: &ast.StarExpr{
X: &ast.SelectorExpr{
X: &ast.Ident{
Name: "base_handler",
},
Sel: &ast.Ident{
Name: "BaseHandler",
},
},
},
}
}
expr
expr 自己实现了一套语法,因此也有自己的一整套编译过程。只不过得到了 AST 之后,转换为命令+参数的形式用栈来模拟程序的执行。
- 首先是 source code => token,使用状态机自底向上进行分析,expr/parser/lexer/lexer.go,下面是状态机的部分代码,当匹配到期望的规则时,则使用对应的生产规则跳转到下一个状态,因此是自顶向下分析,输出预设的 token 列表。
func root(l *lexer) stateFn {
switch r := l.next(); {
case r == eof:
l.emitEOF()
return nil
case IsSpace(r):
l.ignore()
return root
case r == '\'' || r == '"':
l.scanString(r)
str, err := unescape(l.word())
if err != nil {
l.error("%v", err)
}
l.emitValue(String, str)
case '0' <= r && r <= '9':
l.backup()
return number
default:
return l.error("unrecognized character: %#U", r)
}
return root
}
-
其次,token => AST,当 token 确定之后,可以很方便构建一棵树。个人觉得这部分代码写得有点挫,详细可以看:expr/parser/parser.go
-
下面是 AST => 程序命令的例子,三目的条件运算符的解析过程:expr/compile/compiler.go
func (c *compiler) ConditionalNode(node *ast.ConditionalNode) {
c.compile(node.Cond)
otherwise := c.emit(OpJumpIfFalse, c.placeholder()...)
c.emit(OpPop)
c.compile(node.Exp1)
end := c.emit(OpJump, c.placeholder()...)
c.patchJump(otherwise)
c.emit(OpPop)
c.compile(node.Exp2)
c.patchJump(end)
}
- 下面是执行函数的相关代码,expr/vm/vm.go,模拟了计算机取值、执行的过程。会将存在 bytecode 中的指令取出,并从 constant 中取出指令对应的参数进行执行。由于指令都是预设的,因此 constant 只需要根据预设进行出栈入栈即可。
op := vm.bytecode[vm.pp]
switch op {
case OpCall:
call := vm.constant().(Call)
in := make([]reflect.Value, call.Size)
for i := call.Size - 1; i >= 0; i-- {
param := vm.pop()
if param == nil && reflect.TypeOf(param) == nil {
// In case of nil value and nil type use this hack,
// otherwise reflect.Call will panic on zero value.
in[i] = reflect.ValueOf(¶m).Elem()
} else {
in[i] = reflect.ValueOf(param)
}
}
out := FetchFn(env, call.Name).Call(in)
if len(out) == 2 && out[1].Type() == errorType && !out[1].IsNil() {
return nil, out[1].Interface().(error)
}
vm.push(out[0].Interface())
}
gocover
go test coverage 采用的方法是在生成的 AST 上直接进行编辑,注入统计逻辑,然后根据编辑后的 AST 反向生成代码。